Generative model:
之前我們所談的多半是 Discriminative model,亦是訓練一個分類器,判別輸入影像是否是屬於某一類的物件,或是輸入兩個人臉影像,判別是否為同一人等等。在這類訓練模型,資料的原分佈並不是學習的重點,分類器只要從現有的訓練資料中,找出能夠區分不同類別的特徵向量,便可以完成任務。
另外一個模型,則被稱為 Generative Models,在這個模型中,從訓練的資料中學習到取樣的原分佈就顯得重要,因為該模型的主要功能是希望能產生與訓練資料相近的樣本,就如同上一篇中所介紹的影像風格轉換。
在傳統的統計學習方法上,資料的原分佈的方法,可以由兩大類的方法學習:
因為影像資料通常都非常龐大且像素之間的關係難以捕捉,所以在生成影像的技術上一直難有突破,在今天所要介紹的 Generative Adversarial Network,在此都簡稱 GAN,因為能產生高質量清晰的影像,而在推出後倍受矚目,甚至被 CNN 的發明者,Yann LeCun 譽為當年最創新的主意。
Generative Adversarial Network
GAN 是一個 semi-supervised 的學習方法,背後的原理是取自 Game theory 零和遊戲。零和遊戲是一種兩個玩家對抗型的遊戲,常見的二人棋盤遊戲,如圍棋等都是零和遊戲。在 GAN 的架構中,包含了一個 discriminator network 和一個 generator network,來模擬零和遊戲中的兩個玩家。
一個最常被使用用來解釋 GAN 的比喻,便是 generator network 是一個貨幣偽造者,而discriminator network 則是捕捉偽造者的執法單位。兩者的目標一致,但最佳化的方向不一樣。對警察而言,他希望能準確辨識偽造貨幣,使其無法在市面使用(maximize objective function),而對偽造者而言,則希望偽造貨幣能成功到騙過警察,而在市面流竄(minimize objective function)。
DCGAN
GAN 簡化版的 min-max 演算法,也是取自於零和遊戲的理論基礎。最初 GAN 是利用手寫數字影像 MNIST 做測試, discriminator 和 generator networks 都是用 feed forward 的架構去實踐。爾後,Facebook 的研究者們,則利用 convolution network 取代了 feed forward 的網路架構,用 Convolution network 去萃取影像特徵,再用 de-convolution network 去生成影像,架構可以見下圖。這個方法使用在不同的影像集包括了 SVHN 和 Celeb 都產生不錯的結果。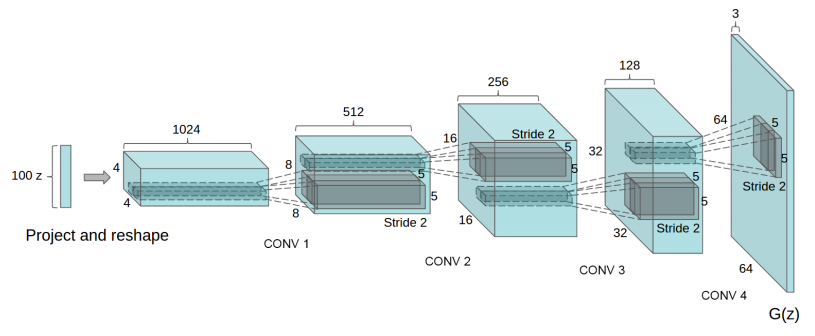
Image to Image translation
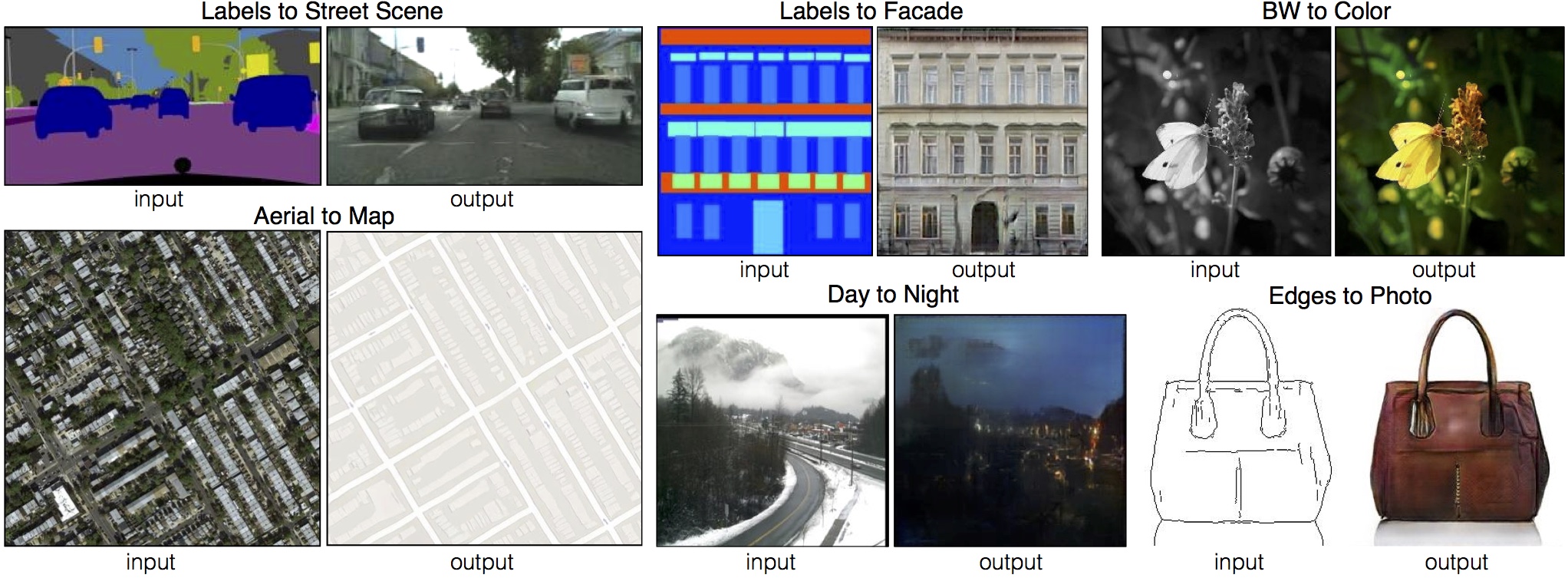
和上一篇的影像風格轉換相關的 GAN 應用則是 image to image translation,由柏克萊大學的實驗室在 CVPR 2017 年會上所發表的 pix2pix 文章。和影像風格轉換任務不同的是,image to image translation 只需輸入一張影像,而輸出影像則是該輸入影像不同風格的影像。至於 image translation 系統該輸出什麼風格的影像,則是由訓練時給予配對風格影像來決定。更多的 Image to Image translation 輸出例子可見下圖。
pix2pix 用的架構和 GAN 類似,但由於該系統的目的不在於學習影像的分佈,以產生仿真的影像,而是希望透過監督學習的方式,讓原真實影像產生在訓練時所配對的影像風格。欲實踐這個任務,所需要的是 GAN 的改良版本,稱為 conditional GAN。Conditional GAN 和 GAN 最大的不同在於 conditional GAN 在於學習有目標標示(欲轉換的風格影像)的 conditional probability 而非資料的 joint/likelihood probability,也就是把損失函式中的 p(x) 和 p(z) 替換成 p(x|y),p(z|y)。架構與損失函式可見下圖:
秉持著站在巨人肩膀上的精神(其實是年紀大了...),關於 pix2pix 的 sample code 可見 pix2pix 的官方網站。

