其實我沒打算要手刻一個k-nearest
所以這裡就來用用scikit-learn
你看看都幫我們寫好了~
針對近鄰算法,scikit-learn有一個class專門在做這個算法(連結),其中kNN的說明在這裡(連結)
數據來源會用scikit-learn附帶的datasets(連結),dataset的class(連結)
其實是第一次這麼詳細地看scikit-learn提供的資料庫,都好乾淨呀XD

以下用了幾個library:
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
from sklearn import datasets
from sklearn.model_selection import train_test_split #Split arrays or matrices into random train and test subsets
import matplotlib.pyplot as plt
iris = datasets.load_iris() #load進iris的資料庫
features = iris.feature_names
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) #test_size預設是0.25
k_range = range(1,10)
k_scores = []
for k in k_range:
neigh = KNeighborsClassifier(n_neighbors=k)
neigh.fit(X_train, y_train)
y_result = neigh.predict(X_test)
k_scores.append(accuracy_score(y_test, y_result))
print('neighbors: ', k, 'score: ', accuracy_score(y_test, y_result))
#畫圖畫出來
plt.plot(k_range,k_scores)
plt.xlabel('Value of K')
plt.ylabel('Accuracy')
plt.show()
準確率與K的圖: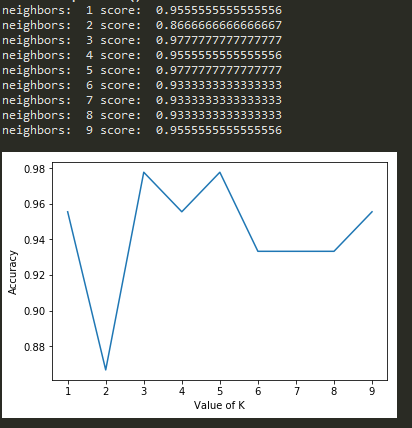
其實我一開始是拿scikit-learn的糖尿病資料做的,但是做出來準確率都很低,才想到他的target是常數XD這樣準確度高才奇怪XD


 iThome鐵人賽
iThome鐵人賽