第十六天 Deadlocks(死結)--下
昨天我們講完了前兩個處理deadlock的方法,今天來說後面兩個:
Detection(偵測):容許發生deadlock,但要能偵測到且恢復
Single instance:
我們先從簡單的single instance看起,在這裡我們是用wait-for graph來表達,圖形裡的頂點皆是process。而這裡使用的演算法,需要定期的檢查看有沒有cycle出現,有的話就產生deadlock了。其實wait-for graph跟resource-allocation graph只差在把resource拿掉而已,以下有圖給大家比較: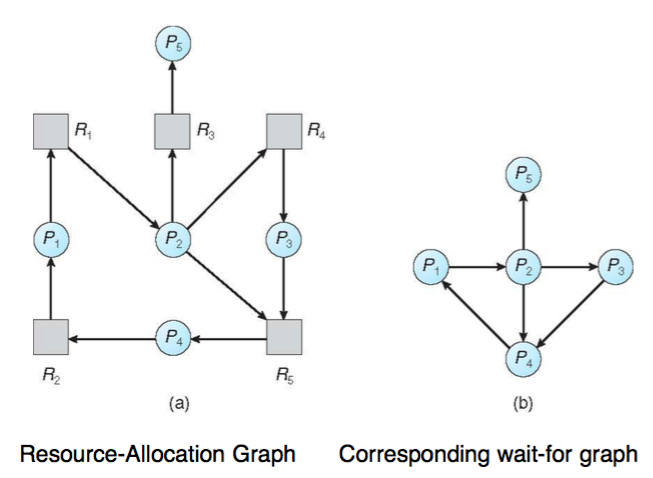
Several instance:
先來定義detection演算法要用到的參數:
Detection Algorithm:
偵測演算法,用兩個陣列Work(代表resource)和Finish[i](代表process是否握有資源,i = 1,…,n)來幫忙:
以下有例題及運算:
有5個process,3個resource type(A有7個instance、B有2個instance、C有6個instance),如果按照P0 -> P2 -> P3 -> P1 -> P4的順序執行就不會形成deadlock。但如果2的c多要一個instance,P1 P2 P3 P4就會形成deadlock。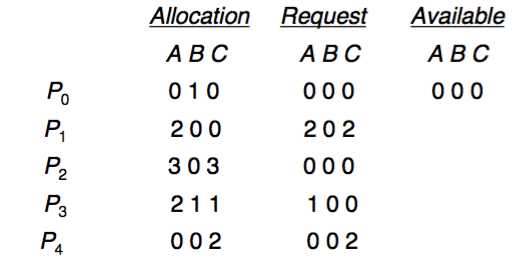
偵測到有deadlock的process可以選擇要把它給終結掉或是把資源給中斷。如果把它終結掉,可以依照優先權高低或是資源用的多寡還有很多條件,去決定要砍掉誰,一次砍一個process。如果是把資源中斷,就找資源使用最少的開始犧牲(selecting a victim),之後重新再來一次(rollback),但這有可能造成某些process會starvation(使用的資源都是最少的)。
Ignore(不理):這個方法很多作業系統都有使用,因為上面三種都會消耗系統資源,或是不符合成本效益,所以作業系統都會假設deadlock不存在,如果真的發生,系統可能就會直接interrupt process。
Deadlock到這就結束啦~~



 iThome鐵人賽
iThome鐵人賽