我們如何讓機器學習算法來使用類別資料或說名目尺度的資料?簡單地說,我們需要將這些分類的資料轉換成數字類型的資料。任何機器學習算法,無論是線性回歸還是利用KNN的歐式距離,都需要輸入數字表徵來學習。我們可以依靠幾種方法將類別資料轉換為數字資料。今天將討論的是將名目尺度的資料轉換為數字資料,我們可以利用pandas dataframe的方法來幫助我們自動執行這樣的任務。但在貼入細節之前,首先我們需要了解一下虛擬變量(dummy variable)。
虛擬變量的值為0或1,表示類別資料的是或否。titanic資料中的Survived(生存)欄位就是一虛擬變量,0表示死亡、1表示生存。將名目尺度的資料用數字來表示的主要原因是機器學習的限制,但也帶來了好處;因為被轉為數值了,要觀察名目尺度資料以及其他欄位間的關連也變的可能,還記得前面幾章有提到過的線性關聯性表(corr)嗎,正因為數值型資料之間才能夠查看線性關聯,也因此我們只有將生存與死亡這樣原本為名目尺度的資料欄位處理成0和1的數值資料才能進一步分析(可將Survived看成原本是用survived以及dead表示的名義尺度資料)。
使用虛擬變量時,重要的是要注意並避免虛擬變量陷阱。虛擬變量陷阱是指具有高度相關的獨立變量。或者說,這些變量可以推敲彼此。例如,如果我們將titanic資料中的性別欄位做成男性與女性兩個虛擬變量,男性的虛擬變量用0代表女性、1代表男性,女性的虛擬變量用1代表女性、0代表男性。男性與女性兩個虛擬變量具有高度關聯,甚至可以僅用一個虛擬變量來表示,這就是陷入了虛擬變量的陷阱。
讓我們回到titanic資料集並使用一些方法將我們的類別類型的資料編碼為虛擬變量
import re
from functools import partial
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
%matplotlib inline
#各欄位的資料類型
column_types={'PassengerId':'category',
'Survived':int,
'Pclass':int,
'Name':'category',
'Sex':'category',
'Age':float,
'SibSp':int,
'Parch':int,
'Fare':float,
'Cabin':'object',
'Embarked':'category'}
#訓練集
train_set = pd.read_csv('data/train.csv', dtype=column_types)
#測試集
test_set = pd.read_csv('data/test.csv', dtype=column_types)
# merged = train_set
DATASET = pd.concat([train_set, test_set])
pandas有一個方便的get_dummies方法,它自動為我們找到了所有的分類變量編碼為虛擬變量。
#將所有類別類型欄位編碼為虛擬變量
dummies_encoded = pd.get_dummies(DATASET)
#看前五筆資料
dummies_encoded.head()
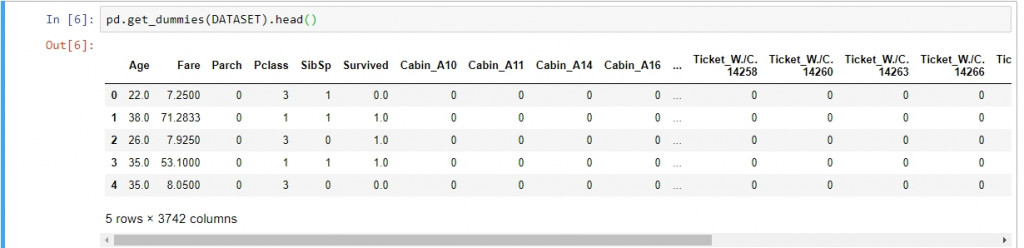
原本僅8個欄位的資料突然變成了3742個欄位,what the.....。注意上面提到的"pandas自動為我們找到了所有的分類變量編碼為虛擬變量",這句話代表的是pandas會針對欄位類行為category的資料進行編碼。在資料中為category的欄位為Name/Sex/Embarked/Ticket,如果我們查看過便會發現名字欄位就有1307個完全不同的值。
這代表Name欄位會被編碼為1307個新欄位,每個欄位代表是否為某個特定名字的虛擬變量。如上圖中第一筆名字紀錄Connolly, Miss. Kate就會被編碼成為一個虛擬變量,以0代表不是Connolly, Miss. Kate,而1是,言下之意所有的名字都會經歷一樣的過程被編碼成新的虛擬變數。另外更不妙的是我們也不知不覺的踩進了虛擬變量陷阱,因為過去我們將Sex欄位預設為category類型的資料,如果使用get_dummies方法,則Sex欄位會被作成兩個虛擬變數,男性與女性兩個高度關聯的虛擬變數。這不代表過去我們將部分欄位設定為categpry類型是錯誤的,因為一開始的目的是讓我們一目了然各個資料欄位的含意。因此如果要使用get_dummies來處理整個資料集以前,特別應該再將資料處理過才使用。
#clone原始資料集 用來作虛擬變量的編碼
DATASET_for_dummies_encoding = DATASET.copy()
#clone原始資料集 將Sex欄位處理成一個虛擬變數 IsMale 作為是否為男性的欄位
DATASET_for_dummies_encoding['IsMale'] = DATASET_for_dummies_encoding.Sex.apply(lambda sex:1
if sex == 'male' else 0).astype(int)
#丟棄所有不需要的category類別欄位 避免不必要的編碼
DATASET_for_dummies_encoding = DATASET_for_dummies_encoding.drop(['Name', 'Ticket', 'Sex', 'Cabin', 'PassengerId'], axis=1)
#顯示編碼後的特徵關聯表
plt.figure(figsize=(10, 8))
sns.heatmap(DATASET_for_dummies_encoded.corr(), annot=True)
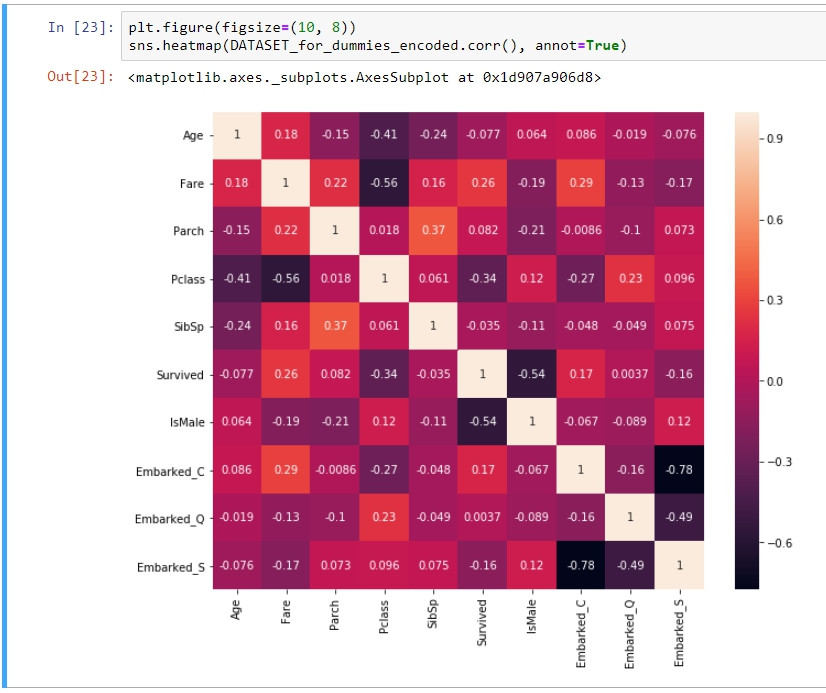
可以看到,Emarked欄位已經被編碼為三個虛擬變量,分別代表三個港口上船與否的欄位。而過去我們沒辦法透過關聯圖顯示名目尺度資料與其他欄位的關聯性的問題也連帶被解決了。
此篇介紹了虛擬變量,其在許多流程中扮演相盪重要的角色,如EDA的過程中賦予我們對名目尺度資料與其他數值欄位的關聯性觀測可能變是一環。但應注意處理資料用起來才心應手。

