問題定義:視為一種文本分類的問題
作者提出的方法: 使用Naïve Bayes
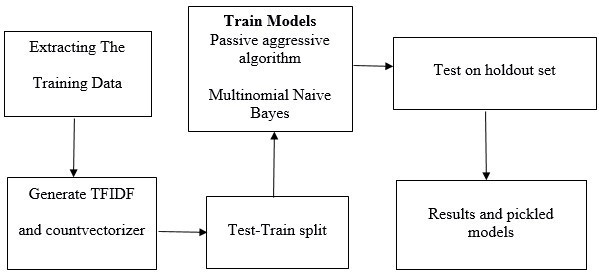
資料來源:Kaggle challenge, 13,000筆2016年資料
Sci-kit Learn GridSearch執行效果最好,2-gram處理,support頻率:3次
語言分析可以判斷的特徵包含:文法結構、文字選擇、標點符號、複雜度
作者發文的時間也是會偵測常用的特徵
挑戰:以NLP統計詞的頻率,或是tfidf的處理,是無法理解到詞的前後關係的。
為了產生良好的模型,具備優良的訓練資料會是一個挑戰。因此往往需要自己建立fake news樣本。
除了其他想法:觀測情緒極端程度、短期發文較前前期發文量統計、帳號年齡、帳號發文時間、發文間格時間、圖片特徵、熱門程度(轉貼數)、作者朋友圈
參考來源
Fake News Detection using Machine Learning
https://www.pantechsolutions.net/machine-learning-projects/fake-news-detection-using-machine-learning
Fake news detector algorithm works better than a human
https://news.umich.edu/fake-news-detector-algorithm-works-better-than-a-human/


 iThome鐵人賽
iThome鐵人賽