使用 pip 安裝
# 解析 JavaScript 程式碼
pip install js2py
為了避免因頻繁存取被目標網站封鎖,必須透過不斷變換代理進行存取,因此我們先從網路搜尋可免費使用的 IP 代理清單網站,如下所列:

我們可以觀察到第一筆代理的 IP 是 61.220.204.25,但在原始碼中卻無法搜尋到,改以後面的 3128 進行搜尋,發現該網站以特殊的方式對 IP 進行保護。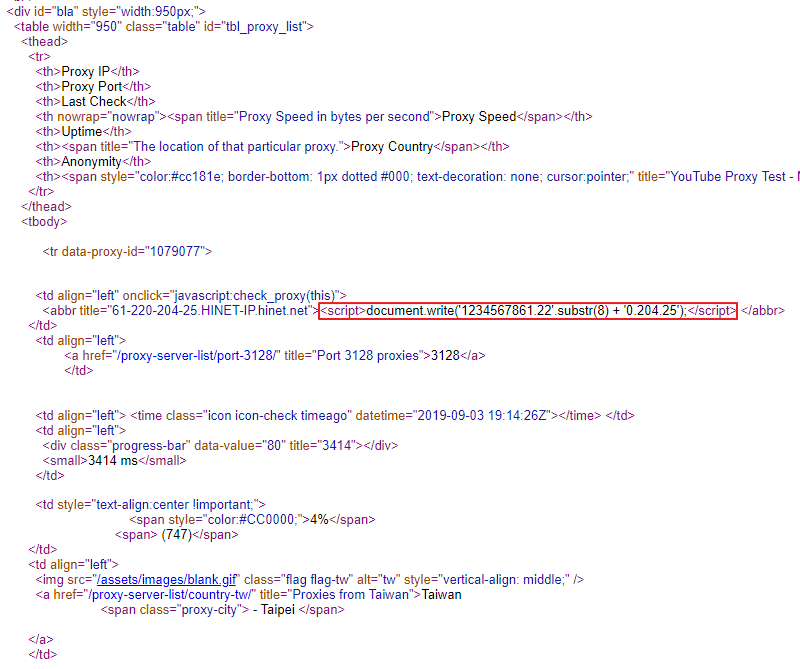
如紅框部分所示,按照 JavaScript 語法推斷,去掉 1234567861.22 字串前 8 個字元後接上 0.204.25 字串即為所需的 IP。
為了因為網站更改 JavaScript 截取字串的位置導致解法失效,故導入 js2py 讓 JavaScript 語法可自動執行回傳正確的結果。
import time
import js2py
import loguru
import pyquery
import requests
def getProxiesFromProxyNova():
proxies = []
# 按照網站規則使用各國代碼傳入網址取得各國 IP 代理
countries = [
'tw',
'jp',
'kr',
'id',
'my',
'th',
'vn',
'ph',
'hk',
'uk',
'us'
]
for country in countries:
url = f'https://www.proxynova.com/proxy-server-list/country-{country}/'
loguru.logger.debug(f'getProxiesFromProxyNova: {url}')
loguru.logger.warning(f'getProxiesFromProxyNova: downloading...')
response = requests.get(url)
if response.status_code != 200:
loguru.logger.debug(f'getProxiesFromProxyNova: status code is not 200')
continue
loguru.logger.success(f'getProxiesFromProxyNova: downloaded.')
d = pyquery.PyQuery(response.text)
table = d('table#tbl_proxy_list')
rows = list(table('tbody:first > tr').items())
loguru.logger.warning(f'getProxiesFromProxyNova: scanning...')
for row in rows:
tds = list(row('td').items())
# 若為分隔行則僅有 1 格
if len(tds) == 1:
continue
# 取出 IP 欄位內的 JavaScript 程式碼
js = row('td:nth-child(1) > abbr').text()
# 去除 JavaScript 程式碼開頭的 document.write( 字串與結尾的 ); 字串,
# 再與可供 js2py 執行後回傳指定變數的 JavaScript 程式碼相結合
js = 'let x = %s; x' % (js[15:-2])
# 透過 js2py 執行取得還原後的 IP
ip = js2py.eval_js(js).strip()
# 取出 Port 欄位值
port = row('td:nth-child(2)').text().strip()
# 組合 IP 代理
proxy = f'{ip}:{port}'
proxies.append(proxy)
loguru.logger.success(f'getProxiesFromProxyNova: scanned.')
loguru.logger.debug(f'getProxiesFromProxyNova: {len(proxies)} proxies is found.')
# 每取得一個國家代理清單就休息一秒,避免頻繁存取導致代理清單網站封鎖
time.sleep(1)
return proxies

我們可以觀察到第一筆代理的 IP 是 185.190.105.179,在原始碼中搜尋到後,發現該網站以特殊的方式對 IP 進行保護。
如圖中所示,在 gp.insertPrx 函數中傳入的參數物件,裡面就包含我們所需要的代理資料,但 Port 是以 16 進位表示法表示。
import re
import time
import urllib.parse
import json
import loguru
import pyquery
import requests
def getProxiesFromGatherProxy():
proxies = []
# 按照網站規則使用各國國名傳入網址取得各國 IP 代理
countries = [
'Taiwan',
'Japan',
'United States',
'Thailand',
'Vietnam',
'Indonesia',
'Singapore',
'Philippines',
'Malaysia',
'Hong Kong'
]
for country in countries:
url = f'http://www.gatherproxy.com/proxylist/country/?c={urllib.parse.quote(country)}'
loguru.logger.debug(f'getProxiesFromGatherProxy: {url}')
loguru.logger.warning(f'getProxiesFromGatherProxy: downloading...')
response = requests.get(url)
if response.status_code != 200:
loguru.logger.debug(f'getProxiesFromGatherProxy: status code is not 200')
continue
loguru.logger.success(f'getProxiesFromGatherProxy: downloaded.')
d = pyquery.PyQuery(response.text)
scripts = list(d('table#tblproxy > script').items())
loguru.logger.warning(f'getProxiesFromGatherProxy: scanning...')
for script in scripts:
# 取出 script 標簽中的 JavaScript 原始碼
script = script.text().strip()
# 去除 JavaScript 程式碼開頭的 gp.insertPrx( 字串與結尾的 ); 字串
script = re.sub(r'^gp\.insertPrx\(', '', script)
script = re.sub(r'\);$', '', script)
# 將參數物件以 JSON 方式解析
script = json.loads(script)
# 取出 IP 欄位值
ip = script['PROXY_IP'].strip()
# 取出 Port 欄位值,並從 16 進位表示法解析為 10 進位表示法
port = int(script['PROXY_PORT'].strip(), 16)
# 組合 IP 代理
proxy = f'{ip}:{port}'
proxies.append(proxy)
loguru.logger.success(f'getProxiesFromGatherProxy: scanned.')
loguru.logger.debug(f'getProxiesFromGatherProxy: {len(proxies)} proxies is found.')
# 每取得一個國家代理清單就休息一秒,避免頻繁存取導致代理清單網站封鎖
time.sleep(1)
return proxies

我們可以觀察到第一筆代理的 IP 是 109.101.139.106,在原始碼中搜尋到後,發現該網站並無以特殊的方式對 IP 進行保護。
如圖中所示,可直接從表格中取出所需代理資料。
import time
import loguru
import pyquery
import requests
def getProxiesFromFreeProxyList():
proxies = []
url = 'https://free-proxy-list.net/'
loguru.logger.debug(f'getProxiesFromFreeProxyList: {url}')
loguru.logger.warning(f'getProxiesFromFreeProxyList: downloading...')
response = requests.get(url)
if response.status_code != 200:
loguru.logger.debug(f'getProxiesFromFreeProxyList: status code is not 200')
return
loguru.logger.success(f'getProxiesFromFreeProxyList: downloaded.')
d = pyquery.PyQuery(response.text)
trs = list(d('table#proxylisttable > tbody > tr').items())
loguru.logger.warning(f'getProxiesFromFreeProxyList: scanning...')
for tr in trs:
# 取出所有資料格
tds = list(tr('td').items())
# 取出 IP 欄位值
ip = tds[0].text().strip()
# 取出 Port 欄位值
port = tds[1].text().strip()
# 組合 IP 代理
proxy = f'{ip}:{port}'
proxies.append(proxy)
loguru.logger.success(f'getProxiesFromFreeProxyList: scanned.')
loguru.logger.debug(f'getProxiesFromFreeProxyList: {len(proxies)} proxies is found.')
return proxies
http://piter.io/projects/js2py
團隊系列文:
CSScoke - 金魚都能懂的這個網頁畫面怎麼切 - 金魚都能懂了你還怕學不會嗎
Clarence - LINE bot 好好玩 30 天玩轉 LINE API
Hina Hina - 陣列大亂鬥
King Tzeng - IoT沒那麼難!新手用JavaScript入門做自己的玩具
Vita Ora - 好 Js 不學嗎 !? JavaScript 入門中的入門。
TaTaMo - 用Python開發的網頁不能放到Github上?Lektor說可以!!


 iThome鐵人賽
iThome鐵人賽