今天跟別人介紹我的文章,才發現我因為瀏覽率很低所以比較後面,差點找不到QQ
內容不吸引人,加上其他人寫的編排跟講解都跟我不同檔次(我要加油!!)
不過我本來就是紀錄學習的自我挑戰者
而且頁面只要重新整理就瀏覽數+1
難道沒有人拿自動化來洗瀏覽率嗎
(推論時間)
假設selenium開啟到頁面並按下重新整理 要5秒好了 設個time sleep 3秒
也就是每8秒刷一次,一個月 2592000秒
2592000/8=324000 這樣刷一個月就32萬 再除以30篇文章 每篇就有一萬多
應該30篇都在第一(誤xD) 不過我不是要投機是要好好把握時間
第一天有講到 自動化其實是為了減低成本,與人力
今天提的的生活案例像是
每天都有看不完的帳需要看有沒有平、或是看材料有無錯誤的良率
可以直接透過自動化來觀察,那如何實現呢?
簡單來看可以利用排程、觸發batch檔 、然後呼叫我們寫的程式
那程式內容當然就是做邏輯的判斷
所以要先來分享一下python中重要的套件 pandas 中的DataFrame
說到這感覺就弱了,Numpy、Pandas應該是大家學python 最熟悉的
但還是分享一下
這裡面有一種循列走訪的方式 iterrow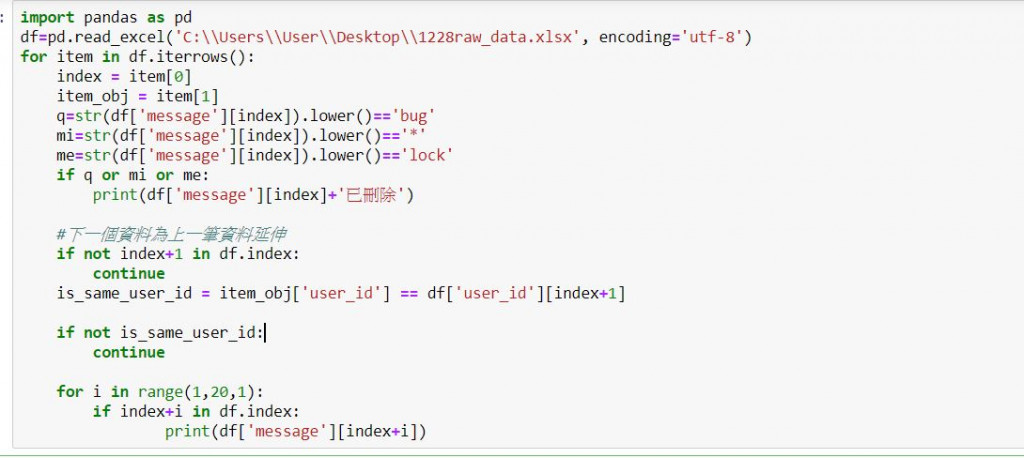
要用什麼套件就要import 進來
import pandas as pd
(如果出現找不到這個套件 就代表必須要 pip install pandas 一下 確認是否有裝)
接下來我們讀excel檔進來組成DataFrame表格,如果是csv檔 可以改寫read_csv
df=pd.read_excel('C:\Users\User\Desktop\1228raw_data.xlsx', encoding='utf-8')
利用迴圈走訪我們所有的表格內容
for item in df.iterrows()for item in df.iterrows():
會有索引 跟值
index = item[0]
item_obj = item[1]
假設我們內容有針對錯誤記錄成bug、lock、或 *
我們則要定義這規則
並把當筆刪除 或keep起來
q=str(df['message'][index]).lower()=='bug'
mi=str(df['message'][index])=='*'
me=str(df['message'][index]).lower()=='lock'
if q or mi or me:
print(df['message'][index]+'已刪除')
下一個資料為上一筆資料延伸
我們則跳過
is_same_user_id = item_obj['user_id'] == df['user_id'][index+1]
if is_same_user_id:
continue
若是有區塊性 像是同一筆資料在一個時間序列中夾雜其他資料則可以跑range方式來抓取
for i in range(1,20,1):
if index+i in df.index:
print(df['message'][index+i])
python讀資料就是這麼方便!!
明天可能用vbscript 寫一次 畢竟虛擬機跑vbscript比較順一點


 iThome鐵人賽
iThome鐵人賽