Ref.: Representation
一直想不到最好的翻譯,Google一下找到資料科學協會說的:
機器學習分成三個主要部分:表現 (Representation)、最佳化 (Optimization)、評估 (Evaluation)。
這部分就是在說資料的表現,也正好是另一系列文章在講的,這邊只有一小小部分而已。
表現什麼呢?主要是因為我們原始資料大部分都需要再經過一些處理,才能變成Feature vector,而它則都是由float-point組成,透過處理weight才能有比較好的表現。Feature engineering就是這轉換過程。
# data ==> vector ['age', 'city', 'gender']
{ age: 12, street_name: 'Charleston Road', gender: 1 } ==> [12.0, 1.0, 2.0]
{ age: 21, street_name: 'North Shoreline Boulevard', gender: 0 } ==> [21.0, 2.0, 1.0]
數值資料 12 轉換成feature vector element很直覺,12 ==> 12.0,但非數值資料呢?假設我們的city包含 ['Charleston Road', 'North Shoreline Boulevard', 'Shorebird Way', 'Rengstorff Avenue'],這邊用全部可能的vocabulary轉換成數值,其他的(不在vocabulary內的,)都設定成另一個數字(OOV (out-of-vocabulary) bucket.),如下面的轉換:
假設房子在North Shoreline Boulevard & Rengstorff Avenue街角,就可以用這下面的表示方式:
vector = ['Charleston Road', 'North Shoreline Boulevard', 'Shorebird Way', 'Rengstorff Avenue']
= [0, , 1 , 1 , 0]
OK,這邊有個問題就是稀疏矩陣,有幾千條街,可是只靠在一條街上(大部分的房子都這樣):[0, 0,....., 1, 0,..., 0, 0]這樣。就可以參考稀疏矩陣表示法。
這邊講了幾個準則:
is_launched吧。city: 'taipei'很穩定, city: 0每個程式對city 0的定義很難一致。這邊介紹一些清理資料的方法,讓餵進去model的資料比較不會發散、比較有意義。
NaN,另一方面也不用處理太大的數值,同時還能很快收斂model。
Z-score可以把大部分的值mapping到 -3~3 之間
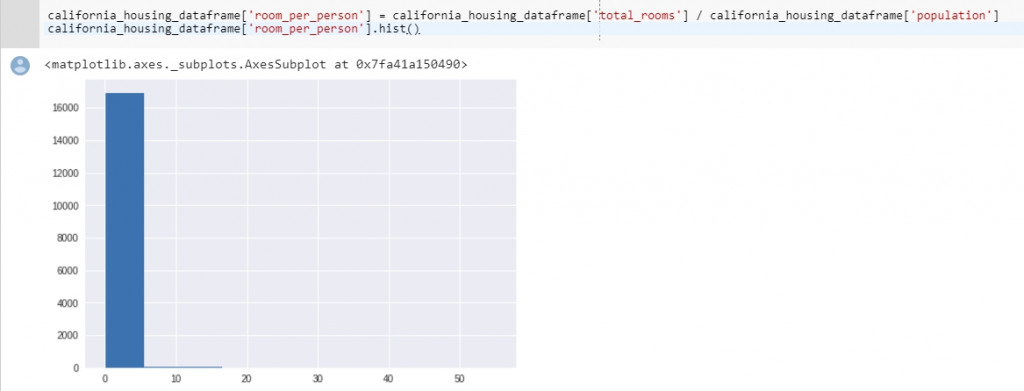
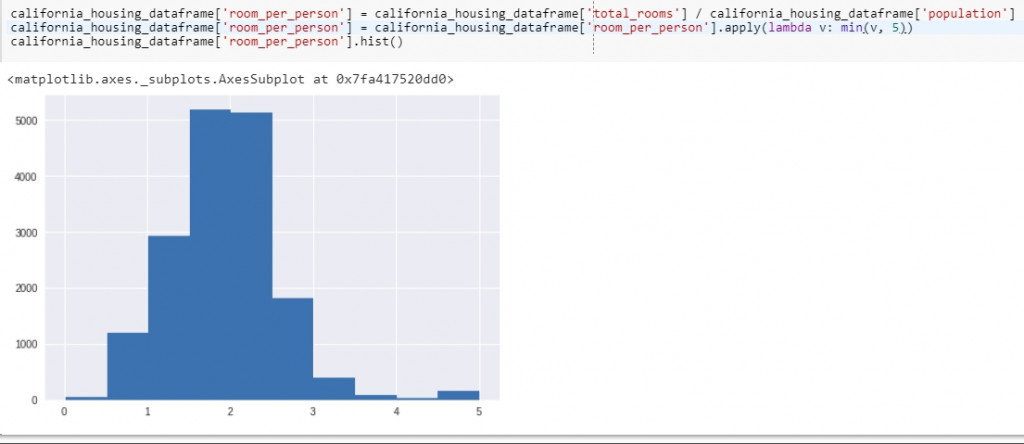

注意你的資料該長怎樣?資料是不是符合預期?不符合預期有沒有合理解釋?train data跟一些統計數據 or dashboard 有沒有一樣?
在Machine learning的過程就是有大部分的時間做出好的資料,否則garbage in garbage out,出來的Model你也不會滿意。
Good ML relies on good data.


 iThome鐵人賽
iThome鐵人賽