
下章節一堆Lab在想要怎麼呈現,基本上都是照著上面操作就能完整執行了,而且也都是很簡單的東西。
這章節承接上前面"機會平等"的內容概念,討論當資料根據某種特徵(e.g.種族、性別、年齡...)被分成不同組時,或許不應該用相同標準\閥值去衡量,反之,不同的閥值才能讓利益最大化,也能達到"機會平等"的目的。
我自己的理解,如果用工廠運作來思考,每條產線可能因為"機差"緣故,我們訓練出來用於檢測產品好壞的模型,在固定使用相同模型的檢測前提之下,可能需要用不同的閥值標準給予產品是否合格通過檢測。當然,若根據不同資料集去訓練多個模型,或許也能處理這項問題,但有時候侷限於資料量的取得或者其他原因時,採取不同閥值的策略或許更加簡單。
以上是我對 3.3, 3.4 兩小節的理解,不確定是否符合這兩堂課想表達的內涵。
這章節介紹一款Google開發的視覺化開源軟體Facets,影片中展示兩項非常實用且強大的功能: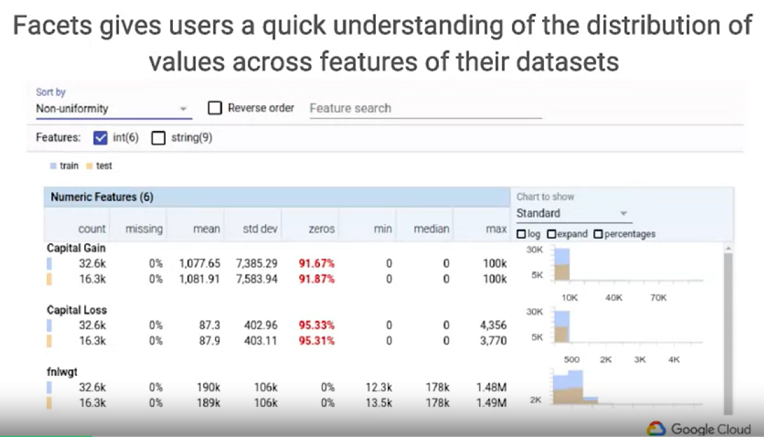
1.Overview:
此功能非常清楚的顯示出各項數值的統計數據,並且用直方圖視覺化顯示出其分布情形。
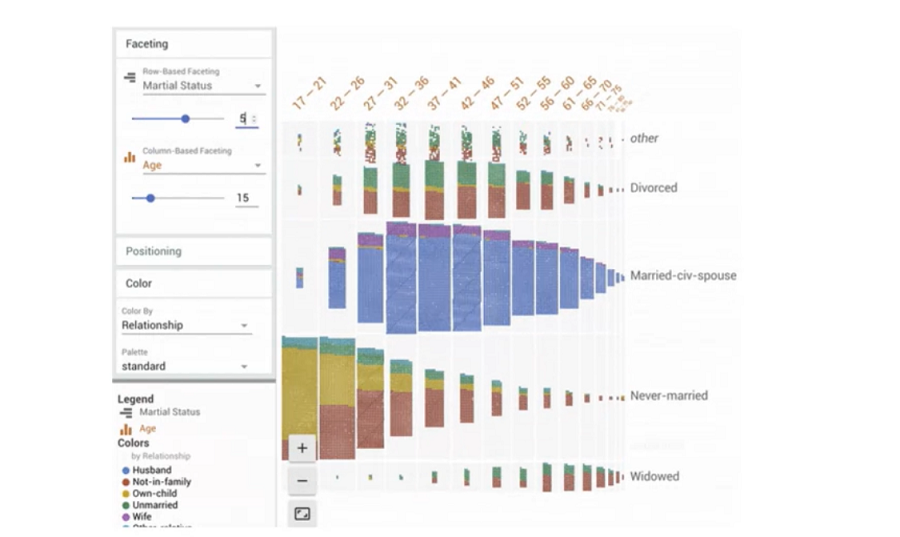
2.Dive:
此功能非常強大,用視覺化的方式去表現各特徵(feature)間的關聯性,對於資料清理時的特徵選幫助很大。最後,測試的實例中,還有用confusion matrix的形式來呈現預測(prediction)與實際標籤(label),甚至因此找出dataset內的錯誤。
總體而言,使用這套開源軟體能解決許多問題,迅速掌握資料集的特性,而且也不需要花時間寫一堆程式,就能進行許多統計數值的計算與檢驗,減少許多資料處理走的冤枉路。
這整大章節多著墨在處理dataset的技巧與注意事項,這件事情也是前面一再強調Machine Learning Project中,需要耗費許多時間的程序。畢竟,資料對於機器學習模型就像是血液,若注入的血液越乾淨,產生的模型也能更準確。這部分的內容對於原本單純從事演算法相關研究的人應該非常有幫助,因為Data Scientist, Data Engineer在職務上本身就有差異,藉由這章節了解更多資料處理部分的議題,互相了解彼此工作上會遇到的挑戰。

 iThome鐵人賽
iThome鐵人賽