FastText是臉書釋出的開源AI函式庫,它整合自然語言處理和機器學習技術,可處理文字分類和學習單詞向量表示
iThome 報導:https://www.ithome.com.tw/news/107845
函式下載:https://fasttext.cc/
$ git clone https://github.com/facebookresearch/fastText.git
$ cd fastText
$ make
建立文本表現模型(word representation)
Data.txt裡面放入上一篇用的PTT文本資料集 (是經過segmentation後的txt檔喔)
$ ./fasttext skipgram -input data.txt -output model
訓練完模型後,使用
$ ./fasttext nn model.bin
在Query word?問題後輸入想要查詢的詞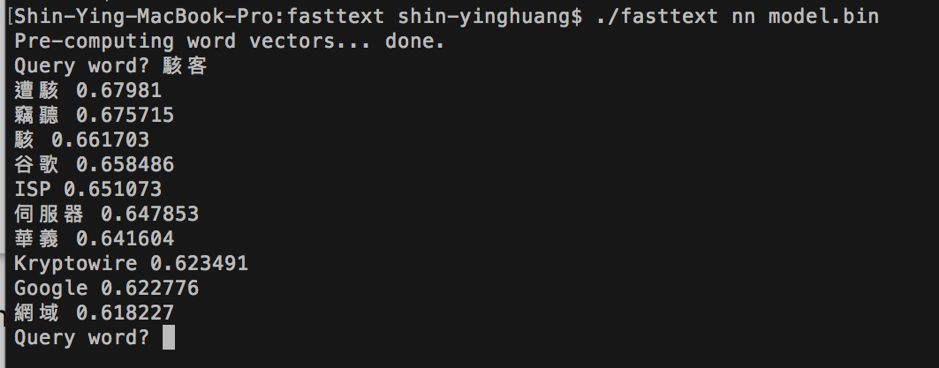
例如輸入駭客,便可得到相關類似的詞彙
輸入空污,得到的相似字效果也不錯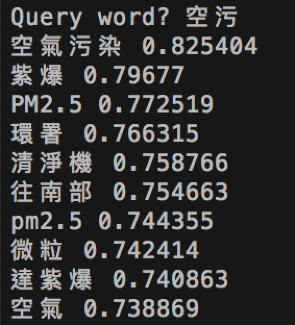
輸入證照,也能得到相關的熱門議題關鍵字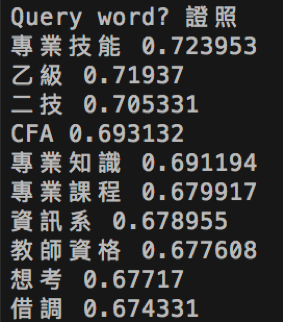
接下來是是同義詞功能
./fasttext analogies model.bin
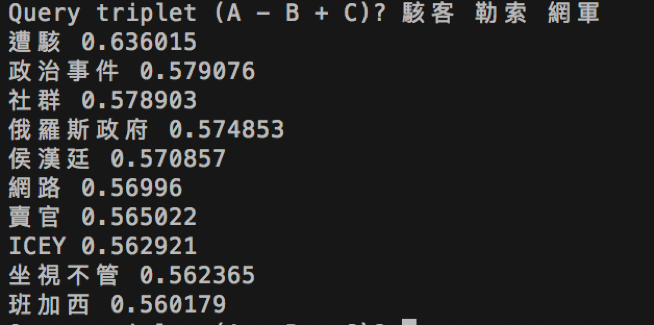
結果輸出類似的詞彙,可能跟當時(2016年)的時事有關
fastText的模型結構是由聯合向量層(joint embedding layer)和softmax分類器組成,原理是把句子中所有的詞向量進行平均(某種意義上可以理解為只有一個avg pooling特殊CNN),然後直接接入softmax 層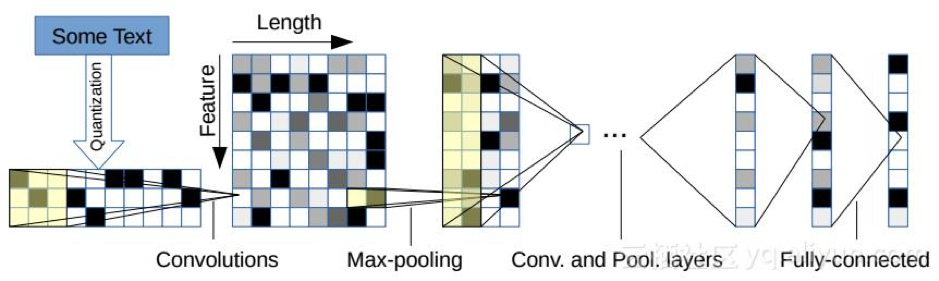
參考網址:https://kknews.cc/zh-tw/tech/e8gn22q.html
FastText模型架構圖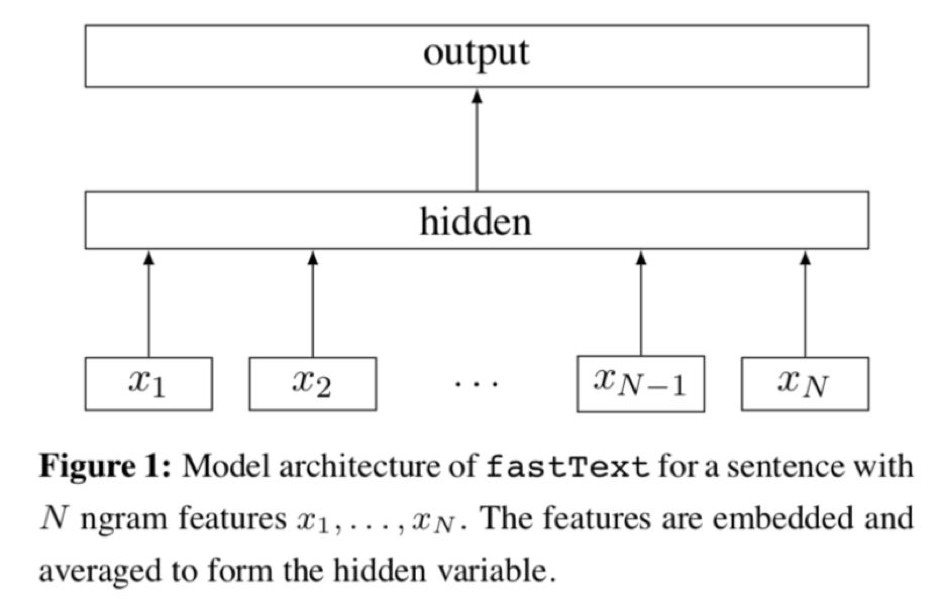
Continuous Bag of Words (CBOW)模型會採用Softmax作爲輸出,而fastText則採用了Hierarchical Softmax,層次化的Softmax的思想實質上是將一個全局多分類的問題,轉化成爲了若干個二元分類問題,從而將計算複雜度從O(V)降到O(logV),因而降低了模型訓練時間。


 iThome鐵人賽
iThome鐵人賽