Redash 自架最大的好處就是可以跑 Python Query,
有個自己最習慣的開發語言當然是再好不過的,
同樣的,跟前篇文章的 Query Result 一樣,
Python Query 是一個新的 Data Source,
但 Data Source 預設是沒有 Python 的,還要先做些環境設定:
目前我的安裝方式都是 run script,可參考之前文章
之前在公司運行的版本目前是 4.0.1+b4038vim /opt/redash/.env
在檔案最末端加上以下此行就可以了。
export REDASH_ADDITIONAL_QUERY_RUNNERS=redash.query_runner.python
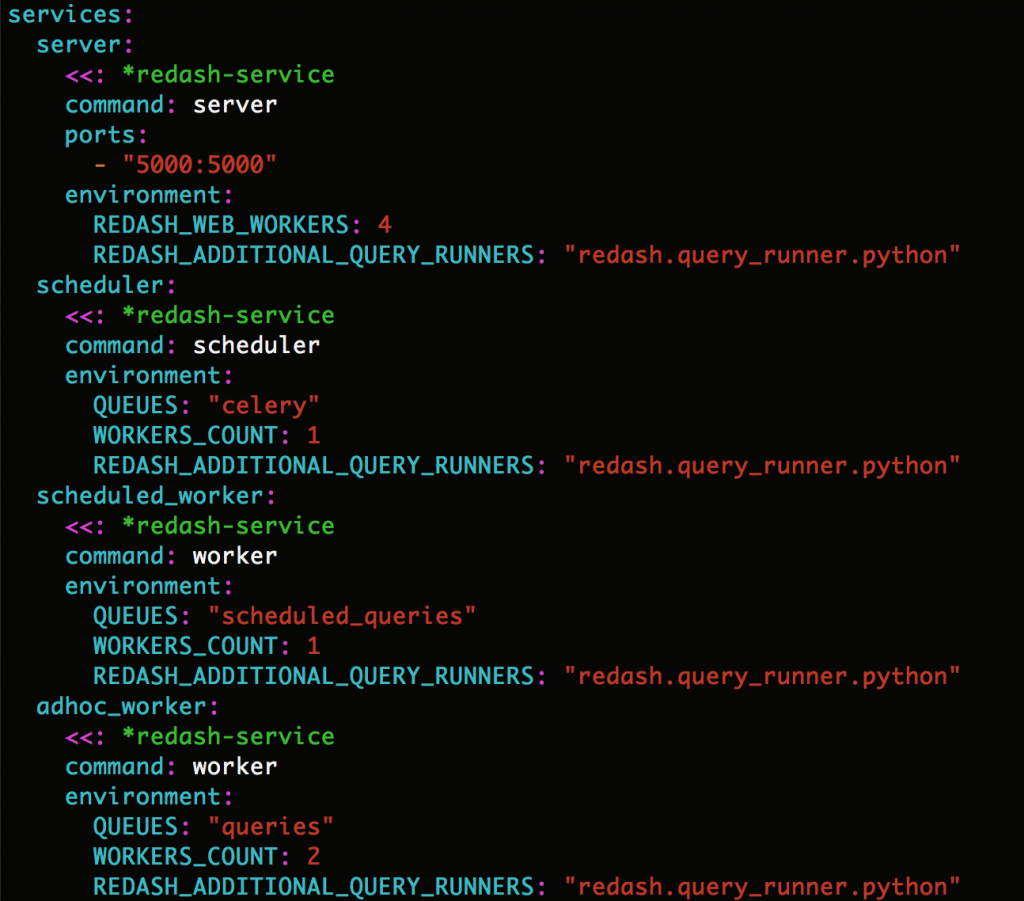
但這次我的 Redash 版本是 5.0.1+b4850,
試了好一陣子才找出正確的設定:vim /opt/redash/docker-compose.yml
在每個 command 是 server, scheduler, worker 的 environment 的底下加上
REDASH_ADDITIONAL_QUERY_RUNNERS: "redash.query_runner.python"
設定好了之後執行以下指令或是重開機
cd /opt/redash
docker-compose up -d
就可以在 Data Source 看到 Python 的選項,
也是隨意命名儲存就行了~
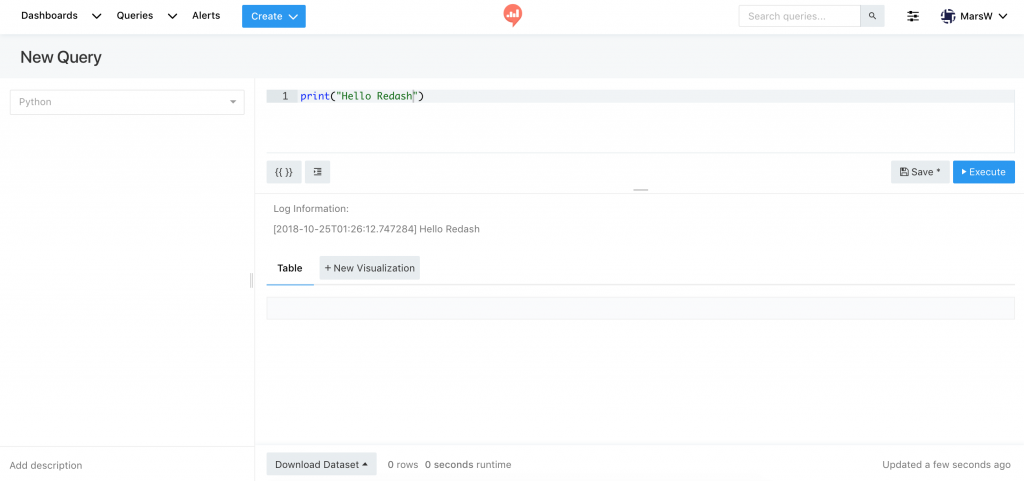
在 Query 中選擇剛才設定好的 Python Data Source 名稱,
就能直接寫 Python 3 的語法來進行 Query。
如果使用到 print,會在 Visualization 上方的區塊顯示
Log Information:
[TIMESTAMP] 程式印出來的資訊
要讓 Python 操作能產生 Redash 支援的格式,至少要能顯示出 Table,
進而才能做其他 Visualization,主要的要點是
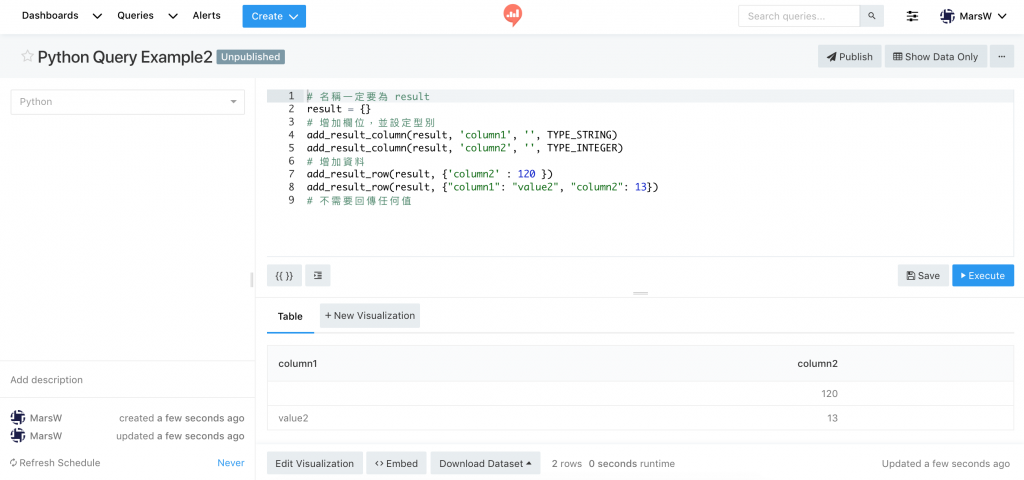
字典(dictionary)型別且名稱為 result 的物件,不需回傳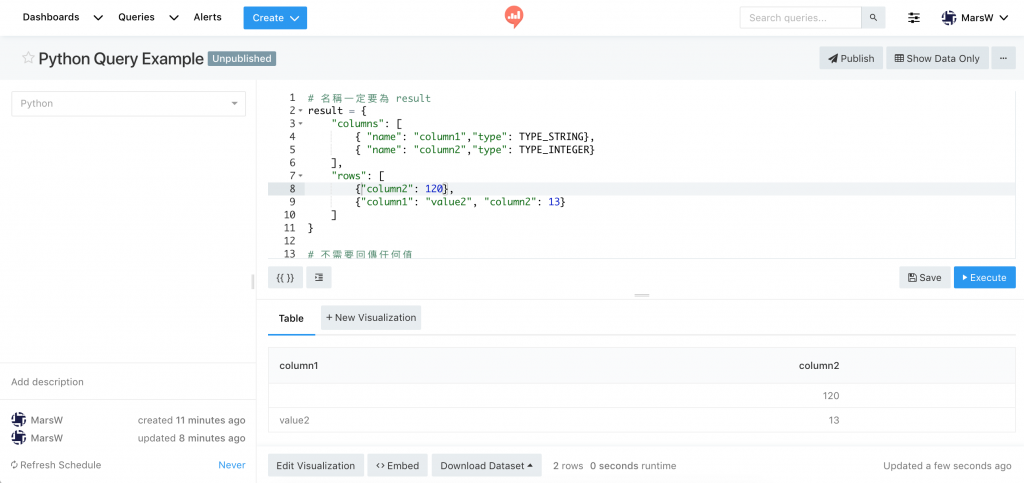
要增加 columns, row 除了可以用 Python 的語法自行 append 串列外,
Redash 的 Python Query 也提供兩個 Function 讓我們使用:
add_result_column((result, column_name, friendly_name, column_type)) 是加入每一欄,就是想要的欄位,同時設定資料型態 (friendly_name)add_result_row(result, dictionary_value)# 名稱一定要為 result
result = {}
# 增加欄位,並設定型別
add_result_column(result, 'column1', '', TYPE_STRING)
add_result_column(result, 'column2', '', TYPE_INTEGER)
# 增加資料
add_result_row(result, {'column2' : 120 })
add_result_row(result, {"column1": "value2", "column2": 13})
# 不需要回傳任何值
Python 會很受歡迎除了很好上手之外,主要也是他支援很多模組(module),
但在 Redash 中,如果要使用模組需要特別設定:
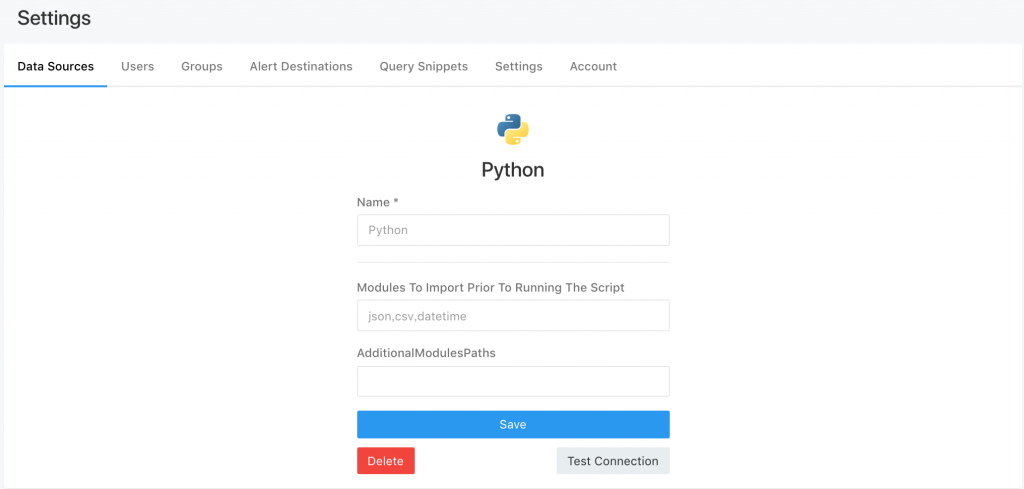
回到 Data Sources 的 Python 設定頁面,
把會要 import 的模組以,分隔(中間不能有空格)加入
DO NOT
json, csv, datetime
DO
json,csv,datetime
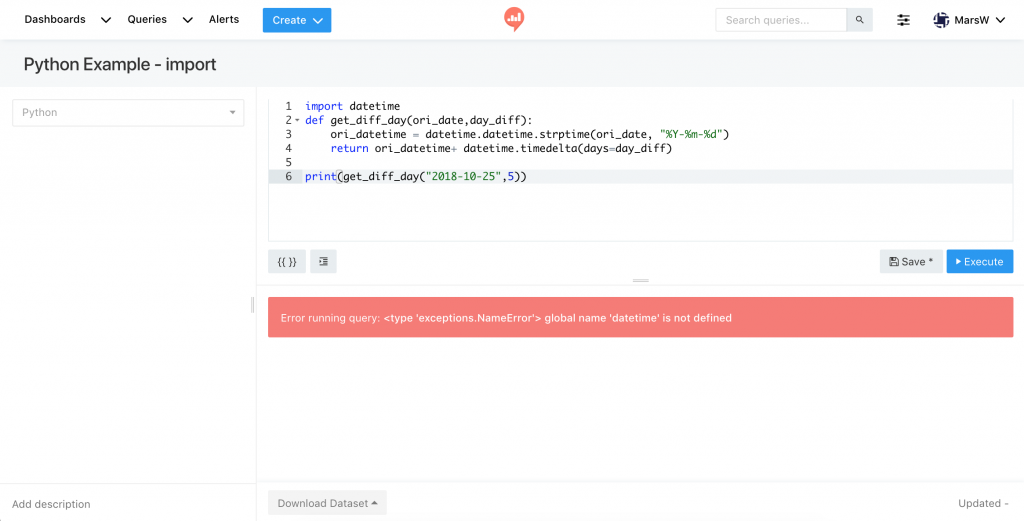
如果未在 Data Sources 加入 Query 中有用到的模組,會出現以下錯誤訊息
Error running query: <type 'exceptions.Exception'> 'datetime' is not configured as a supported import module
另外,如果在 Query 中有寫到自定義的 function,
function中 又有用到需要 import 的模組的話,務必要記得把 import 寫在 function 中
DO NOT
import datetime
def get_diff_day(ori_date,day_diff):
ori_datetime = datetime.datetime.strptime(ori_date, "%Y-%m-%d")
return ori_datetime+ datetime.timedelta(days=day_diff)
print(get_diff_day("2018-10-25",5))
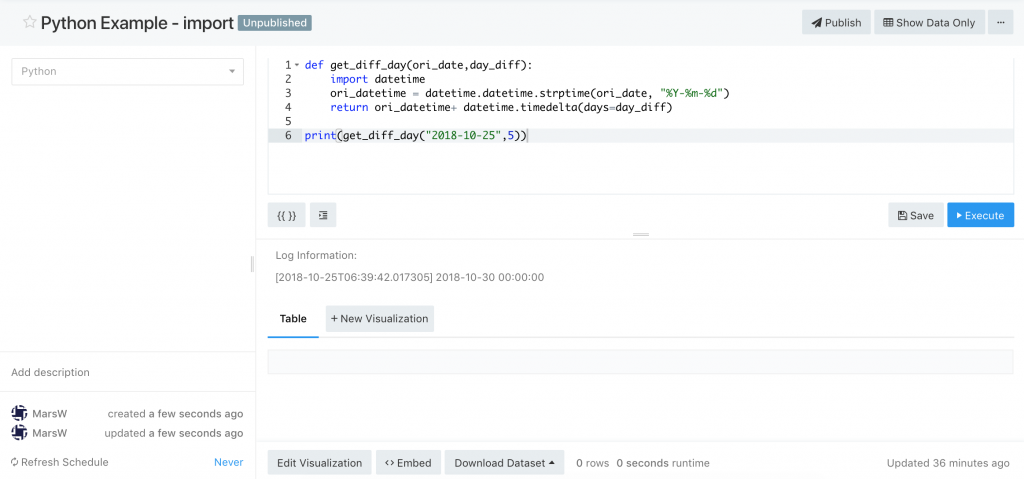
DO
def get_diff_day(ori_date,day_diff):
import datetime
ori_datetime = datetime.datetime.strptime(ori_date, "%Y-%m-%d")
return ori_datetime+ datetime.timedelta(days=day_diff)
print(get_diff_day("2018-10-25",5))
大部分需求基本上是可以用 SQL Query 就可以滿足,
不過原本同事用的報表有一些是 Excel 之類的軟體組合的操作,像是以下這種資料:
每個月營收目標,因此換算的日目標也不一樣,每個月是獨立的 Gap 會重置
想要看每天的營收狀況累積起來離目標差多少,
也就是 今日累積目標Gap = (今日營收-日目標)+昨日目標 Gap
日期,日營收,日目標,累積目標Gap
2018-10-28,2000,10000,-8000 (假設昨天持平)
2018-10-29,15000,10000,-3000
2018-10-30,5000,10000,-8000
2018-10-31,25000,10000,7000
2018-11-01,24000,12000,12000
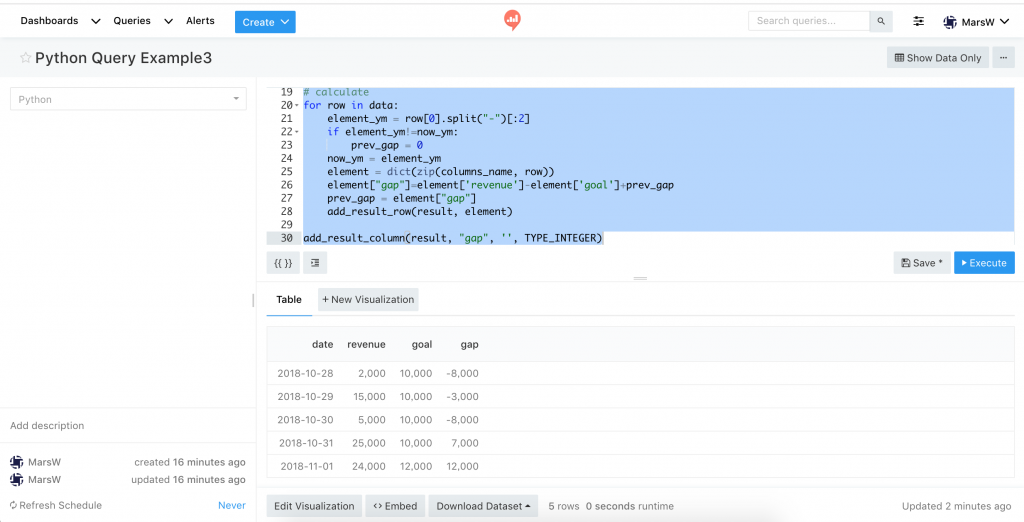
這類的需求用 SQL 操作會比較麻煩,我就會用 Python Query 處理:
result = {}
# column
columns_name = ['date','revenue','goal']
columns_type = [TYPE_STRING,TYPE_INTEGER,TYPE_INTEGER]
for c_name,c_type in zip(columns_name,columns_type):
add_result_column(result, c_name, '', c_type)
# row
data = [
['2018-10-28',2000,10000],
['2018-10-29',15000,10000],
['2018-10-30',5000,10000],
['2018-10-31',25000,10000],
['2018-11-01',24000,12000]
]
# init
prev_gap = 0
now_ym = ""
# calculate
for row in data:
element_ym = row[0].split("-")[:2]
if element_ym!=now_ym:
prev_gap = 0
now_ym = element_ym
element = dict(zip(columns_name, row))
element["gap"]=element['revenue']-element['goal']+prev_gap
prev_gap = element["gap"]
add_result_row(result, element)
add_result_column(result, "gap", '', TYPE_INTEGER)
另外,Redash 的 Data Sources 不包含 json,
self-hosted 也沒看到如線上有支援 csv,
或是想要直接用 requests 之類的模組去爬資料,
都可以直接用 Python 處理,等於可以有更多種類的 Data Sources 可用。
這次是 Redash 5.x 的版本已經沒有 /opt/redash/.env 這個檔案,
架構似乎也不太一樣,但在翻找文件的時候,
實在是想小小抱怨一下 Redash 的文件實在不是很同步:
安裝手冊是最新 5 版的介紹,更改環境變數是在 /opt/redash/env;
但可以調整的環境變數列表文件,還停留在 4 版的介紹/opt/redash/.env
雖然這些官網說的改法對我都沒有用就是了 0rz
網路文章也沒有這麼新版的,
比較新的文章是説只要把 server 的 environment
加上 REDASH_ADDITIONAL_QUERY_RUNNERS 變數就好,
的確這樣是可以在 Data Source 看到 Python,
但進到 Query 時卻會出現錯誤:AttributeError: 'NoneType' object has no attribute 'annotate_query',
也是爬了許久的文還是找不到解答。
之後是參考朋友的文章,
也看到不少人同樣在舊版的設定是 server 跟 worker 都加值。
但新版沒有跟 server 同級的 worker,
想說就把應該相關的 scheduler, worker 都設定上就可以正常運作。
希望這次的經驗也能幫助到大家~
參考資源
[Vis] Redash Dashboard 應用(上)|資料視覺化
[Vis] Redash Dashboard 應用(下)|資料視覺化
Redash Python functions
ps. 文章同步發表於 Medium

