電腦只看得懂 0 和 1,現在所有的程式語言 ASM、C++、C#、Python,等等...最終都會經過編譯或直譯轉換成機器碼 CPU 才能執行,現在雖然有很多的高階語言,但電腦真正能看懂的還是只有機器語言,就連最接近的組合語言都不行。
機器碼片段:
00011110
101110000000000000000000
01010000
101110001100011000001111
1000111011011000
因為機器語言都是的 0 和 1 不便於人類記憶,所以後來發明了組合語言,組合語言的指令皆採用縮寫的英文單字,比起機器語言更易於記憶和撰寫,雖然還是艱澀難懂,但比起機器碼已經好理解許多,真佩服以前的工程師,可以用機器語言寫程式。
組合語言片段:
mov ax, 2 ; 將 2 移動到 ax 暫存器
對破解有興趣的朋友,一定有聽過反組譯,但為什麼常聽到的反組譯都是將機器碼還原成組合語言,而不是 C 語言或其他高階語言呢,原因是 組合語言 和 機器碼 是可以 一對一對應 的,而像 C 等其他語言經過編譯後一行程式可能會變成多條機器指令,所以才無法反組譯,其實還是可以拉,不過會和原始碼差非常多。這裡指的是對機器碼反組譯,而不是 C#、JAVA 等編譯後產生的 中間碼。[1]
存儲器是可供 CPU 存取操作具有保存訊息功能的設備,記憶體就最常見的存儲器,其他還包括顯示卡、網卡、BIOS 等等,CPU 要和存儲器溝通必須透過三類的訊息交換。
CPU 想要將資料寫入記憶體,必需先知道記憶體的地址,接著告訴記憶體要進行寫入的操作,最後把資料送過去,以上為 CPU 對存儲器操作的大致流程。
CPU 和存儲器之間透過總線相連,總線可分為三類,分別對應上面的三類訊息。
CPU 如何將數據 10 寫入記憶體地址 5 的地方。
示意圖:
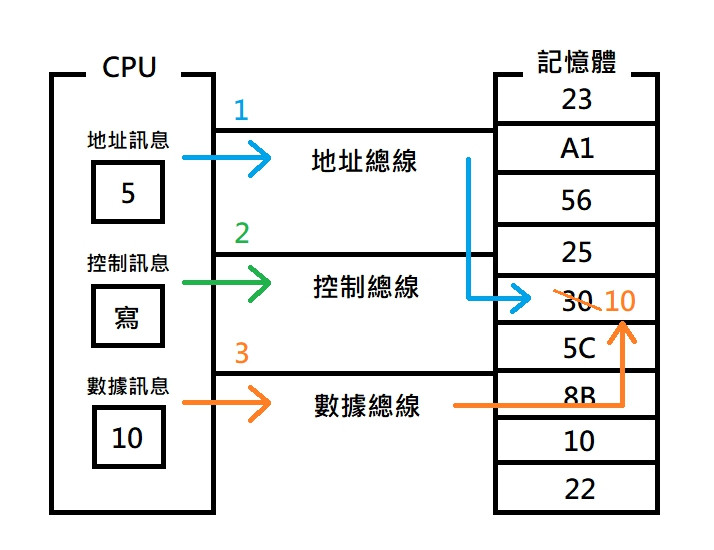
為什麼需要三類總線呢? 試想如果 CPU 和存儲器間只有一條總線相連,因為在電腦中傳遞的訊息都是 0 和 1 的二進制數據,那該如何區別是 地址、控制 還是 數據 呢,因此發明了三類總線,透過不同的總線就能將三者區分開來。
在電腦中儲存的都是二進制訊息,CPU 是如何區別程式指令和數據資料呢? 其實 CPU 是無法區別的,對於 CPU 而言兩者並無區別,將其當成指令或數據是由程式設計者決定的,之後會介紹我們在寫程式時會將程式分成不同的區段,代碼段存放指令,數據段存放數據,如果不小心把程式入口指到數據段,CPU 還是會乖乖的將那些數據當成指令執行,並無法辨認那些執行的指令其實是數據。
1000 1011 1100 0011
例如上面這段二進制訊息,CPU 可以當成數據 8BC3,也可以當成指令 MOV AX,BX。
CPU 如何不錯將數據當成指令執行?
在記憶體中某個地址會被規定為 起始地址 或稱 復位地址,電腦開機後 CPU 會跳轉到該地址,並將內容當成指令執行,接著就可以透過指令的長度和格式去判斷下一條指令的位置。而程式中組合語言有兩個暫存器 CS (指令段暫存器) 和 DS (數據段暫存器),可以根據 CS 和 DS 指向的地址,將內容當成指令或數據。[3]
因此只要 CPU 從起始地址開始執行指令,並不斷執行下去,除非程式寫錯,不然永遠不會錯將數據當成指令。
尋址能力是指 CPU 能定位到的最大記憶體地址,這取決於地址總線的寬度,例如 16 根地址總線,可以定位 2 的 16 次方大小的地址,32 根可以定位 2 的 32 次方,n 根地址總線可以擁有 2 的 n 次方 的尋址能力,常聽到的 32 位、64 位 CPU 指的就是 CPU 的尋址能力。
下一篇會介紹記憶體空間和第一次的反組譯,今天就到這裡摟,感謝大家觀看。
[1] 光明與黑暗 – 談程式碼保護
[2] register based 和 stack based虚拟机的区别
[3] CPU如何区分读出的代码是指令还是数据
期待大大的 反組譯 文章 
感謝暐翰大~ 不過這樣講我壓力很大。 
光速學習中(⁎⁍̴̛ᴗ⁍̴̛⁎)
♐️1111014(五)0232


 iThome鐵人賽
iThome鐵人賽