在前幾篇文章中,大略提到了深度學習架構中所用的計算圖,以及計算圖如何來幫助在異質化的計算平台中達到優化的高速計算。接著,我們將要介紹一個由 University of Washington SAMPL group 開源計畫所開發出來的深度學習編譯器架構,稱為 TVM。
在這個開源的深度學習編譯器架構中,不僅利用 Nvidia 的 NNVM 實踐了前一篇貼文,提到以計算圖為 IR 的程式優化方法,更實踐另一層更低層與不同計算硬體設備後端相關的 IR 被稱為 Tensor Expression Language。有了這層 IR 的優化方式來產生最終的執行命令,有助於分配計算圖中不同的運算元到不同的計算後端,如高計算需求的 convolution 計算元分配至 GPU 後端。
相較於計算圖作為 IR 來對整個計算圖做優化,Tensor Expression Language,多半使用於影像處理相關的計算優化中,有助於對單一運算元作優化,尤其是該計算元在 GPU 高度平行化的計算環境有較大的表現增益,據該計畫專頁宣稱,再經過 TVM 優化後的深度學習模型也較容易 deploy 到不同的平台上,如下圖所示。
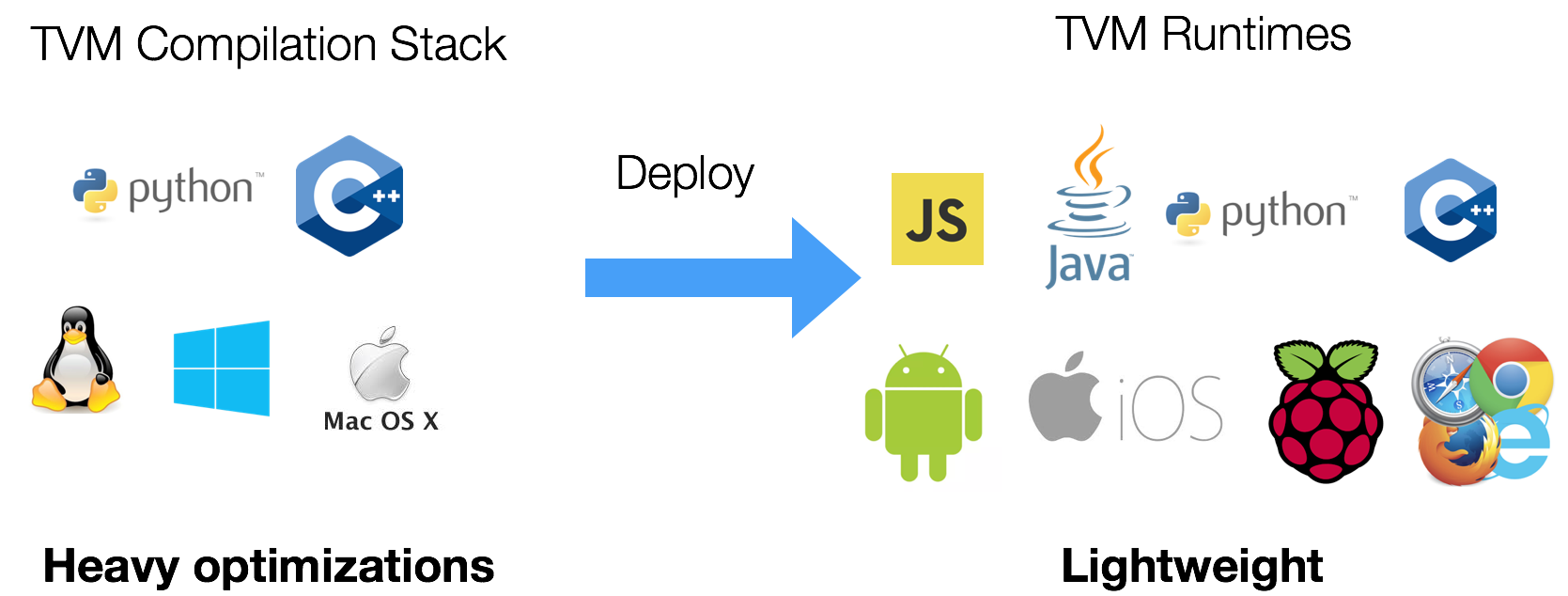
另外一個使用 TVM 針對 Tensor Expression Language 優化的好處則是採用 Halide 相似的設計將演算法和程式優化的邏輯分開的設計方法。Halide 是一個 Domain Specific Language,主要是針對現今計算硬體,如:GPU 等後端,編寫高效能的影像處理原始碼。而使用 Halide 來編寫影像處理的演算法,程式設計師仍舊可以撰寫非高效能的序列執行程式,而讓編譯器排程如何針對多執行緒做排程計算優化的部分。
最後一個 TVM 的優點,則是能夠使用 RPC,使深度學習模型開發者,對遠端的智慧型手機或嵌入式設備做深度學習模型的跨平台編譯和優化。這項功能對於在硬體支援較多限制的智慧型手機以及發展 IoT 等等的大型智慧網路相當有助益。
目前 TVM 可以對不同現行的深度學習架構模型做編譯,如在前一篇文章中介紹的 ONNX,Keras ,MXNet,DarkNet 和 Tensorflow 等。有興趣的讀者可以參見 TVM 的官方文件,尋找更多編譯的範例。
最後關於深度學習架構計算優化的發展,多半是著重在影像處理上,原因大多是影像本身就可以當作許多區塊狀的小陣列,而非常適合在 GPU 這樣對高平行計算特化的硬體上。對於 RNN 序列化的上的優化,由於 RNN 本身在序列間相依性,而造成平行化的困難。所以,目前在 RNN 模型的計算優化上多針對 Batch Normalization 或 Attention 這些運算元做編譯優化。
關於 ”30 天學會深度學習和 Tensorflow” 這個鐵人挑戰系列,從第一篇,編號為 00 的緣起,到此最末篇編號為 29 的加速前進,我在短短的一個月中塞進了四大主題:
因為要在一個月內塞進深度學習的概念和 Tensorflow 的設計本來就是一個相當難的挑戰,相信大家是愈讀愈模糊。所謂,萬丈高樓也仍是由平地一磚一瓦蓋起,這 30 天把學習深度學習的藍圖給繪製好了,若讀者對這四大主題感到有興趣,並希望能閱讀更多有關最新資訊,一起學習或重溫基礎知識,並且能站在相互切磋的角度下,互相參考一些範例程式碼,請繼續關注本人在方格子(前 SOSReader)的「翻滾吧!駭客女孩!」寫作專案。
最後,身為偽文藝女青年,我不得不為這個系列下一個稍微文藝的結尾:
那標號為 30 的未曾寫完的最終文章,將會永遠的延伸和編寫,成為終生學習的最後一個章節。

