很多線上社群網站會蒐集使用者的資料,並且分析使用者行為,像是知名的Facebook在前幾年開始做「情緒分析(sentiment analysis)」,它是以文字分析、自然語言處理NLP的方法,找出使用者的評價、情緒,進而預測出使用者行為來進行商業決策,像這樣一連串利用情緒分析帶來的商業價值是相當可觀的。而今天以IMDb網路電影影評資料集作範例。
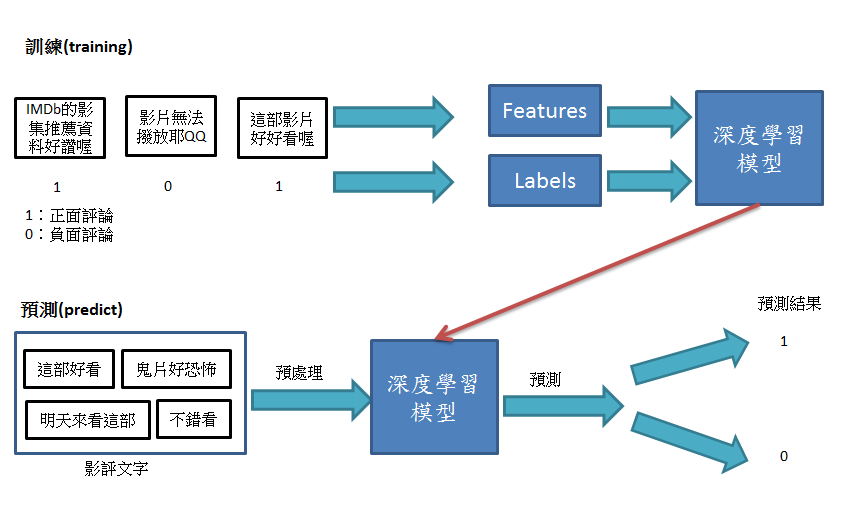
在之前有講解到,建立一個模型,要有大量的訓練(training)後來做預測(predict),如下圖,在訓練時蒐集正反兩面的資料的特徵值及屬性來建立深度學習模型,再利用預測資料將資料做預處理找出特徵值,透過實作完成的深度學習模式做預測,並且計算出預測結果與真實值得差異,計算出建立完成的深度學習模型的準確值如何。
import urllib.request
import os
import tarfile
url="http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
filepath="IMDb/aclImdb_v1.tar.gz"
if not os.path.isfile(filepath):
result=urllib.request.urlretrieve(url,filepath)
print('downloaded:',result)
from keras.datasets import imdb
from keras.preprocessing import sequence
from keras.preprocessing.text import Tokenizer
#將html的標籤刪除
import re
def rm_htmltags(text):
re_tag = re.compile(r'<[^>]+>')
return re_tag.sub('', text)
#讀取IMDb的檔案目錄
import os
def read_files(filetype):
path = "IMDb/aclImdb/"
file_list=[]
positive_path=path + filetype+"/pos/"
for f in os.listdir(positive_path):
file_list+=[positive_path+f]
negative_path=path + filetype+"/neg/"
for f in os.listdir(negative_path):
file_list+=[negative_path+f]
print('read',filetype, 'files:',len(file_list))
all_labels = ([1] * 12500 + [0] * 12500)
all_texts = []
for fi in file_list:
with open(fi,encoding='utf8') as file_input:
all_texts += [rm_tags(" ".join(file_input.readlines()))]
return all_labels,all_texts
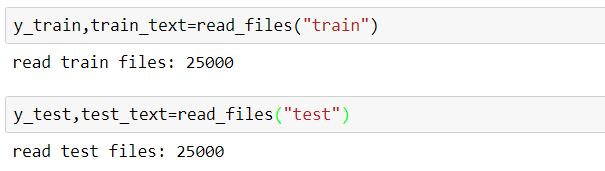
#查看IMDb的檔案目錄
#先讀取所有文章建立dic,限制dic數量為nb_words=2500
token = Tokenizer(num_words=2500)
token.fit_on_texts(train_text)
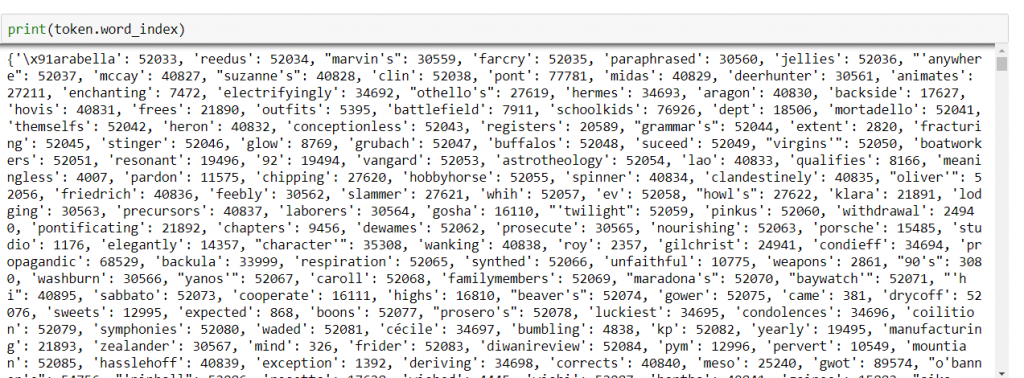
#查看文字index的屬性