在昨天的內容中,我們已經了解了基本的 HTML 結構,今天我們來試著剖析網頁原始碼並找出我們需要的資料。
常見剖析 HTML 原始碼的方式有三種:
HTML 處理 XML 處理正則表示式寫起來比較複雜,而且很容易被網站的小改動影響,所以通常我是用後面兩種方式在處理。架構比較好的網站,因為可以用比較簡單的方式就定位到要抓取的資料,一般用 HTML 的方式來處理就可以;而需要比較多判斷條件或額外處理的網頁原始碼,就可能需要用 XML 的方式會比較好處理。
Beautiful Soup(後面會簡稱為 bs4)是最常看到用來操作 HTML 的套件,這邊就來介紹怎麼使用。
今天借用其官網的範例 HTML 來做為範例。
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body>
</html>
我們可以直接在 Python 中宣告一個變數來放範例 HTML 的字串。
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body></html>
"""
pipenv --python 3.7
pipenv shell
pipenv install beautifulsoup4
bs4 使用 Python 標準函示庫中的 html.parser 來剖析 HTML;同時也支援第三方的 lxml 和 html5lib 套件作為剖析器,一般建議使用比較快的 lxml。使用前也需要先安裝套件。
pipenv install lxml
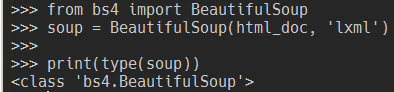
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'lxml')
print(type(soup))
載入後會得到一個 BeautifulSoup 物件,之後會用這個物件來操作 HTML。
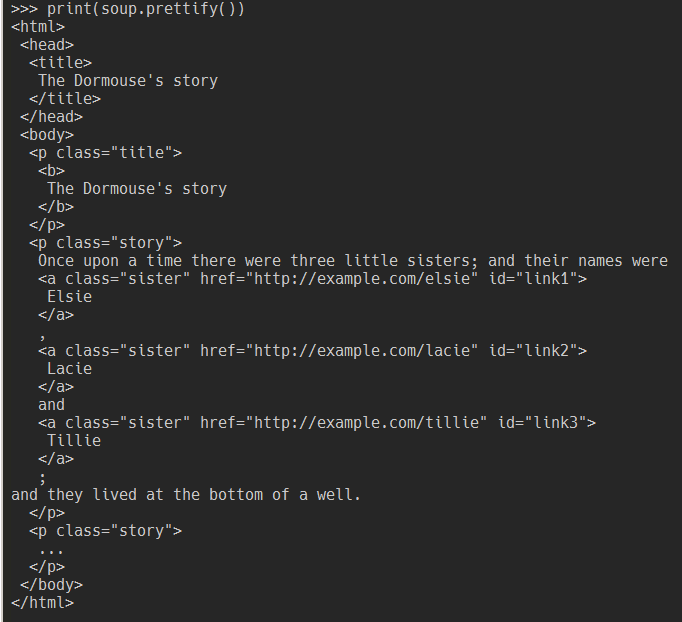
prettify() 方法會回傳剖析器處理完後格式化的字串。
須注意同樣的原始碼在不同剖析器可能會有不同的結果。
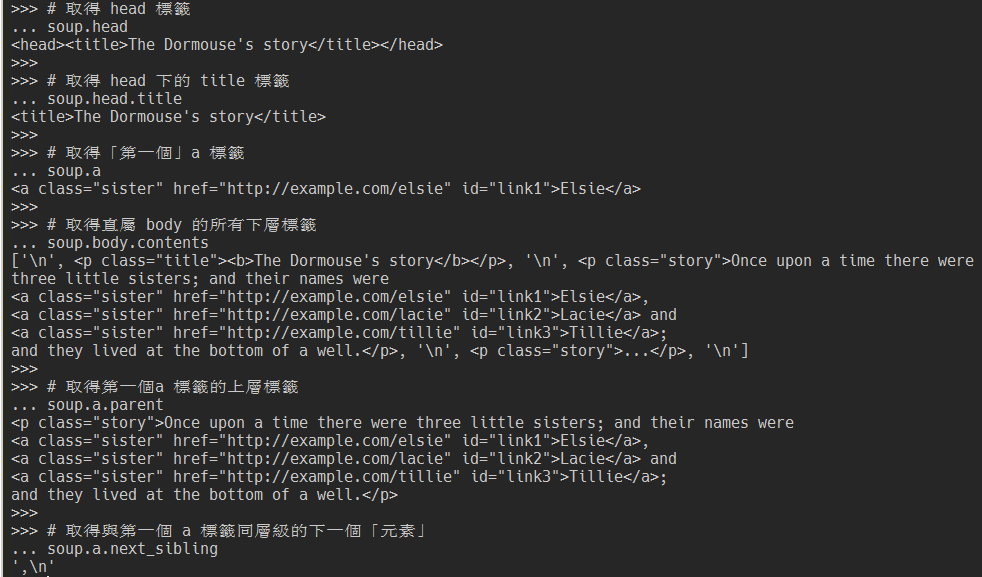
bs4 提供很完整的遍歷方法,這邊介紹幾個常用的,完整版可以參考官方文件。
# 取得 head 標籤
soup.head
# 取得 head 下的 title 標籤
soup.head.title
# 取得「第一個」a 標籤
soup.a
# 取得直屬 body 的所有下層標籤
soup.body.contents
# 取得第一個a 標籤的上層標籤
soup.a.parent
# 取得與第一個 a 標籤同層級的下一個「元素」
soup.a.next_sibling
除了用 . 直接取到節點外,bs4 也提供很多搜尋的方法,但開始之前,得先介紹搜尋方法可使用的各種過濾器(filters)。
# 搜尋標籤 "b"
soup.find_all('b')
# [<b>The Dormouse's story</b>]
search() 方法來搜尋符合的標籤名稱# 搜尋以 "b" 開頭的標籤
import re
for tag in soup.find_all(re.compile("^b")):
print(tag.name)
# body
# b
# 搜尋標籤 "a" 和 "b"
soup.find_all(["a", "b"])
# [<b>The Dormouse's story</b>,
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
def has_class_but_no_id(tag):
""" 判斷標籤是否定義 class 屬性且無定義 id 屬性
"""
return tag.has_attr('class') and not tag.has_attr('id')
soup.find_all(has_class_but_no_id)
# [<p class="title"><b>The Dormouse's story</b></p>,
# <p class="story">Once upon a time there were...</p>,
# <p class="story">...</p>]
bs4 提供很多種搜尋的方法,除了搜尋的對象不同外,參數的使用上是幾乎一樣的,完整版可以參考官方文件。這邊會介紹個人最常用到的 find_all 方法,其方法簽章是:
find_all(name, attrs, recursive, string, limit, **kwargs)
各參數的作用如下:
dict 物件,用屬性來過濾,待會跟 keyword arguments 一起介紹True),用來設定是否要遞迴往下找# 找 html 標籤下的所有標籤
soup.html.find_all("title")
# [<title>The Dormouse's story</title>]
# 只找 html 的「下一層」標籤
# 因為一般 html 下一層只有 head 和 body
# 所以找不到結果
soup.html.find_all("title", recursive=False)
# []
attrs 參數一樣是用屬性來過濾,絕大多數的情況下用 kwargs 就可以,只有一些特殊狀況(保留字、屬性名稱與方法參數名稱相同、kebab-case)會需要用 attrs 參數來處理# 找出 id 屬性值為 link2 的標籤
soup.find_all(id='link2')
# [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
# 用 re 找出 href 屬性值包含 elsie 的標籤
soup.find_all(href=re.compile("elsie"))
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
# 找出有 id 屬性的標籤
soup.find_all(id=True)
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
# 也可以同時使用多個屬性來判斷
soup.find_all(href=re.compile("elsie"), id='link1')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
遇到特殊狀況時:
# 保留字 class
soup.find_all("a", class_="sister")
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
name_soup = BeautifulSoup('<input name="email"/>')
name_soup.find_all(name="email")
# []
name_soup.find_all(attrs={"name": "email"})
# [<input name="email"/>]
# 常用於 HTML5 的 data-* 屬性
data_soup = BeautifulSoup('<div data-foo="value">foo!</div>')
data_soup.find_all(data-foo="value")
# SyntaxError: keyword can't be an expression
data_soup.find_all(attrs={"data-foo": "value"})
# [<div data-foo="value">foo!</div>]
如果過去有接觸前端或者 jQuery 的朋友,應該對 CSS 選擇器很熟悉。bs4 也透過 SoupSieve 支援了大部分的的 CSS 選擇器,只要使用 .select() 或 .select_one() 方法就可以使用 CSS 選擇器來找到目標資料了。
# 找出 body 下的 a 標籤
soup.select('body a')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
# 找出 class 包含 sister 的標籤
soup.select('.sister')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
# 找出 id 是 link2 的標籤
soup.select('#link2')
# [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
# 找出「第一個」class 包含 sister 的標籤
soup.select_one('.sister')
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
在絕大多數的情況下,用 bs4 就可以滿足需求了。如果在定位資料時還有更複雜的需求(現在還真想不起來什麼狀況)時,明天會介紹如何用 XPath 來處理。

