在昨天介紹自然語言處理時,利用word embedding方法,已經將資料預處理完成,今天要來建立多層感知器MLP模型,其步驟如下:
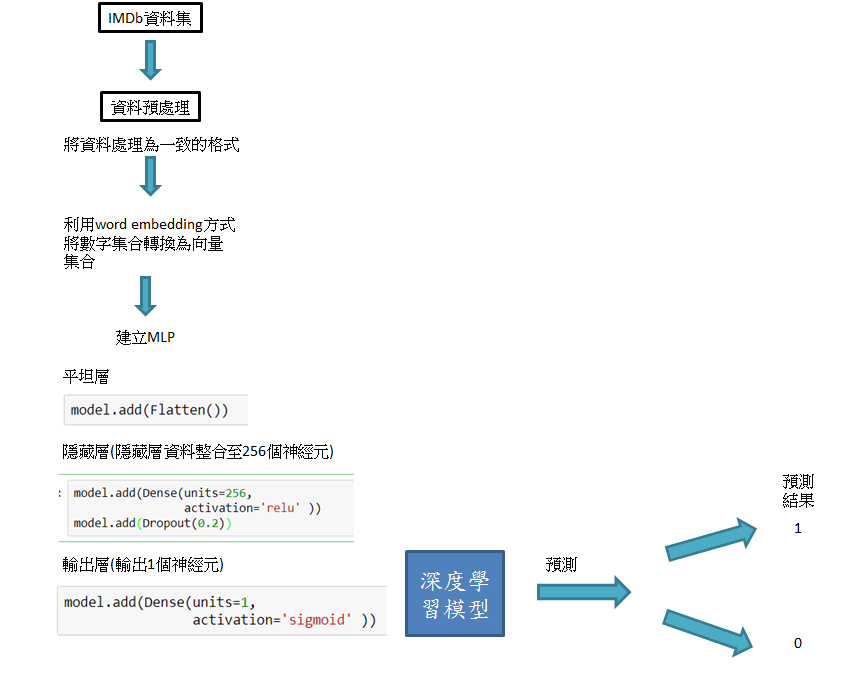
完成前一天的資料處理,建立模型,加入emdedding將資料預處理後的數字集合轉換為向量集合
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation,Flatten
from keras.layers.embeddings import Embedding
model = Sequential()
model.add(Embedding(output_dim=32,
input_dim=2000,
input_length=100))
model.add(Dropout(0.2))
再來,如上圖步驟建立多層感知器MLP模型
model.add(Flatten())
model.add(Dense(units=256,
activation='relu' ))
model.add(Dropout(0.2))
model.add(Dense(units=1,
activation='sigmoid' ))
model.summary()

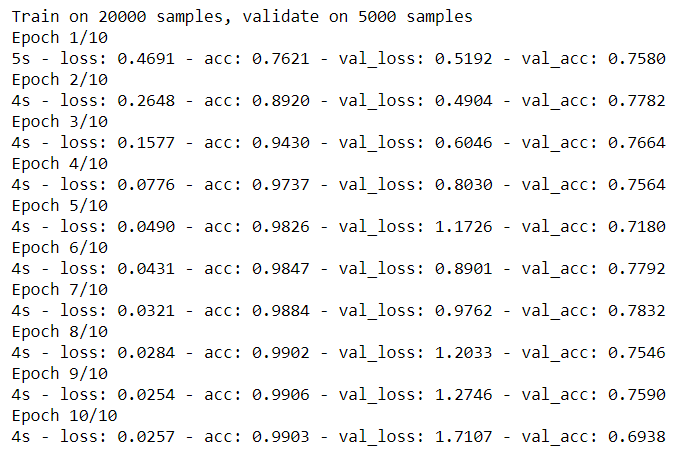
利用反向演算法訓練模型
model.compile(loss='binary_crossentropy',metrics=['accuracy'])
#進行訓練
#batch_size:每一批次訓練100筆資料
#epochs:執行10個訓練週期
#verbose:顯示每次的訓練過程
#validation_split:測試資料的比例
train_history =model.fit(x_train, y_train,batch_size=100,
epochs=10,verbose=2,validation_split=0.25)
#評估訓練模型的準確率
acu = model.evaluate(x_test, y_test, verbose=1)
acu[1]