為了避免每次下載代理清單時,因為耗時過久或者頻繁存取導致封鎖,故透過以下方式解決:
本篇需搭配 Day-05 資料蒐集:取得代理清單 已完成的部分才能使用。
import csv
import datetime
import os
import loguru
# 取得模組執行當下時間
now = datetime.datetime.now()
# 透過全域變數共用代理清單
proxies = []
# 下載代理清單
def reqProxies(hour):
global proxies
proxies = proxies + getProxiesFromProxyNova()
proxies = proxies + getProxiesFromGatherProxy()
proxies = proxies + getProxiesFromFreeProxyList()
proxies = list(dict.fromkeys(proxies))
loguru.logger.debug(f'reqProxies: {len(proxies)} proxies is found.')
# 取得代理清單
def getProxies():
global proxies
now = datetome
hour = f'{now:%Y%m%d%H}'
filename = f'proxies-{hour}.csv'
filepath = f'{filename}'
if os.path.isfile(filepath):
# 如果本小時的紀錄檔案存在,直接載入代理清單
loguru.logger.info(f'getProxies: {filename} exists.')
loguru.logger.warning(f'getProxies: {filename} is loading...')
with open(filepath, 'r', newline='', encoding='utf-8-sig') as f:
reader = csv.DictReader(f)
for row in reader:
proxy = row['Proxy']
proxies.append(proxy)
loguru.logger.success(f'getProxies: {filename} is loaded.')
else:
# 如果本小時的紀錄檔案存在,重新下載代理清單並保存
loguru.logger.info(f'getProxies: {filename} does not exist.')
reqProxies(hour)
loguru.logger.warning(f'getProxies: {filename} is saving...')
with open(filepath, 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f)
writer.writerow([
'Proxy'
])
for proxy in proxies:
writer.writerow([
proxy
])
loguru.logger.success(f'getProxies: {filename} is saved.')
為了簡化 3. 4. 5. 的行為,將這三條規則的行為轉換為:
import csv
import datetime
import os
import random
import loguru
now = datetime.datetime.now()
proxies = []
# 隨機取出一組代理
def getProxy():
global proxies
# 若代理清單內已無代理,則重新下載
if len(proxies) == 0:
getProxies()
proxy = random.choice(proxies)
loguru.logger.debug(f'getProxy: {proxy}')
proxies.remove(proxy)
loguru.logger.debug(f'getProxy: {len(proxies)} proxies is unused.')
return proxy
def reqProxies(hour):
global proxies
proxies = proxies + getProxiesFromProxyNova()
proxies = proxies + getProxiesFromGatherProxy()
proxies = proxies + getProxiesFromFreeProxyList()
proxies = list(dict.fromkeys(proxies))
loguru.logger.debug(f'reqProxies: {len(proxies)} proxies is found.')
def getProxies():
global proxies
hour = f'{now:%Y%m%d%H}'
filename = f'proxies-{hour}.csv'
filepath = f'{filename}'
if os.path.isfile(filepath):
loguru.logger.info(f'getProxies: {filename} exists.')
loguru.logger.warning(f'getProxies: {filename} is loading...')
with open(filepath, 'r', newline='', encoding='utf-8-sig') as f:
reader = csv.DictReader(f)
for row in reader:
proxy = row['Proxy']
proxies.append(proxy)
loguru.logger.success(f'getProxies: {filename} is loaded.')
else:
loguru.logger.info(f'getProxies: {filename} does not exist.')
reqProxies(hour)
loguru.logger.warning(f'getProxies: {filename} is saving...')
with open(filepath, 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f)
writer.writerow([
'Proxy'
])
for proxy in proxies:
writer.writerow([
proxy
])
loguru.logger.success(f'getProxies: {filename} is saved.')
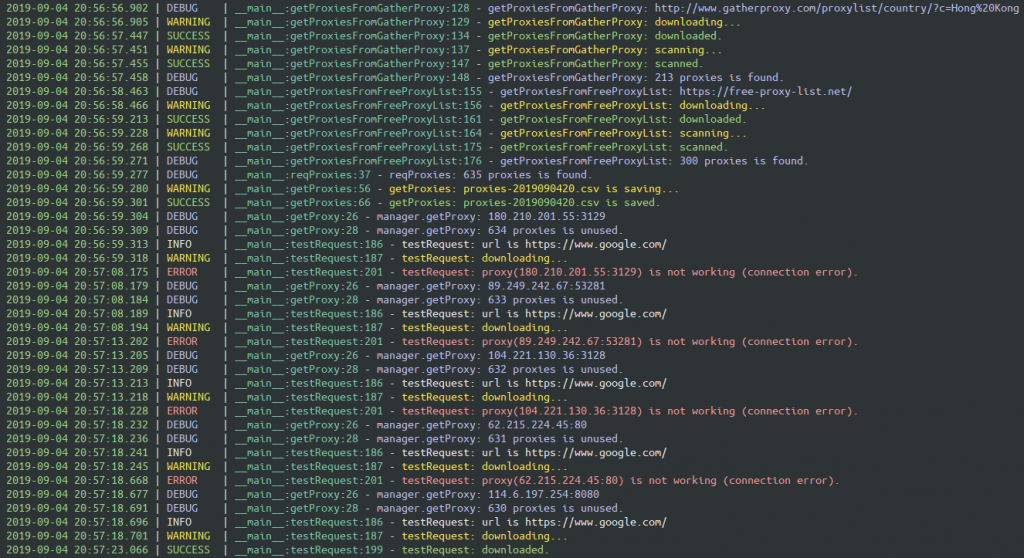
import requests
import requests.exceptions
# 用於保存上一次連線請求成功時用的代理資訊
proxy = None
def testRequest():
global proxy
# 持續更換代理直到連線請求成功為止
while True:
# 若無上一次連線請求成功的代理資訊,則重新取出一組代理資訊
if proxy is None:
proxy = getProxy()
try:
url = f'https://www.google.com/'
loguru.logger.info(f'testRequest: url is {url}')
loguru.logger.warning(f'testRequest: downloading...')
response = requests.get(
url,
# 指定 HTTPS 代理資訊
proxies={
'https': f'https://{proxy}'
},
# 指定連限逾時限制
timeout=5
)
if response.status_code != 200:
loguru.logger.debug(f'testRequest: status code is not 200.')
# 請求發生錯誤,清除代理資訊,繼續下個迴圈
proxy = None
continue
loguru.logger.success(f'testRequest: downloaded.')
# 發生以下各種例外時,清除代理資訊,繼續下個迴圈
except requests.exceptions.ConnectionError:
loguru.logger.error(f'testRequest: proxy({proxy}) is not working (connection error).')
proxy = None
continue
except requests.exceptions.ConnectTimeout:
loguru.logger.error(f'testRequest: proxy({proxy}) is not working (connect timeout).')
proxy = None
continue
except requests.exceptions.ProxyError:
loguru.logger.error(f'testRequest: proxy({proxy}) is not working (proxy error).')
proxy = None
continue
except requests.exceptions.SSLError:
loguru.logger.error(f'testRequest: proxy({proxy}) is not working (ssl error).')
proxy = None
continue
except Exception as e:
loguru.logger.error(f'testRequest: proxy({proxy}) is not working.')
loguru.logger.error(e)
proxy = None
continue
# 成功完成請求,離開迴圈
break
團隊系列文:
CSScoke - 金魚都能懂的這個網頁畫面怎麼切 - 金魚都能懂了你還怕學不會嗎
Clarence - LINE bot 好好玩 30 天玩轉 LINE API
Hina Hina - 陣列大亂鬥
King Tzeng - IoT沒那麼難!新手用JavaScript入門做自己的玩具
Vita Ora - 好 Js 不學嗎 !? JavaScript 入門中的入門。
TaTaMo - 用Python開發的網頁不能放到Github上?Lektor說可以!!

