在開發上,Redash 有不少功能可以加快我們速度:
當你有類似的 SQL,可能是同個資料源但撈出的欄位要做些更動,或是差不多的句法,只是有不同資料源頭、
又亦或是看到一個很不錯的 Query ,想要複製一份然後修改客製成自己的樣貌,這些都可以用 Fork 來幫忙。
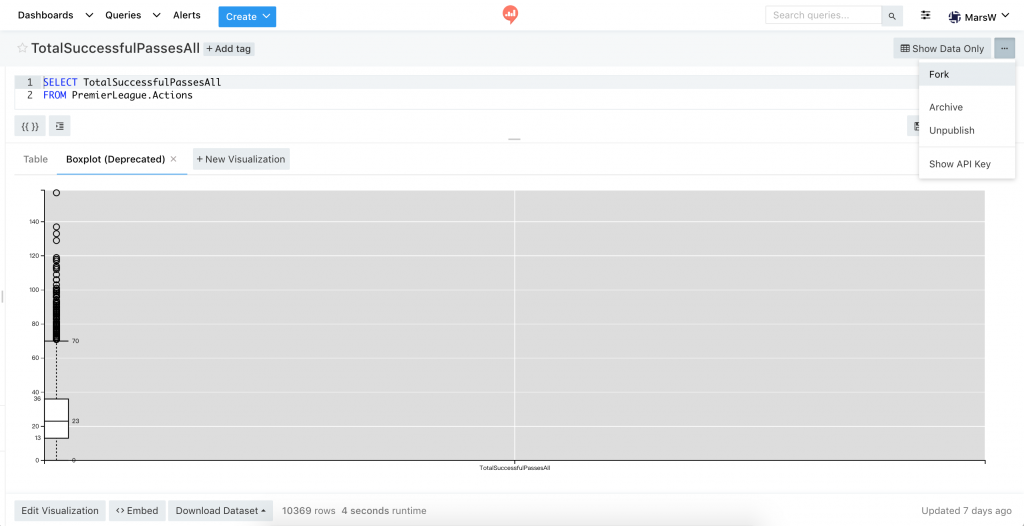
Fork 的按鈕在 Show Data Only / Edit Source 旁的更多功能選單中,
按下之後會產生一個一模一樣 Query,同時包含著原 Query 中所有的 Visualization,
名稱預設是「Copy of (#原 QUERY_ID ) 原 Query 名稱」。
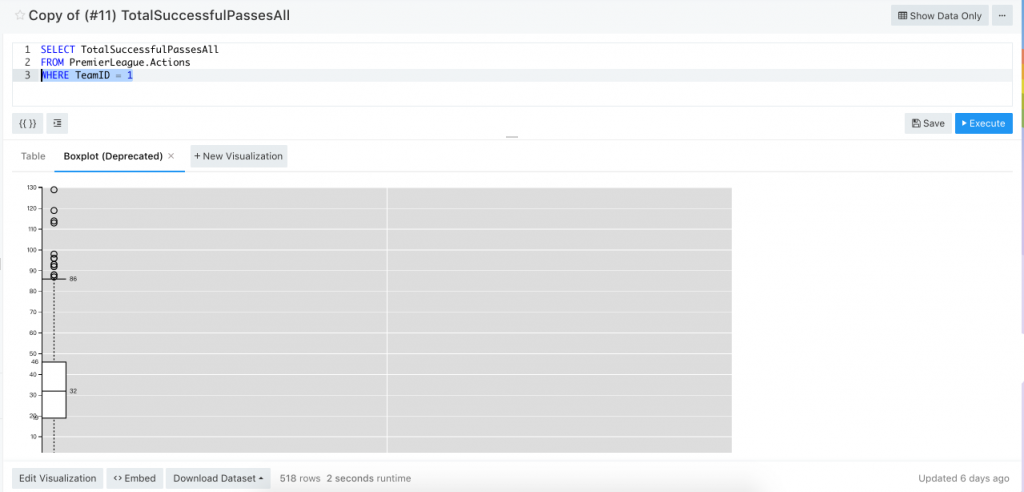
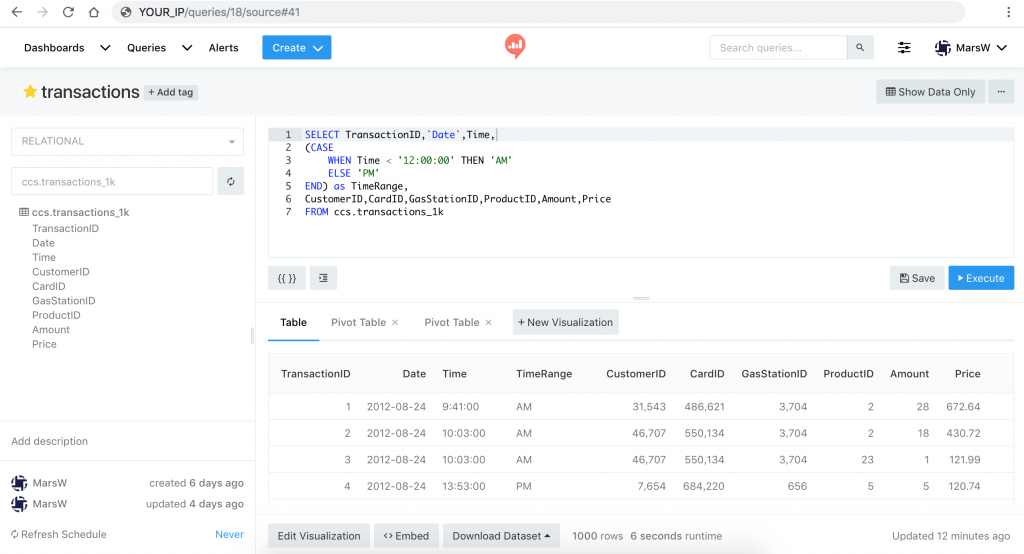
QUERY_ID 是網址 queries 後面的數字
eg.YOUR_IP/queries/18/source#41的 QUERY_ID 是 18 (41是 Visualization 編號)
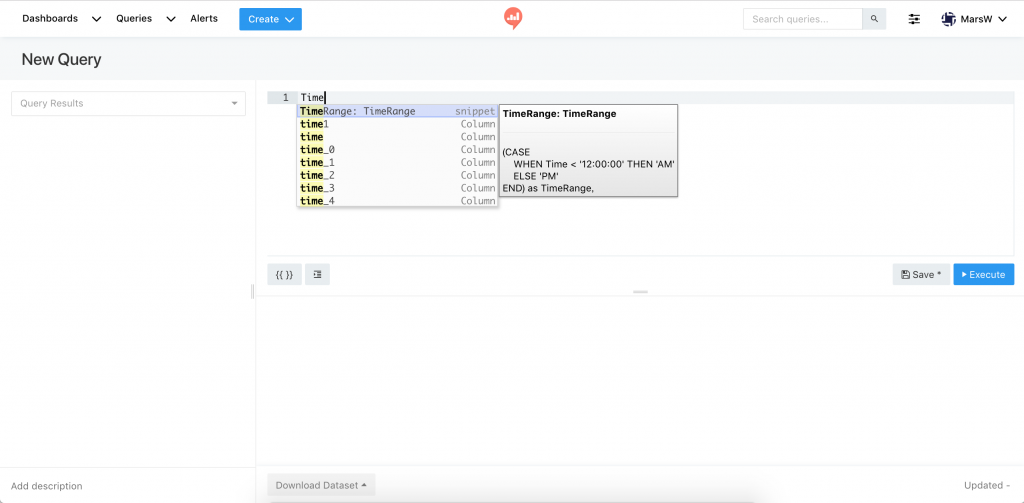
同 auto complete 的概念,只要打出 Trigger 的關鍵字,就可以幫你自動把內容補齊。
如果希望對既有的 Query 再做一層的 Query,
可能是做第二層加工,像是 JOIN、GROUP BY 或使用 Parameter 等條件...,
Redash 有個很好用的功能:
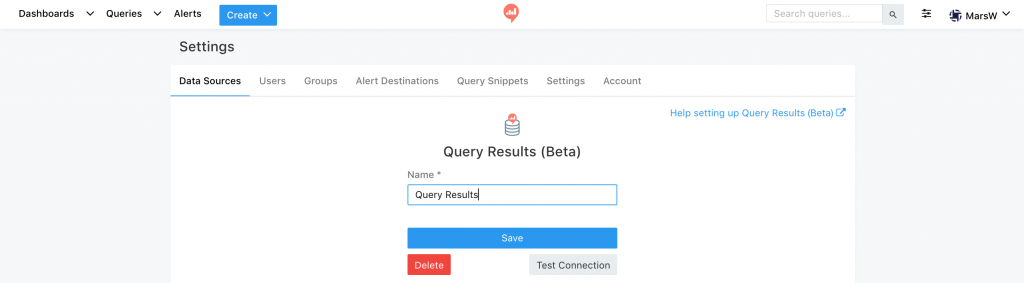
在使用之前需要先增加 Data Sources (左上角 Search Bar旁邊的圖式) ,
新增「Query Results (Beta)」,名稱可隨意
然後就可以用FROM query_[QUERY_ID]語法來對既有的 Query 做操作
eg.
QUERY_ID =18
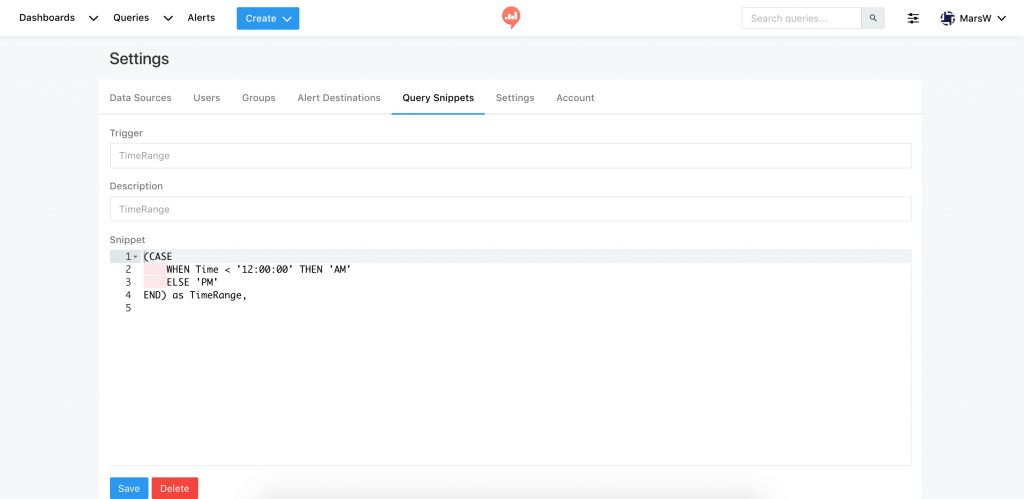
SELECT TransactionID,`Date`,Time,
(CASE
WHEN Time < '12:00:00' THEN 'AM'
ELSE 'PM'
END) as TimeRange,
CustomerID,CardID,GasStationID,ProductID,Amount,Price
FROM ccs.transactions_1k
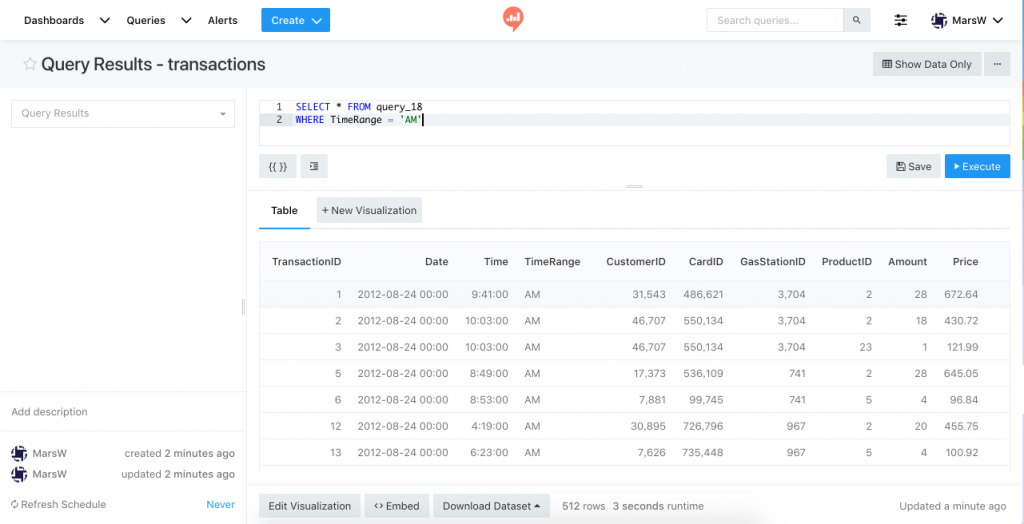
New Query
SELECT * FROM query_18 WHERE TimeRange = 'AM'
如果原 Query 是有包含 Parameter 的,是無法使用 Query Results 的,
會無法 Query 出任何資料。
之前也發覺很多 MySQL 語法不能用 :
eg. DATE_FORMAT、SUBSTRING_INDEX,
這次深入看了一下 Query Results 的 source code,發覺他底層是用 SQLite。
所以這邊要使用的語法就要特別注意,無法使用原本的 MySQL(雖然語法滿相像的,
第一次看文件範例以為是,發覺不行的時候也以為是 Query Results 的限制0rz )。
在公司的實例經驗中,我會用先建立一張大表,
各種 Parameter 以及 GROUP BY 等操作就用 Query Results 對那張大表搜尋;
而在內部訓練中會讓同事學到一些
SQL (SUM, AVG, GROUP BY, SELECT, WHERE) 和簡單的圖表操作,
同時配合權限控制(之後會再介紹到),如果他們看到我已經建好但想要客製成自己需求的就可以利用 Fork,也不怕會更改到原本的 Query,又可以自行調整 Query 的條件、需求的資料,或是 Visualization 的內容。
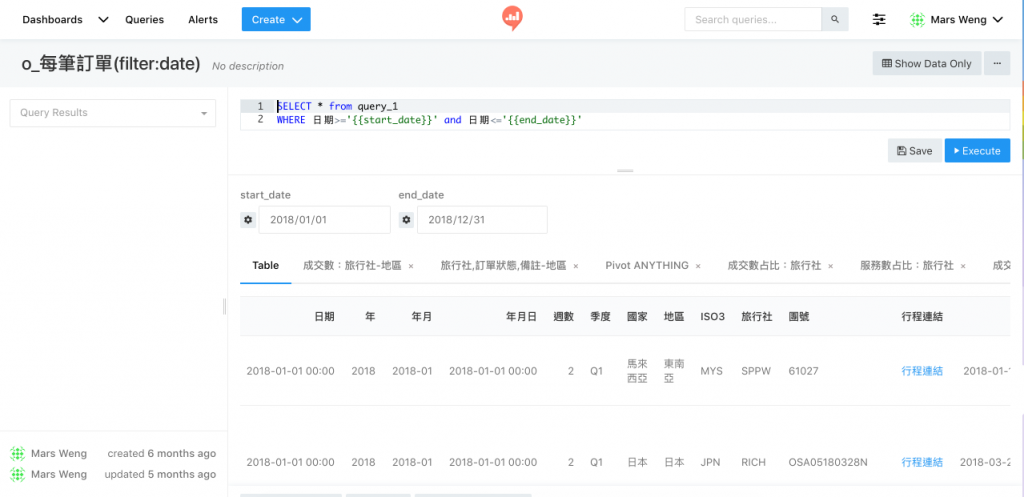
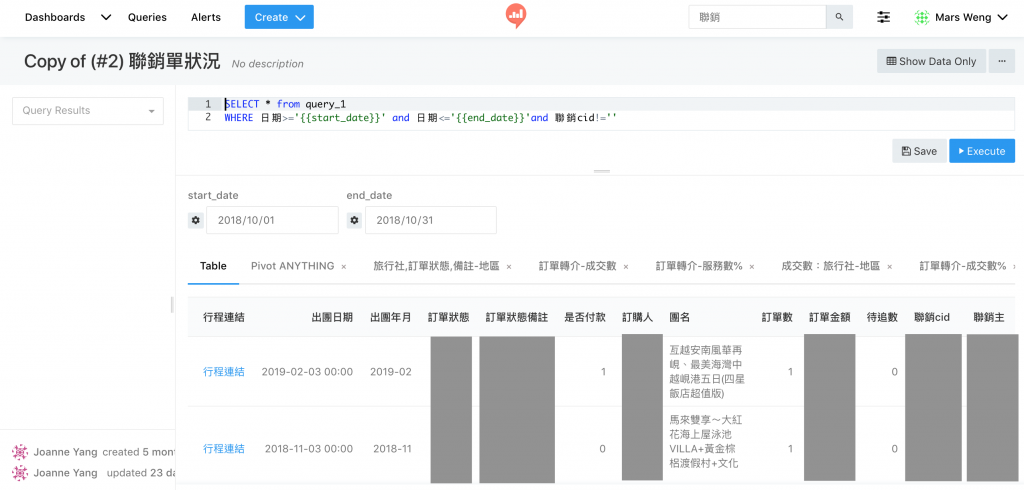
我們也會用 Query Results 來串接不同資料源,因為在 Query 的時候一次只能選一種,加上每個 Data Sources 的 Query 方式也不太一樣,就可以利用Query Results 配上 JOIN 來串接。
eg. 訂單資料在 MySQL 配上 Google Analytics,可以看流量跟訂單的關係
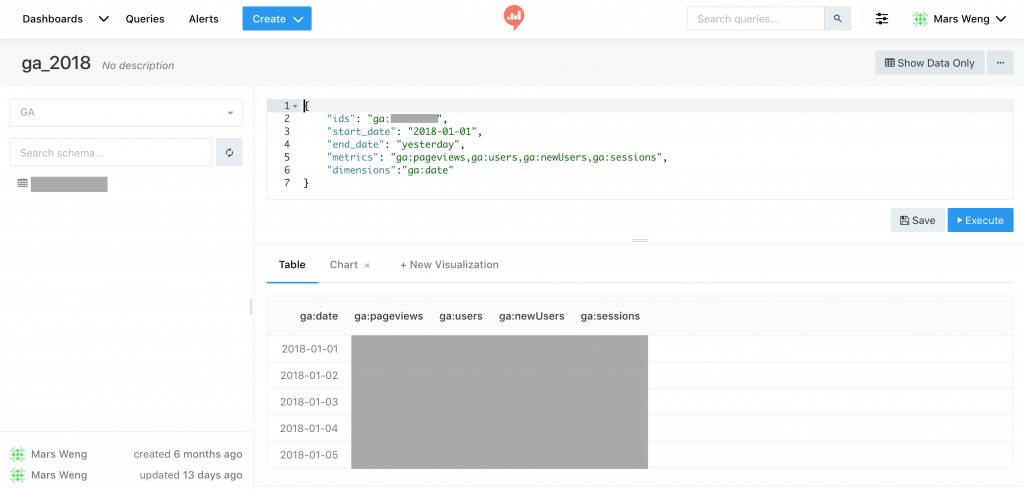
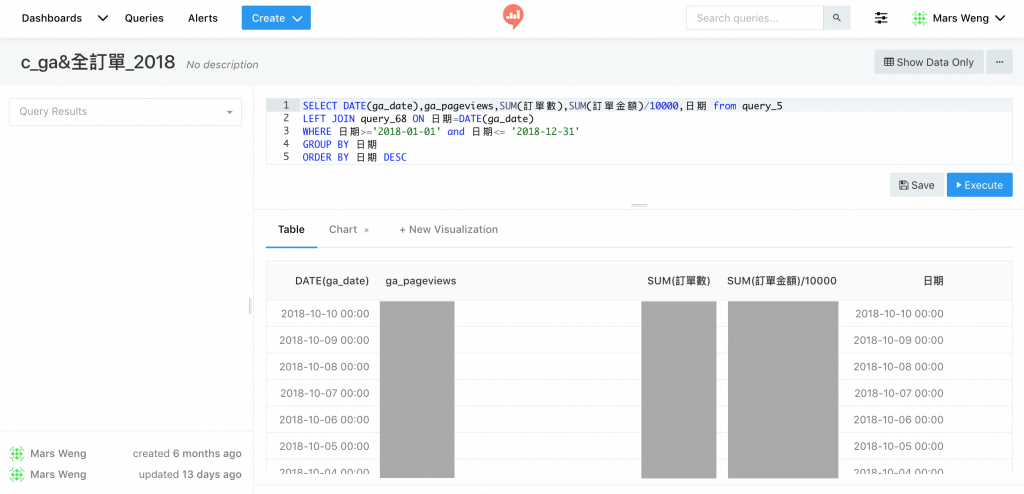
基本上我們 Query Results 算是用滿多的,不過其中的風險就是因為基底都是要先過最基礎的那個 Query,也因此會先撈出全部的資料到第二層、第三層...去做 WHERE 條件限制或是其他 SQL 運算;而先建一好 Data Warehouse 再從裡面撈資料,應該是會比 Query Results 快很多。
但因為我們是旅遊電商,不像一般電商下單到出貨時間很短,可能是出國前三個月~半年就下訂,有出團人數不足而最後訂單取消、或是同訂單加定人數或是又有額外優惠因而影響訂單金額的狀況...。
因為訂單容易有變化,不單純只是 insert 還會有同資料 update,目前用此種方式,不需要多作一層 ETL 、等排程時間、確保資料新增/更新即時,即可在 Query 的時候就是即時資料,算是以現有開發資源,又能顧及大部分人需求的方案。
ps. 文章同步發表於 Medium

