在上一篇文章中,我們討論了如何啟用(enable) Eager mode,而得以靈活的使用 numpy.ndarray於 tf.Tensor中,而不需要如在 Graph mode 中,使用 tf.Session 來進行資料的餵送。
今天我們要介紹一個目前由 google maintain 的開源函式庫,Jax。這個函式庫的前身是 Autograd,一個完全用 python 寫成的自動微分函式庫。
Autograd 就像是 PyTorch 的 autograd module,但在這裡沒有另外生成 Tensor 物件。Autograd 所需要的就是由使用者提供具有計算邏輯的函式,接著使用模組階級的 grad 函式來生成另一個計算梯度的函式。grad內部運作的方式則是:
下圖為官方提供的 Jax 流程。
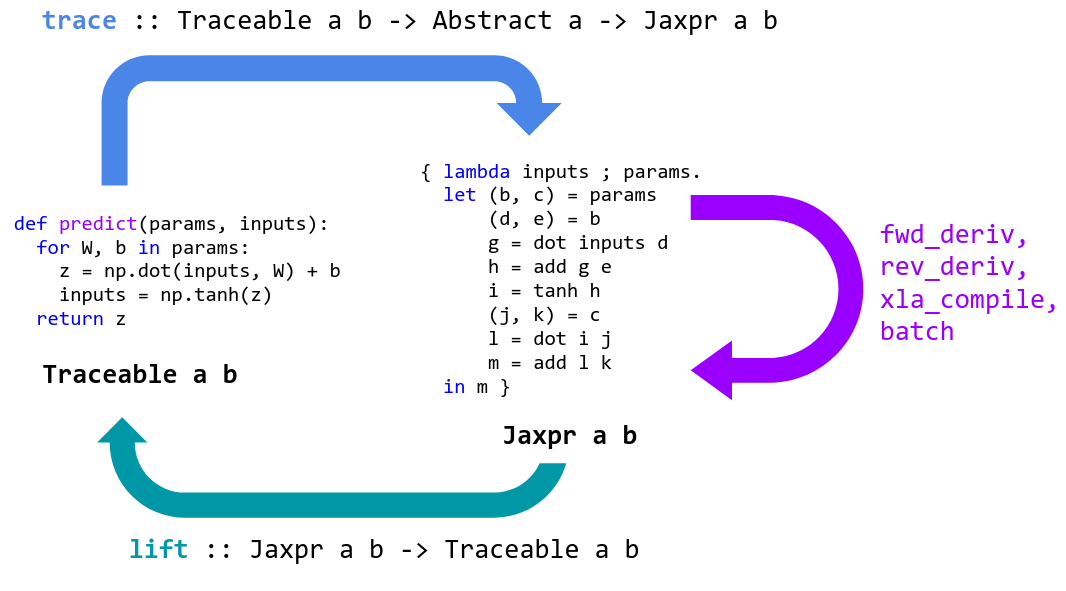
我們可以用一個簡單的例子來解說如何使用 jax.grad,以下是 logistic regression 的例子:
import jax.numpy as np # Thinly-wrapped version of Numpy
from jax import grad
def sigmoid(x):
return 0.5 * (np.tanh(x / 2.) + 1) # sigmoid function for binary classification
def logistic_predictions(weights, inputs):
# Outputs probability of a label being true according to logistic model.
return sigmoid(np.dot(inputs, weights))
def training_loss(weights, targets):
# Training loss is the negative log-likelihood of the training labels.
preds = logistic_predictions(weights, inputs)
# cross-entropy for binary cases
label_probabilities = preds * targets + (1 - preds) * (1 - targets)
return -np.sum(np.log(label_probabilities))
# Build a toy dataset.
inputs = np.array([[0.52, 1.12, 0.77], # x
[0.88, -1.08, 0.15],
[0.52, 0.06, -1.30],
[0.74, -2.49, 1.39]])
targets = np.array([True, True, False, True]) #y
# Define a function that returns gradients of training loss using Autograd.
training_gradient_fun = grad(training_loss)
# Optimize weights using gradient descent.
weights = np.array([0.0, 0.0, 0.0]) # giving initial values
print("Initial loss:", training_loss(weights, targets))
for i in range(100):
weights -= training_gradient_fun(weights, targets) * 0.01 #gradient descent
print("Trained loss:", training_loss(weights, targets))
#Initial loss: 2.7725887
#Trained loss: 1.0672708
要注意的是,傳入 grad 函式的 signature 改變,則產出計算梯度函式的 signature 也要跟著改變。意思就是,若將最終運算 def training_loss(weights): 改為 def training_loss(weights, , targets): ,則 training_gradient_fun 在呼叫時也要用 training_gradient_fun(weights, , targets) 不然會出現一個有講等於沒講的錯誤訊息:
TypeError: training_loss() missing 1 required positional argument: 'targets'
都用 numpy 來計算梯度,似乎是一件很方便的事,但是對於講究大量資料,高速運算的今日來看,只能存活在主記憶內,僅能使用 CPU 運算,確實是一件很遜的事。所以,就有了 Jax 的出現!其實 Jax 就是
Jax = Autograd + XLA
XLA 是 google 自家的 just-in-time (jit) 編譯器,主要針對線性代數的部分進行加速。透過 jit 編譯器來編譯 python 原始碼已經不是新鮮事,Numba 就是使用 llvm 來完成 python 的 byte code。然而 python 的原始碼透過 XLA 編譯成機械碼後,可以配置到 GPU 甚至到 TPU 上面。下圖就是取自官方網站,透過 XLA 編譯後的原始碼,會加快 1 到 1.15 倍的速度。

至於如何使用,就來看以下例子:
grad_fun = jit(grad(logprob_fun)) # compiled gradient evaluation function
#with XLA compiled gradient function
#70.7 ms ± 1.33 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
#plain grad
#856 ms ± 6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
許多人都對 Jax 引頸盼望,希望 Jax 可以被納入在 Tensorflow 2.0,至少對我而言,**Eager Mode **,造成需要寫需多 if...else...,來測試是否在 Eager Mode 內,所以還真不是普通的不好用。對於廣大的 python 使用者,Jax 可說是福音。有興趣的人,可以到 reference 內閱讀官方文件。
1 Autograd github repo
2.Jax github repo
3.XLA


 iThome鐵人賽
iThome鐵人賽