課前練習: Exam
Ref.: Validation
記得我們昨天講的Training set and test set,我們分成Training set 訓練model, 再用test set 測試model;效果不好的話再回去用training set訓練 model, 然後再用test set測試model;效果不好再試一次。每次每次的循環,讓test set過分暴露在眾目睽睽之下(這也是課前練習點出的問題)。
那怎麼辦?這邊多切了一個set: validation set。
Validation set
這邊要怎麼利用它呢? 我改了一下文章的圖,用流程圖說話: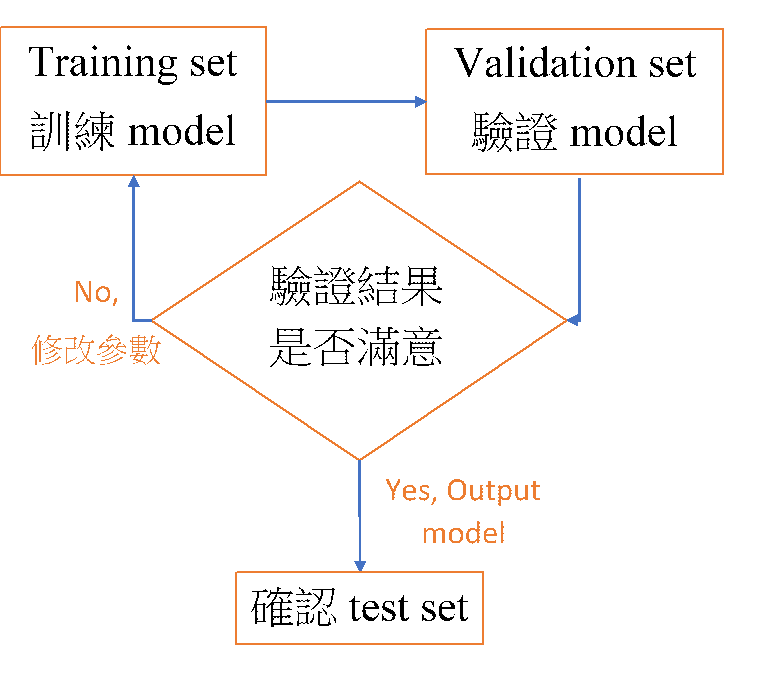
這樣子,我們的test set可以視為新的資料,不會暴露在model裡太多次。反而是validation set重複去驗證model,驗證過了才使用test set,test set就是double-check的效果。
課後練習: Programming exercise
練習的部分可以注意一下 Task 2: Plot Latitude/Longitude vs. Median House Value的部分,你可能一開始會得到下面的分布圖: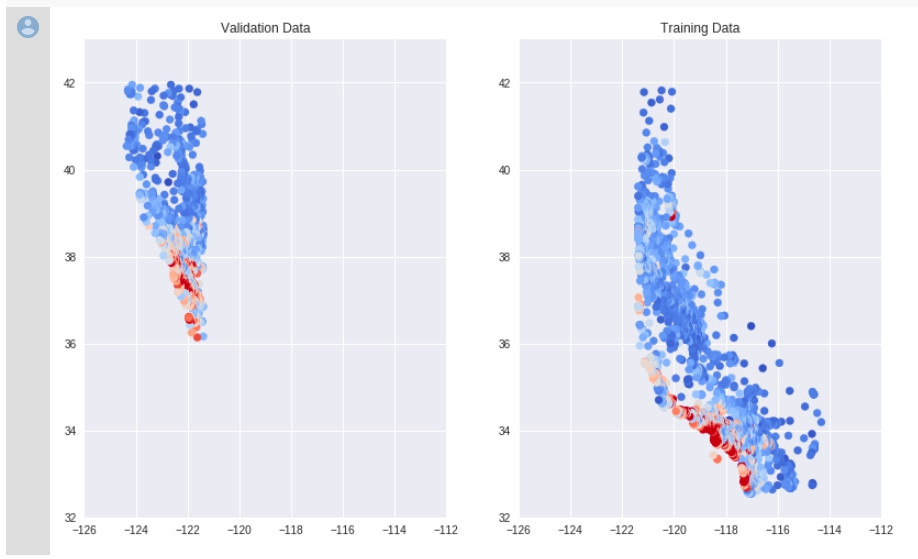
有看到嗎?緯度的部分差很多,地圖分布也完全不一樣。這說明了我們原始資料有一定程度的順序,才會有這種結果。
把第一段code兩個註解拿掉:
# california_housing_dataframe = california_housing_dataframe.reindex(
# np.random.permutation(california_housing_dataframe.index))
重跑一次,你就會看到會變成下面這樣: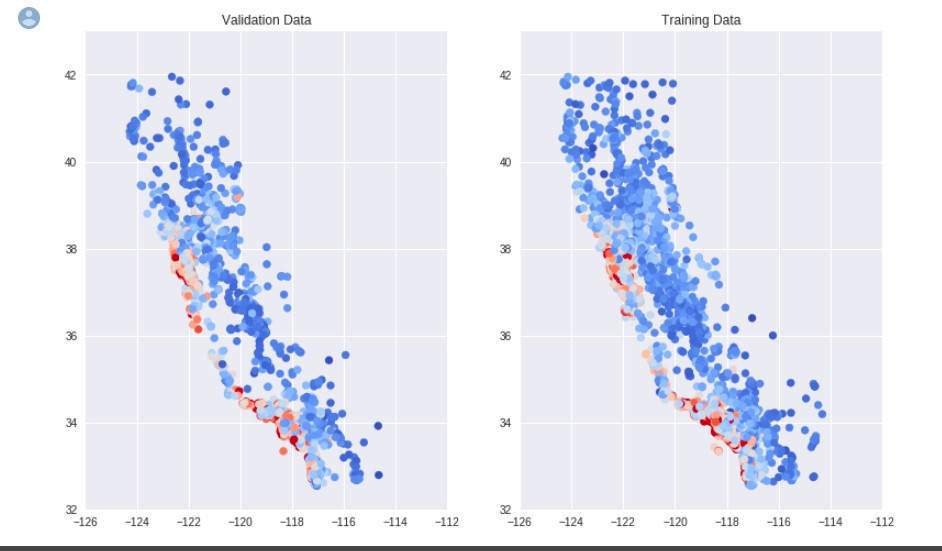
是不是一致多了?
之後的task 4, task 5都有解答,就不再特別複製貼上囉。


 iThome鐵人賽
iThome鐵人賽
{kind=link}