
看來又要拖到part5
這章節我重複看了很多次的,卻還是不太能夠完全理解內容。
單從主題上"Equality of Opportunity"(機會均等)來看,想要表達的意思應該是希望藉由一些技巧,防止Machine Learning模型,因為資料而產生歧視。然而,前面一整段鋪陳所舉的關於信用借貸的例子,似乎又與主題不太相關。
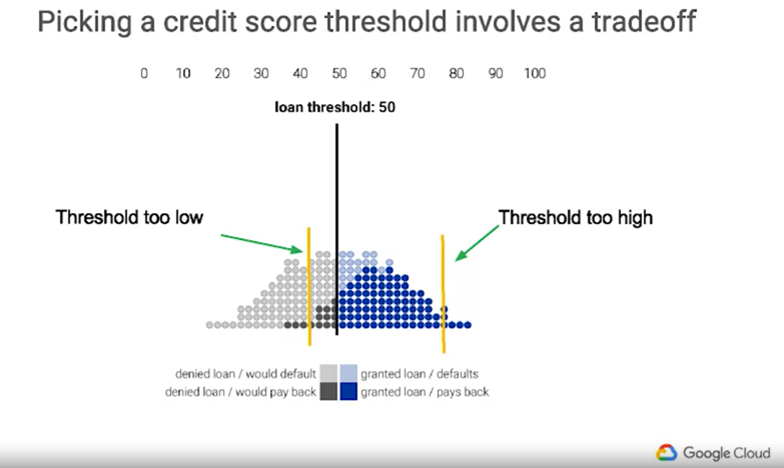
根據上圖,可以分成兩種顏色(藍色\灰色)與(深\淺)總共四類,兩種顏色分別代表在信用基準的閥值選擇50時,藍色是被允許借貸、灰色則是不被允許借貸,深色\淺色則是實際會還錢\不會還錢,在現實的資料分布中,很難找到一筆閥值能夠完美將還錢與不還錢的人分隔出來,因此,要如何選擇閥值便成了一門學問!
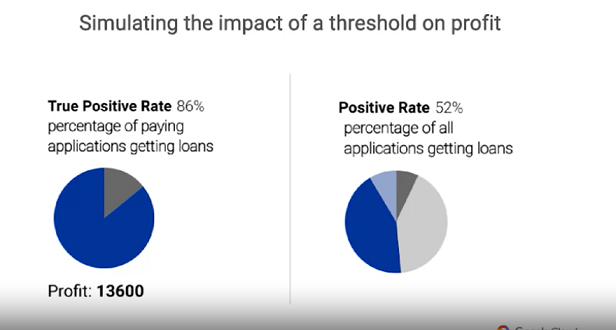
於是,Google提出一種方向,或許能根據可能獲得的最大利益進行閥值選擇。
最後,又很生硬的牽扯到"機會均等"的思維,我理解後認為的主要概念是,針對某些特徵進行分組(e.g.人種、性別、年齡...),讓不同特徵的人能夠有均等的機會(在這例子中就是獲得借貸)。然而,整體上這段課程的安排邏輯順序,讓我有點無法對此概念有深刻理解,而且最後的解釋不知道是我英文太差,或者真的他解釋的很抽象不清楚,感覺沒有抓到重點。

 iThome鐵人賽
iThome鐵人賽