有時,我們也許會想將連續的數值資料轉換為分類資料。例如,titanic資料中Age欄位,我們可以將年齡這樣連續性的數值資料編碼成範圍;0-15兒童/15-30青年/30-45中年/45-60壯年/60-75+老年...等等。 pandas有一個名為cut的有用函數,可以為我們處理這樣的任務。通過設置,我們得以將資料平均切分成N個範圍,並且賦予每個範圍特定的標籤。
import re
from functools import partial
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
%matplotlib inline
#各欄位的資料類型
column_types={'PassengerId':'category',
'Survived':int,
'Pclass':int,
'Name':'category',
'Sex':'category',
'Age':float,
'SibSp':int,
'Parch':int,
'Fare':float,
'Cabin':'object',
'Embarked':'category'}
#訓練集
train_set = pd.read_csv('data/train.csv', dtype=column_types)
#測試集
test_set = pd.read_csv('data/test.csv', dtype=column_types)
# merged = train_set
DATASET = pd.concat([train_set, test_set])
pandas的cut函數的參數為欲切割的連續數字資料,bins參數為切分的總級數,labels定義各個切分級數的標籤,則此函數會將目標資料從小到大以一定間格切分出N個區段。
#將年齡切分成五個等級
age_range = ['ChildHood', 'Teens', 'YoungAdulthood', 'MiddleAge', 'OldAge']
pd.cut(dataset.Age, bins=len(age_range))
上面的code會將年齡資料依照bins的數量切分成5個等級,如果並未給予此函數labels的參數,則默認標籤會以數值的範圍呈現。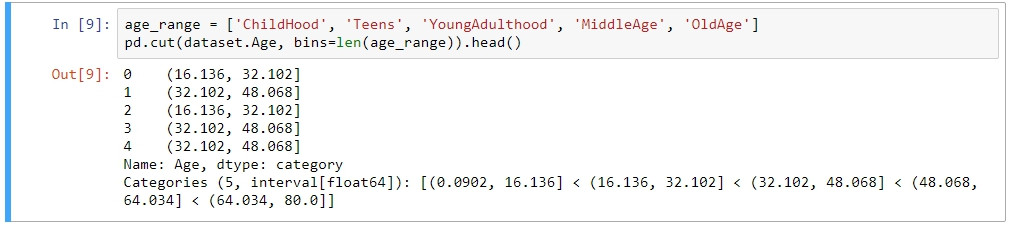
如果有給予labels參數則結果就是各個年齡層的稱謂:
#將年齡切分成五個等級
age_range = ['ChildHood', 'Teens', 'YoungAdulthood', 'MiddleAge', 'OldAge']
pd.cut(dataset.Age, bins=len(age_range), labels=age_range)

上面演示了此函數的使用方式,但是注意labels有點太不講究,以五個標籤來代表全年齡層的各個年紀範圍有點太陽春。因為年齡資料的範圍為0-80歲,僅以五個年齡標籤代表全年齡是太缺乏細節的做法(0-16歲都被稱作ChildHood,16-32歲被稱為Teens)。因此bins的數量以及labels要先定義好適當的數值。以下是年齡分布的觀察以及一張定義較嚴格的年齡範圍的稱謂,大約以6年做一個區間,可供我們參考bins的數量設置:

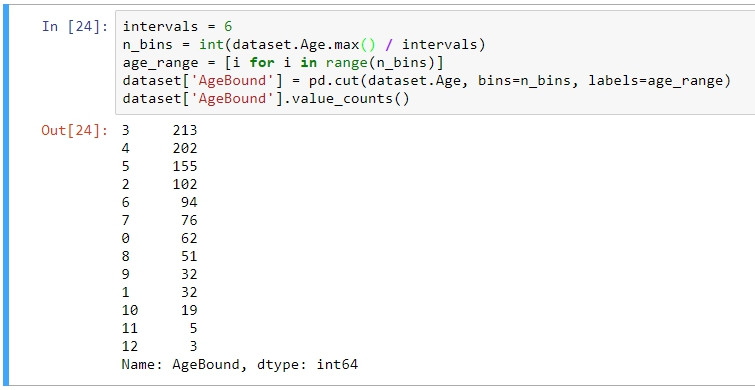
#將年齡以6歲的間格切開
intervals = 6
n_bins = int(dataset.Age.max() / intervals)
age_range = range(n_bins)
dataset['AgeBound'] = pd.cut(dataset.Age, bins=n_bins, labels=age_range)
dataset['AgeBound'].value_counts()
再搭配前章節所提到的虛擬變量編碼的,就每個年齡階段都獨立成為一欄位了:

