今天又沒工作了
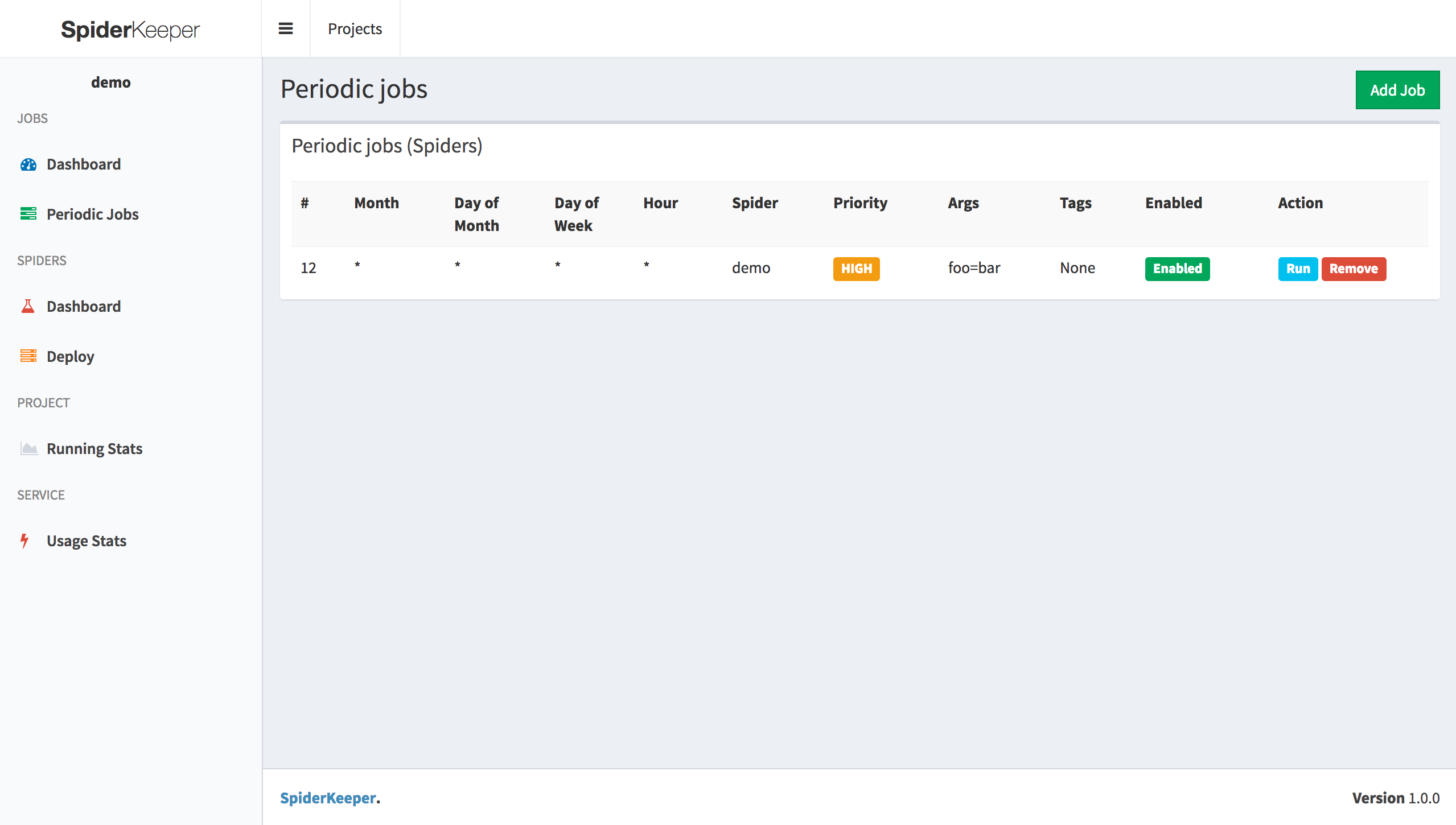
首先有人對SpiderKeeper修了bug在這Here ,不過我用一下發現還有bug,當排程太多會動不了,原因在APScheduler這個工具,所以又修改一下新增可用兩個參數
--executor
ThreadPoolExecutor ,default: 30
--process
processpool ,default: 3
如果卡住的話,請調高這兩個,到目前還沒遇到什麼bug,如果怕危險,其實用scrapyd操作就好了,不然等我出問題了我會再通知
還有提醒一下SpiderKeeper跟scrapyd都沒有密碼保護,一定要用像Nginx的服務保護,不然很危險


![]()
A scalable admin ui for spider service
Current Support spider service
pip install spiderkeeper-2-1
spiderkeeper [options]
Options:
-h, --help show this help message and exit
--host=HOST host, default:0.0.0.0
--port=PORT port, default:5000
--username=USERNAME basic auth username ,default: admin
--password=PASSWORD basic auth password ,default: admin
--type=SERVER_TYPE access spider server type, default: scrapyd
--server=SERVERS servers, default: ['http://localhost:6800']
--database-url=DATABASE_URL
SpiderKeeper metadata database default: sqlite:////home/souche/SpiderKeeper.db
--no-auth disable basic auth
-v, --verbose log level
--executor ThreadPoolExecutor ,default: 30
--process processpool ,default: 3
example:
spiderkeeper --server=http://localhost:6800
Visit:
- web ui : http://localhost:5000
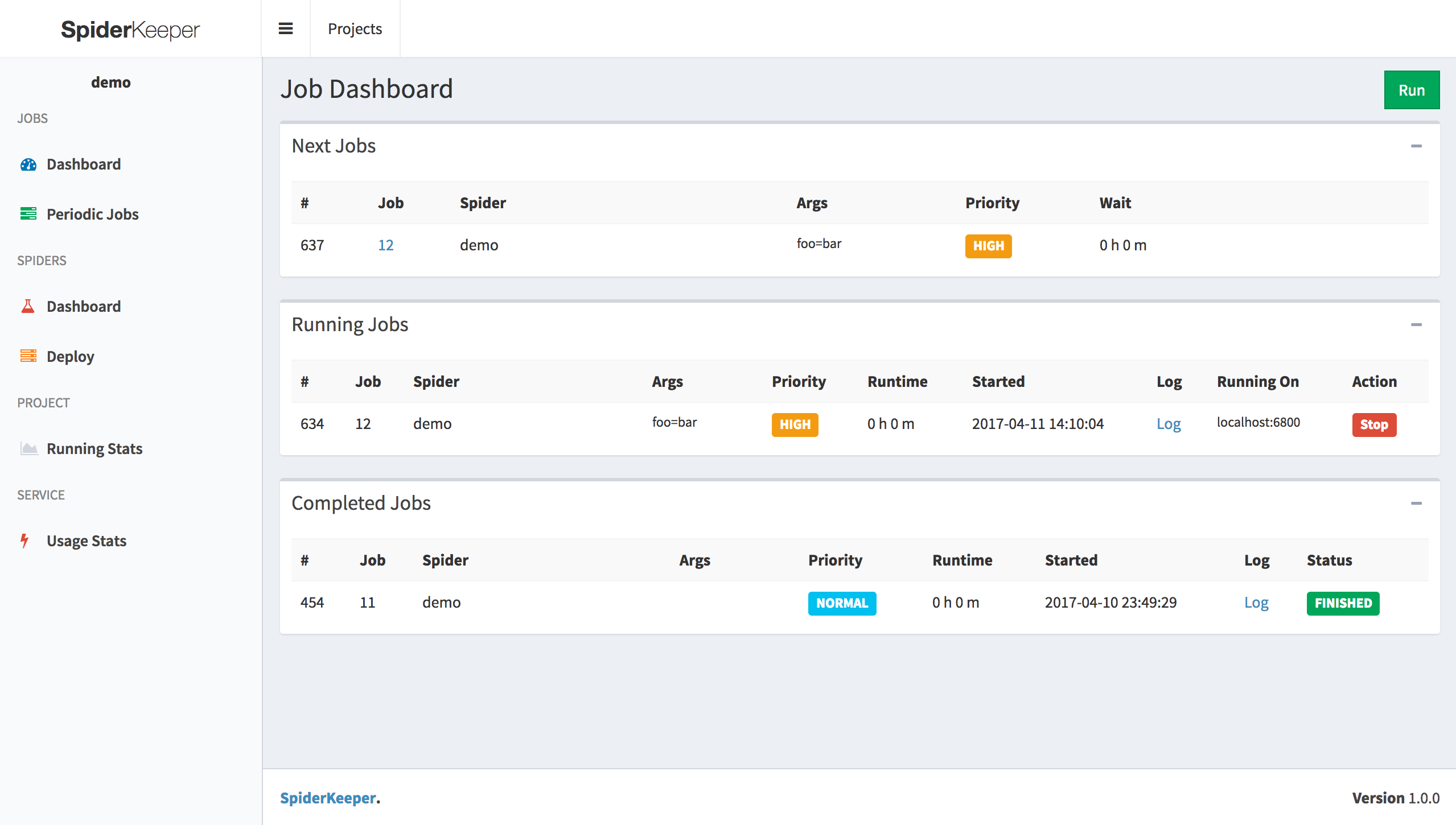
1. Create Project
2. Use [scrapyd-client](https://github.com/scrapy/scrapyd-client) to generate egg file
scrapyd-deploy --build-egg output.egg
2. upload egg file (make sure you started scrapyd server)
3. Done & Enjoy it
- api swagger: http://localhost:5000/api.html
This project is licensed under the MIT License.
Contributions are welcomed!


 iThome鐵人賽
iThome鐵人賽