由現行深度學習架構概況 一文中,可以發現目前深度學習的架構相當多種,並各有其特色。但這樣百家爭鳴的情況,卻引發了如巴別塔危機的混亂狀況。
這種情況更由於影像模型因為訓練不易或其受限於計算平台的硬體架構,所以經常需要使用他人以訓練好的類神經網路模型,在其上層加入自己的分類器層,以 transfer learning 的方式來完成任務。雖然感謝共享模型的普遍,然而因為模型的建置架構不同,再加上許多即使輸出權重,也因為使用高階 API,以物件導向方式建構的模型黑箱化,所以在從硬碟讀入權重時,通常會發生許多問題。
為了解決這個問題,於是出現了 Open Nueral Network Exchange (ONNX)開源類神經網路模型交換格式這個計畫。目前參與這個計畫的 Facebook,Microsoft 和台灣的深耕編譯器與虛擬機器的 skymizer 公司等。但,很不幸地,Google 並不在其中的名單中。雖然 Google 並不對 ONNX 做直接支援,但還是有熱心的編程者寫了 Tensorflow 到 ONNX 格式的轉換程式碼。
在這裡我們將以轉換低像素(low-resolution)為高像素(high-resolution)的一個 pre-trained convolution neural network 來解釋該如何用單一 ONNX 格式,將可增加像素的卷積網路模型讀入並做高像素影像生成。
首先,我們需要安裝下列不同的函式庫:
# 安裝 pytorch (with caffe2) / under shell
# 請不要用 conda install pytorch torchvision -c pytorch 的方法安裝
# 因為這種安裝方式並不會將 caffe2 包裝在安裝檔內
# 另外,-c 是指定下載安裝檔的 channel 在這裡不使用 annaconda
# 預設的 channel,但使用 pytorch 提供的 channel
$ conda install pytorch-nightly-cpu -c pytorch
# 安裝 tensorflow,很不幸地,太過新的 tensorflow 會造成 crash,
# 所以 安裝 onnx-tensorflow 支援的最低版本 1.5
# 另外, tensorflow 的官方網站建議用 pip 來安裝
$ pip install tensorflow==1.5.0
# 安裝 onnx
$ pip install onnx
# 安裝 onnx-tf,這個 package 是用來作為 tensorflow onnx backend
$ pip install onnx-tf
# 安裝 mexnet
$conda install mexnet
打開 jupyter notebook,分別 import 這些 packages,試試看是否安裝成功(這是懶人安裝檢查法,必須要冒著可能會 crash python 的危機)。
>>> import torch
>>> import caffe2 # from torch
>>> import caffe2.python.onnx.backend
>>> print(torch.__version__)
1.0.0.dev20181014
>>> import onnx
>>> print(onnx.__version__)
1.3.0
>>> import onnx_tf.backend as backend
>>> import tensorflow as tf
>>> print(tf.__version__)
1.5.0
>>> import mxnet as mx
>>> import mxnet.contrib.onnx as onnx_mxnet
>>> print(mx.__version__)
1.2.1
接著請用你喜愛的方式來下載所需要的檔案,包括了測試圖檔和一個已經轉成 onnx 檔案格式的 convolution network 模型檔。在這裡我是用 requests。
import requests # 若無此套件,請使用 conda install requests
import os
import PIL as pil # 若無此套件,請使用 conda install pillow
test_img = 'super_res_input.jpg'
if not os.path.exists(test_img):
img_url = 'https://s3.amazonaws.com/onnx-mxnet/examples/{}'.format(test_img)
r = requests.get(img_url)
with open(test_img, mode='wb') as fp:
pil.save(r.content)
model_name = 'super_resolution.onnx'
if not os.path.exists(model_name):
model_url = 'https://s3.amazonaws.com/onnx-mxnet/examples/{}'.format(
model_name)
r = requests.get(model_url)
with open(model_name, mode='wb') as fp:
fp.write(r.content)
接著處理輸入影像。
import numpy as np
# 原影像為 256x256,但是模型為 224x224
img = pil.Image.open(test_img).resize((224, 224))
# 轉換影像為 YCBCr,或 JPEG 模式,每一像素用 3x8 個位元表示
img_ycbcr = img.convert("YCbCr")
# 將 JPEG 的三個 channels 分開
img_y, img_cb, img_cr = img_ycbcr.split()
# 將取出第一個 channel 的影像轉為 numpy array 並擴張為四維 tensor
doggy_y = np.asarray(img_y, dtype=np.float32)[np.newaxis, np.newaxis, :, :]

先用 onnx 載入模型,並檢查模型格式是否有問題
onx_model = onnx.load(model_name)
onnx.checker.check_model(onx_model)
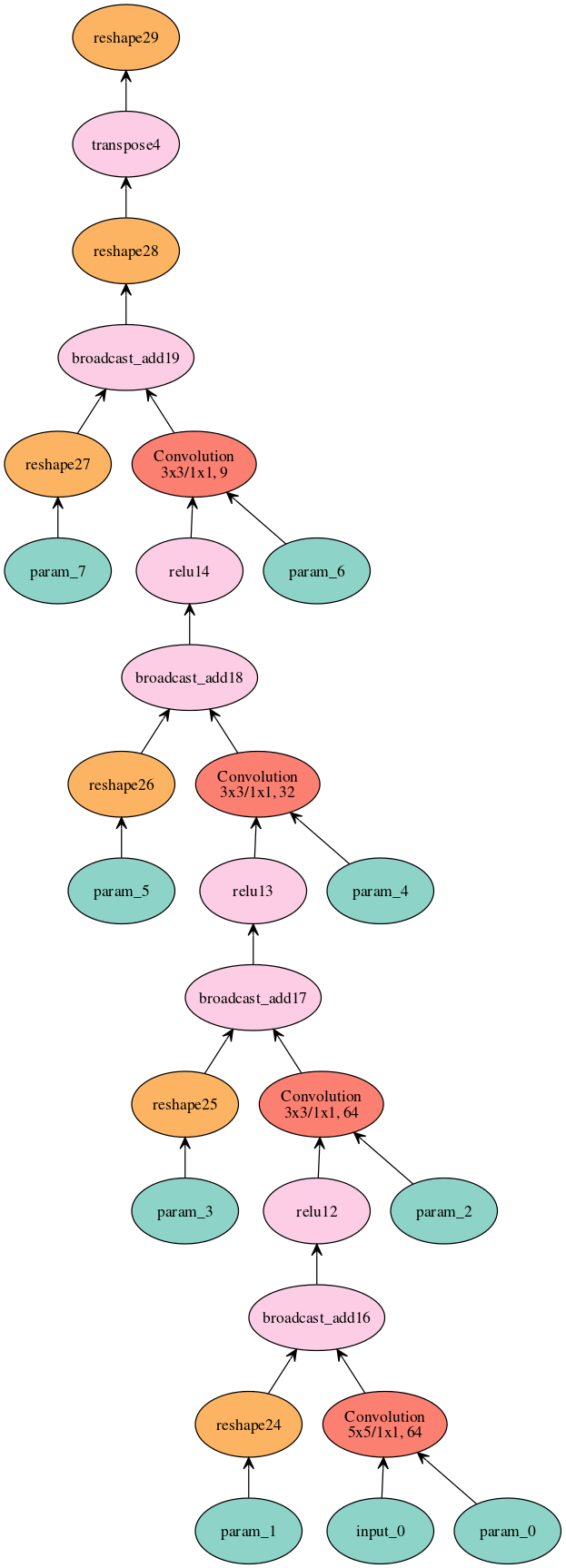
模型的計算圖形則可以參考此圖:
呼叫 onnx-tf 的 backend 來建立 tensorflow 相容的模型,並傳入測試影像於 run 方法,結果影像為第一個傳回引數。最後印出結果影像尺寸,可以看到當影像的尺寸果然變大了。
tf_rep = backend.prepare(onx_model)
big_doggy = tf_rep.run(doggy_y)._0
print(big_doggy.shape) # (1, 1, 672, 672)
和 tensorflow 差不多。
caffe2_doggy = caffe2.python.onnx.backend.run_model(onx_model, [doggy_y])._0
print(caffe2_doggy.shape) # (1, 1, 672, 672)
在這裡,我們用 mxnet 提供的 onnx 模組將模型再次載入,會回傳三個物件,分別是代表計算圖的 sym,計算圖的輸入 - arg 和附加參數 - aux。
from collections import namedtuple
sym, arg, aux = onnx_mxnet.import_model(model_name)
# 找出輸入影像在計算圖中的代號
data_names = [graph_input for graph_input in sym.list_inputs()
if graph_input not in arg and graph_input not in aux]
print(data_names) #['1']
# 建立 MXNet Module 模型物件
mod = mx.mod.Module(symbol=sym, data_names=data_names, context=mx.cpu(), label_names=None)
# 設定模型輸入型別和模式
mod.bind(for_training=False, data_shapes=[(data_names[0],doggy_y.shape)], label_shapes=None)
# 設定模型參數
mod.set_params(arg_params=arg, aux_params=aux, allow_missing=True, allow_extra=True)
# 建立 dict,指定傳入影像的方式
Batch = namedtuple('Batch', ['data'])
# 依照 Module 模組輸入的方式,傳入單一測試影像。
mod.forward(Batch([mx.nd.array(doggy_y)]))
mx_output = mod.get_outputs()[0]
print(mx_output.asnumpy().shape) (1, 1, 672, 672)
結果影像,則如下:
本篇主要來自 mxnet ONNX 教學文。其他各式各樣不同的模型轉換,可以參考這篇教學列表。然而,由於 ONNX 還在萌芽階段,要有心理準備遭遇許多艱辛的困難。


{kind=link}