在上一篇文章(Day4-輕鬆駕馭數據part2)中,介紹陣列型態的資料,透過DataFrame的方法,將資料做整理、篩選、刪除...操作。今天要來持續介紹Pandas的功能,缺失值的處理(Handling Missing Data)
在數據蒐集時,並不是每一資料屬性都能蒐集到(通常在會呈現:null、NaN、NA值),因此,我們在做資料處理時,我們要先把資料做標準化整理。
import nupmy as np
import pandas as pd
建立一個陣列,其中包含缺失值,並運算陣列值的總和。
value = np.array([1, None, 3, 4])
value.sum()

None在資料陣列,是一非數值型態的資料,因此不能做加總運算。
value2 = np.array([1, np.nan, 3, 4])
value2.dtype
dtype('float64')
value2.sum(), value2.min(), value2.max()
(nan, nan, nan)
nan為資料型態float,但是數值未明確定義,所以在做統計資料(例如:找出最大值、最小值或加總),會輸出皆為nana的錯誤結果
若是要排除nan值,做統計處理。
np.nansum(value2), np.nanmin(value2), np.nanmax(value2)
因為nan為float資料型態,所以運算出的結果亦為資料型態float。
下表為各種缺失值在Pandas上的轉換:
| Typeclass | Conversion When Storing NAs | NA Sentinel Value |
|---|---|---|
| floating | No change | np.nan |
| object | No change | None or np.nan |
| integer | Cast to float64 | np.nan |
| boolean | Cast to object | None or np.nan |
data = pd.Series([1, np.nan, 'abc', None])
data.isnull()
0 False
1 True
2 False
3 True
dtype: bool
判斷每一資料值不為null
data = pd.Series([1, np.nan, 'abc', None])
data.notnull()
0 True
1 False
2 True
3 False
dtype: bool
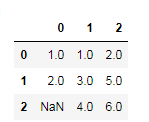
df = pd.DataFrame([[1, np.nan, 2],
[2, 3, 5],
[np.nan, 4, 6]])
df
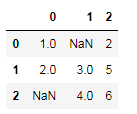
df.dropna()
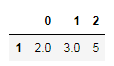
df.dropna(axis='columns')

df.dropna(axis='columns', how='all')
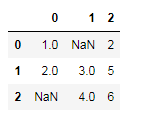
df.dropna(axis='columns', how='any')

data = pd.Series([1, np.nan, 2, None, 3], index=list('abcde'))
data
data.fillna(0)
data.fillna(method='bfill')

df = pd.DataFrame([[1, np.nan, 2],
[2, 3, 5],
[np.nan, 4, 6]])
df.fillna(method='ffill', axis=1)