使用 pip 安裝
# 輸出紀錄
pip install loguru
# HTTP / HTTPS
pip install requests
# 字元編碼判斷
pip install chardet
在 Python 程式開發或後續執行過程中,開發者經常會使用 print 輸出紀錄,但這樣容易在大量紀錄輸出時,受限於 Terminal 的緩衝空間大小,難以保存完整記錄,從而忽略錯誤及問題關聯性。因此筆者推薦使用 loguru 套件輸出 log,美觀且方便。
import datetime
import loguru
# 設定程式記錄除了輸出到 Terminal,還要輸出到紀錄檔案
# 輸出檔案規則
# [1] 一天保存一份紀錄檔案
# [2] 清除超過七天以上的紀錄檔案
# [3] 保存權重在 DEBUG 以上的紀錄
loguru.logger.add(
f'{datetime.date.today():%Y%m%d}.log',
rotation='1 day',
retention='7 days',
level='DEBUG'
)
# TRACE
# 權重 5
loguru.logger.trace('<message>')
# DEBUG
# 權重 10
loguru.logger.debug('<message>')
# INFO
# 權重 20
loguru.logger.info('<message>')
# SUCCESS
# 權重 25
loguru.logger.success('<message>')
# WARNING
# 權重 30
loguru.logger.warning('<message>')
# ERROR
# 權重 40
loguru.logger.error('<message>')
# CRITICAL
# 權重 50
loguru.logger.critical('<message>')
在 Terminal 和紀錄檔都是以如下格式輸出資料(在 Terminal 中支援標色輸出)
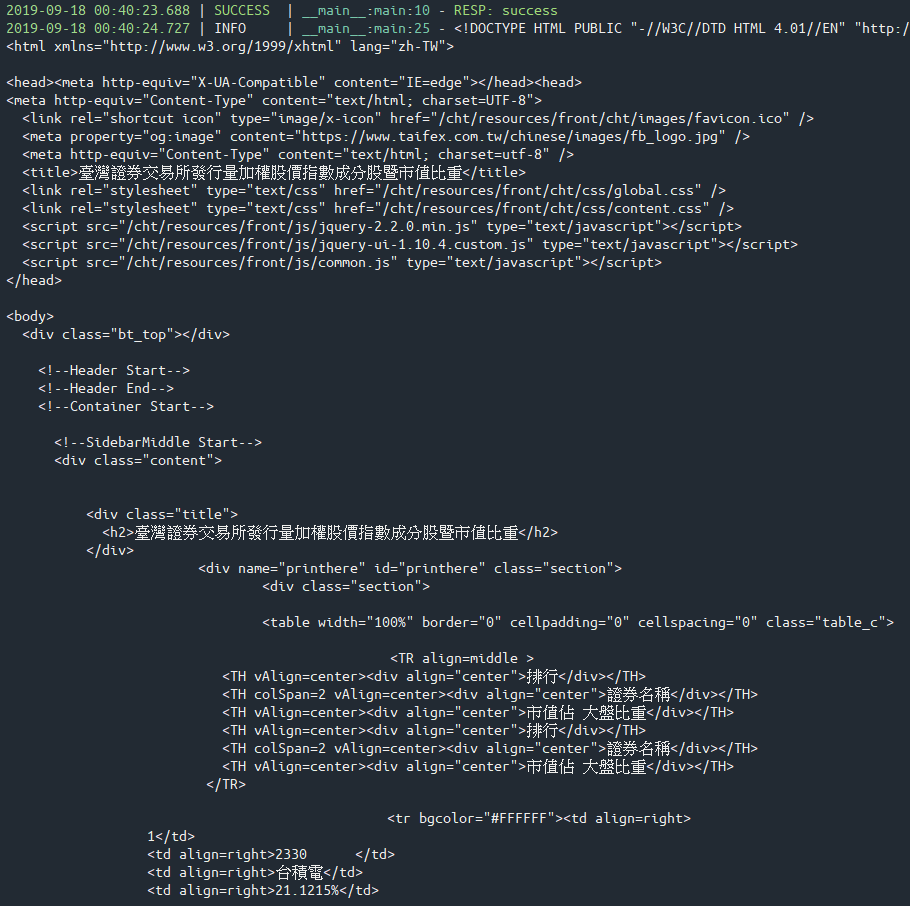
以取得加權指數成分股暨市值比重資料為例。
import datetime
import loguru
import requests
def main():
# 下載加權指數成分股暨市值比重資料網頁
resp = requests.get('https://www.taifex.com.tw/cht/9/futuresQADetail')
# 從 HTTP / HTTPS 回應狀態碼判斷是否下載成功
if resp.status_code != 200:
loguru.logger.error('RESP: status code is not 200')
# 執行到這裡,resp 裡存放的就是 HTTPS 回應,裡面包含回應的標頭和內容主體等資訊
loguru.logger.success('RESP: success')
if __name__ == '__main__':
loguru.logger.add(
f'{datetime.date.today():%Y%m%d}.log',
rotation='1 day',
retention='7 days',
level='DEBUG'
)
main()
因為政府機關不少系統還停留在早年的字集 BIG5,甚至有延伸字集 BIG5-HKSCS,所以下載來自於政府機關網頁的文字資料時,都建議對內容進行編碼判斷,避免解讀出現亂碼。
import datetime
import chardet
import loguru
import requests
def main():
resp = requests.get('https://www.taifex.com.tw/cht/9/futuresQADetail')
if resp.status_code != 200:
loguru.logger.error('RESP: status code is not 200')
loguru.logger.success('RESP: success')
txt = None
# 對 HTTP / HTTPS 回應的二進位原始內容進行編碼判斷
det = chardet.detect(resp.content)
# 捕捉編碼轉換例外錯誤
try:
# 若判斷結果信心度超過 0.5
if det['confidence'] > 0.5:
# 若編碼判斷是 BIG5
if det['encoding'] == 'big-5':
# 因 Python 的 BIG5 編碼標示為 big5,
# 而非 chardet 回傳的 big-5,故需另外處理
txt = resp.content.decode('big5')
else:
txt = resp.content.decode(det['encoding'])
else:
# 若判斷信心度不足,則嘗試使用 UTF-8 解碼
txt = resp.content.decode('utf-8')
except Exception as e:
# 解碼失敗
loguru.logger.error(e)
# 解碼失敗無法取得有效文字內容資料
if txt is None:
return
loguru.logger.info(txt)
if __name__ == '__main__':
loguru.logger.add(
f'{datetime.date.today():%Y%m%d}.log',
rotation='1 day',
retention='7 days',
level='DEBUG'
)
main()
https://loguru.readthedocs.io/en/stable/api/logger.html
https://2.python-requests.org/
https://chardet.readthedocs.io/
團隊系列文:
CSScoke - 金魚都能懂的這個網頁畫面怎麼切 - 金魚都能懂了你還怕學不會嗎
Clarence - LINE bot 好好玩 30 天玩轉 LINE API
Hina Hina - 陣列大亂鬥
King Tzeng - IoT沒那麼難!新手用JavaScript入門做自己的玩具
Vita Ora - 好 Js 不學嗎 !? JavaScript 入門中的入門。
TaTaMo - 用Python開發的網頁不能放到Github上?Lektor說可以!!

