本篇發文是[改善資料品質]中的第二篇,面對缺漏值的對策。
處理資料時,資料科學家遇到的最常見問題之一是資料丟失問題。最常發生的情形是由於某種原因未獲取資料。例如:
90%的時間,資料集會有缺漏值的情形。現實世界中的物聯網設備例如:空氣品質測量器,在固定的時間會將其測量讀數吐出,經由網路的傳輸回到遠端伺服器的資料庫,假設部分物聯網設備在該時間點發生故障、或不能連網情形,則會造成資料庫中該時段的部分資料缺值。值得注意的是,當將學習算法應用於具有缺失值的資料時,大多數(並非所有)算法都無法應對缺失值。出於這個原因,資料科學家和機器學習工程師有很多關於如何處理這個問題的技巧和技巧,以下將會介紹主要的做法。
繼續使用titanic資料集,從讀取資料集開始:
import pandas as pd
import matplotlib.pyplot a plt
import seaborn as sns
%matplotlib inline
#各欄位的類型
column_types={'PassengerId':'category',
'Survived':'category',
'Pclass':int,
'Name':'category',
'Sex':'category',
'Age':float,
'SibSp':int,
'Parch':int,
'Fare':float,
'Cabin':'category',
'Embarked':'category'}
#讀取資料並且同時設置每個欄位的類型
data = pd.read_csv('data/train.csv', dtype=column_types)
首先我們可以使用pandas.DataFrame的方法info,對資料做快速的瀏覽,info方法列出每個欄位的資料類型以及無缺值的數目。但我們也可以使用其他方法來查看缺值的數目:
#使用isnull方法計算每個欄位的缺值
#並且用sum方法來做每個欄位總缺值數量的計算
#此方式與info相反,info計算無缺值的數目,此方法計算缺值數目
data.isnull().sum()
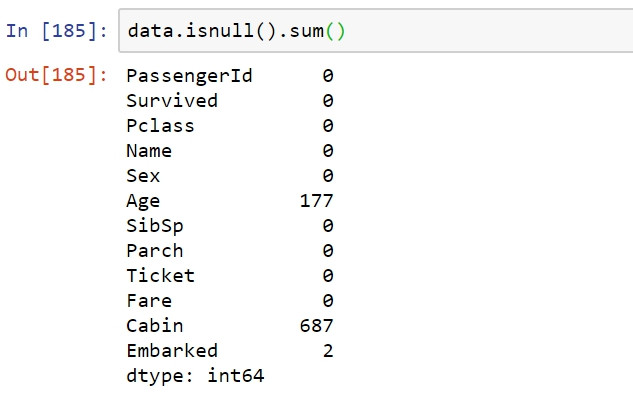
透過缺漏值的數量計算,總共有三個欄位有缺值,Age/Cabin/Embarked。
雖然方法論有很多種,但我們處理缺失數據的三種主要方式是:
當將學習算法應用於具有缺漏值的資料時,大多數(並非所有)算法都無法應對缺漏值。出於這個原因,最簡單的作法是丟棄資料缺漏的紀錄。
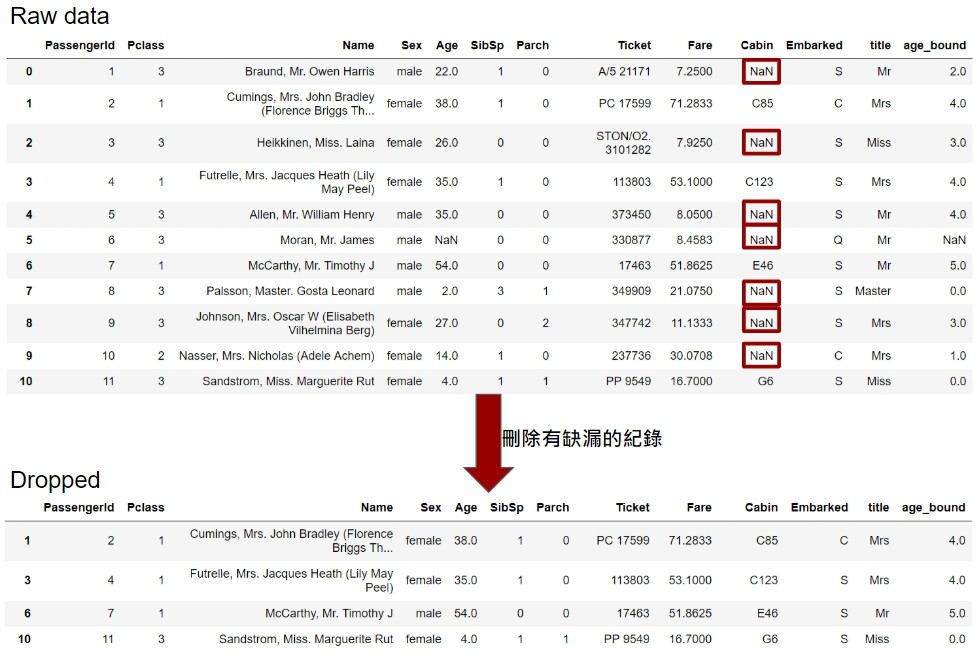
以下示範使用pandas丟棄缺漏的紀錄:
#使用pandas.Dataframe方法dropna移除所有缺漏值的紀錄
non_null_data = data.dropna()
print(r'總紀錄筆數:{}'.format(data.shape[0]))
print(r'刪除含缺漏紀錄資料後筆數:{}'.format(non_null_data.shape[0]))

有時選擇丟棄缺漏的紀錄會造成大量資料被棄用(在titanic中有80%的紀錄有所缺漏),但是資料當中蘊含著許多有用的欄位,因此我們應該盡可能的保留住每一筆紀錄。在此前提下的處理作法,可分為僅丟棄缺漏嚴重的欄位、填補缺漏的欄位。
titanic的範例,欄位Age缺漏177筆、Cabin缺漏687筆、Embarked缺漏2筆,由此可見多數的缺漏來自Cabin,其他資料大多健全,也因此若將其他欄位丟棄形同因噎廢食,更好的做法是僅捨棄缺漏嚴重的Cabin欄位(表徵)。
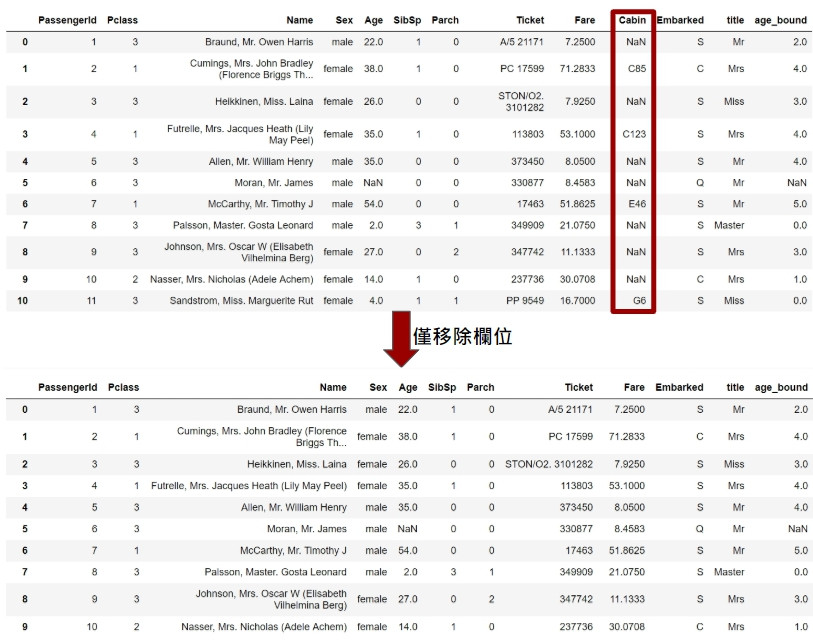
以下示範使用pandas丟棄缺失的紀錄:
#使用pandas.Dataframe方法dropna移除所有缺漏值的紀錄
data = data.drop(['Cabin'], axis=1)
移除缺漏的欄的作法通常被用在該欄位缺漏太過嚴重的狀況。原因是若執意補值可能喪失資料的自然性,反而降低資料的品質。
通常補值的方法可分為:
手動填值定量資料較常見的幾種做法:
#以該欄位所有資料的算術平均數做填補
data.Age.fillna(data.Age.mean())
#以該欄位所有資料的中位數做填補
data.Age.fillna(data.Age.median())
#以0填補
data.Age.fillna(0)
#以-999填補
data.Age.fillna(-999)
使用pandas.Dataframe方法fillna填補titanic資料中Cabin缺漏值的紀錄:
#查看出現最高頻率的值
print(data.Carbin.value_counts())
# output
C23 C25 C27 6
G6 5
B57 B59 B63 B66 5
C78 4
F4 4
F33 4
#全部缺值用出現頻率最高的"C23 C25 C27"填入
data.Carbin = data.Carbin.fillna("C23 C25 C27")
插值法則較常用於時間及空間的資料上,是利用己知的二組數據,來求出二組數據的「中間值」。
案例:已知台中及彰化目前的室外溫度,介於兩地中間的南投有缺值,可透過台中與彰化的資料做插值法計算南投的空氣汙染數值。
#虛擬的中部室外溫度資料
#南投地區為缺值,以內插法來補值
temp_data = pd.DataFrame([['台中', 24.8],
['南投', None],
['彰化', 25]],
columns=['city', 'current_temp'])
#打印資料
print(pollution_data)
#output
city current_temp
0 台中 24.8
1 南投 NaN
2 彰化 25.0
#以dataframe的interpolate方法做插值並打印
pollution_data.interpolate()
#output
city current_temp
0 台中 24.8
1 南投 24.9
2 彰化 25.0

