首先,讓我們接續上篇......
不了,不接續了,我先不去踩TFRecord的坑...
今天先用小的資料集來看一看股票的特性。
首先會先介紹在keras中的LSTM layers用法,需要什麼樣的input和output。
我找了網路上的範例下來改一改,再來針對同一個模型進行以下幾點測試:
今天也會使用更小的dataset :: Google_Stock_Price dataset
$kaggle datasets download akram24/google-stock-price-test
$unzip google-stock-price-test.zip
$rm google-stock-price-test.zip
$kaggle datasets download akram24/google-stock-price-train
$unzip google-stock-price-train.zip
$rm google-stock-price-train.zip
LSTM是一個RNN的延伸模型,架構我不會提,在這主要探討如何使用keras中的LSTM
keras.layers.LSTM的輸入參數最主要有三個必須注意
在使用的過程中,輸入必為3維資料,分別代表batch、time steps以及input data。
而input data幾維那是它的事情,反正給LSTM就要長這樣 : [batck, time, input]。
其中:
筆數。時間維度,在股票如果要藉由前30天的資料預測,則time step為30。
LSTM輸出會根據return_sequences參數而定。當為True,則為many-to-many。False則many-to-one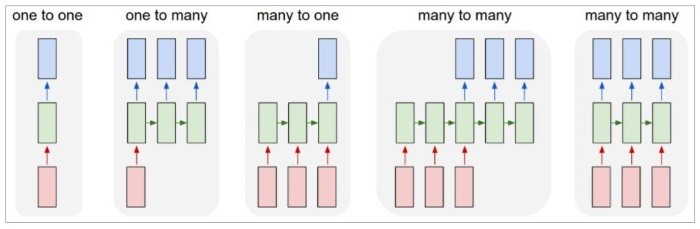
其中,many-to-one的輸出是2維的,也就是說,如果想要搭架多層的LSTM模型,則中間都必須是many-to-many,或是要自己經過特殊處理
非常滴簡單,只差在下方網路LSTM後是否有Flatten layers而已
Layer (type) Output Shape Param #
=================================================================
lstm_4 (LSTM) (None, 50) 10400
_________________________________________________________________
dense_1 (Dense) (None, 128) 6528
_________________________________________________________________
dense_2 (Dense) (None, 40) 5160
_________________________________________________________________
dense_3 (Dense) (None, 3) 123
=================================================================
Total params: 22,211
Trainable params: 22,211
Non-trainable params: 0
今天使用的dataset表小,也沒有
adj_price的資料,所以我改使用Open資料。
當然,也可以使用Close資料,你可以去用看看XD 會遇到BUG,是可以修復的BUG但...
我不想修
好滴~讓我們來看看這個dataset長什麼樣子吧!
Open的資料:

所以目標明確吧! 我們希望前面的1258天去預測最後的20天
在這邊使用正規化的方式是參照範例,直接使用minMaxScaler方式,直接對所有的training data正規到0-1
| 測試編號 | Flatten | loss | 輸入天數 | batch_size | result |
|---|---|---|---|---|---|
| 01 | 否 |  |
60 | 100 |  |
| 02 | 否 |  |
45 | 100 |  |
| 03 | 否 |  |
75 | 100 |  |
| 04 | 是 |  |
60 | 100 |  |
| 05 | 是 |  |
45 | 100 |  |
| 06 | 是 |  |
75 | 100 |  |
| 07 | 是 |  |
60 | 50 |  |


其實我是知道的...我知道的...只用Open資料怎麼可能可以Fit得好?
我絕對沒有認為它能一次就好,真的沒有,我說真的喔!真的! (好了可以不要強調了
不會啊,至少線有在逼近~應該很不錯吧?
: 這種問題才不會有人問哩
我 : 剛看到結果的時候我就是TM這麼認為的
這結果仔細一想,就只是個馬後炮啊!
歷史都已經上漲了,你的預測還晚幾天才漲?
這已經不是預測了吧! 這是慢半拍吧!
冷靜,先冷靜...
讓我們先回歸正題,先不談論結果,先從資料討論
我們所感興趣的應該是「明天的股票會不會上漲」或是「會上漲多少幅度」之類的問題。
當然說如果能預測出明天股價,不就可以知道是否上漲了嗎? ...是啦~
但是考慮模型的學習力,如果我們把股票價格當作我們的目標,那麼在不同間公司的訓練該怎麼辦?
每間公司有他們的漲跌幅才對吧?
那就每間公司的資料分開正規化呢?
乍看非常合理,但以台灣舉例,剛上市的公司與老牌公司(如台積電)比,股市浮動可能大些,這些因素都可能導致模型無法收斂,各個公司應該要有他們自己的漲跌幅,所以如果要這麼做,只能去為某間公司量身打造一個模型比較合理。
從整體的Dataset可以看出,Testing Data位於最後的那個位置是整個股票曲線的高點。
如果根據正常程序正規化,則那個位置的股票很可能造成預測結果接近1(0.8 - 0.9附近)
此時如果我們往後看更多的歷史資料(如全看而非前60天),這個預測肯定會有問題。
一條日K線是由四個資料組成(開盤、收盤、高峰、低峰),而我目前只有使用開盤價而已
難道我都使用下去就可以了嗎?
答案可想,非常困難 。因為外在因素非常得多,包含交易量、大環境、國家元首一句話、資源問題、天災等等都可以是影響因素。
照你這麼說,那根本無從預測啊!
我也這麼想呵呵,那我鐵人就到這...
沒有啦~我還是有想要測試的東西
能做的事情還滿多的~
我還有一個最後的測試並沒有打在上面(因為不知道30天內碰不碰得到
拭目以待~
Understanding Input and Output shapes in LSTM | Keras
The Unreasonable Effectiveness of Recurrent Neural Networks
最後的程式碼


 iThome鐵人賽
iThome鐵人賽