每拿到新資料時,總用pandas做一些重複性的探勘工作,
今天發現一個好套件-pandas-profiling,
套件作者覺得describe實在是太陽春了,用這個一鍵幫你完成以下初步的資料分析。
安裝(擇一)
pip install pandas-profiling
conda install pandas-profiling
需求
目前是連網版,需要網路連線下載一些Bootstrap跟JQuery。
準備好資料
from sklearn.datasets import load_boston
data = load_boston()["data"]
cols = load_boston()["feature_names"]
df = pd.DataFrame(data=data, columns=cols)
丟進去分析
profile = pandas_profiling.ProfileReport(df)
profile.to_file(outputfile="output.html") #支援輸出html
ProfileReport Attributes
df : DataFrame
Data to be analyzed
bins : int
Number of bins in histogram.
The default is 10.
check_correlation : boolean
Whether or not to check correlation.
It'sTrueby default.
correlation_threshold: float
Threshold to determine if the variable pair is correlated.
The default is 0.9.
correlation_overrides : list
Variable names not to be rejected because they are correlated.
There is no variable in the list (None) by default.
check_recoded : boolean
Whether or not to check recoded correlation (memory heavy feature).
Since it's an expensive computation it can be activated for small datasets.
check_correlationmust be true to disable this check.
It'sFalseby default.
pool_size : int
Number of workers in thread pool
The default is equal to the number of CPU.Methods
get_description
Return the description (a raw statistical summary) of the dataset.
get_rejected_variables
Return the list of rejected variable or an empty list if there is no rejected variables.
to_file
Write the report to a file.
to_html
Return the report as an HTML string.
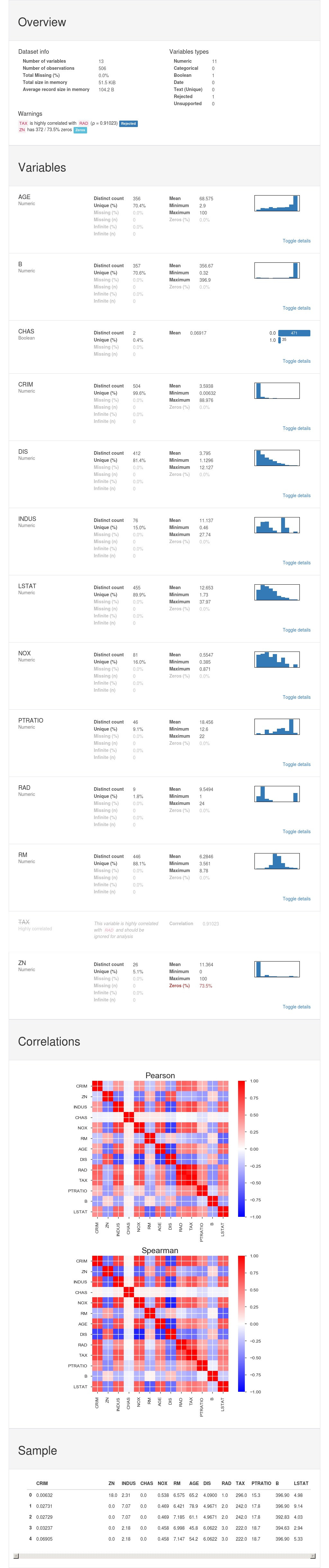
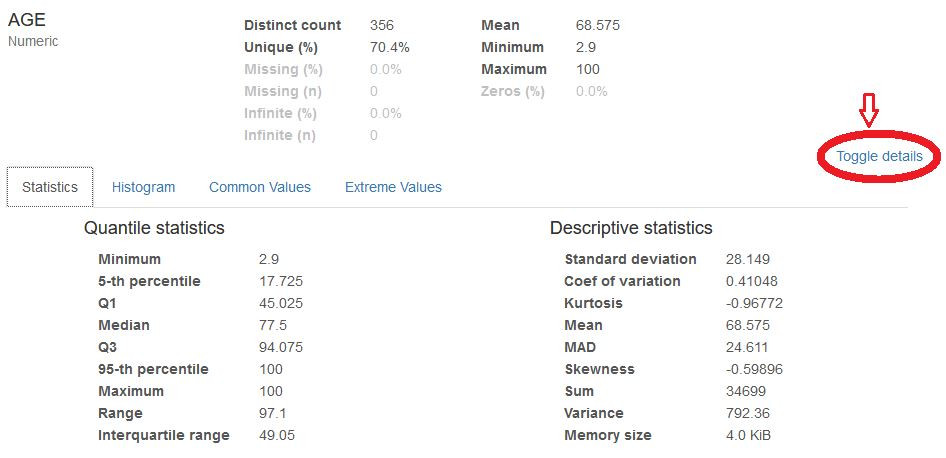
點進去可以看detail
 蜻蜓
蜻蜓
