
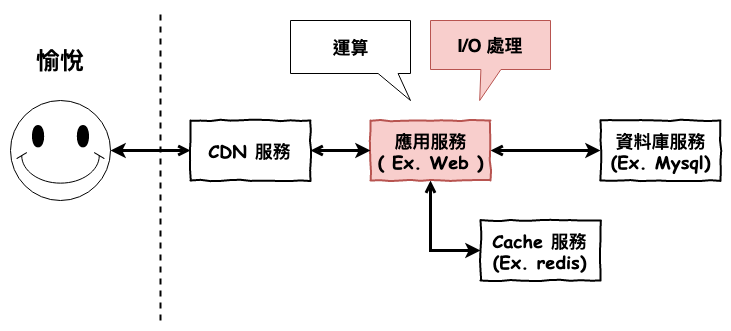
前二篇文章中,咱們已經學習完運算方面的優化,而接下來幾篇文章,咱們要來說明 I/O 優化這個議題。
I/O 基本上可以分為兩種,『 文件 I/O 』與『 網路 I/O 』,這兩種 I/O 操作原理大同小議,但是優化方式卻有些不同,接下來這一篇文章,算是混合。
本篇文章分為以下幾個章節 :
先從最基本的來看,何謂 I/O ?
I/O ( Input/Output) 通常是指資料在『系統』與『外部裝置』的輸入與輸入,最簡單的例子,抓取硬碟或 USB 資料就是所謂的 I/O 操作。
接下來我們簡單的來看一下,在 linux 操作系統上,所謂的『 從硬碟讀取資料,並結果輸出到網路 』到底是在做什麼。
記憶體就是作業系統最基本的資料儲放地,接下來我們從記憶體的層面來看,所謂的『從硬碟讀取資料,並將結果輸出到網路』它是如何變化的。
基本『 讀與寫 』流程如下 :
在看流程前先說明一下,等等到看到的所謂『 緩衝區 』 就是指在某個記憶體中,切割一些空間出來,來當緩衝區。像等等看到的內核緩衝區就是在內核的記憶體中,拿一些空間來儲放等等要進來的資料。
接下來就開始看流程。
順到說一下,這樣的操作總共會進行 4 次的上下文切換。
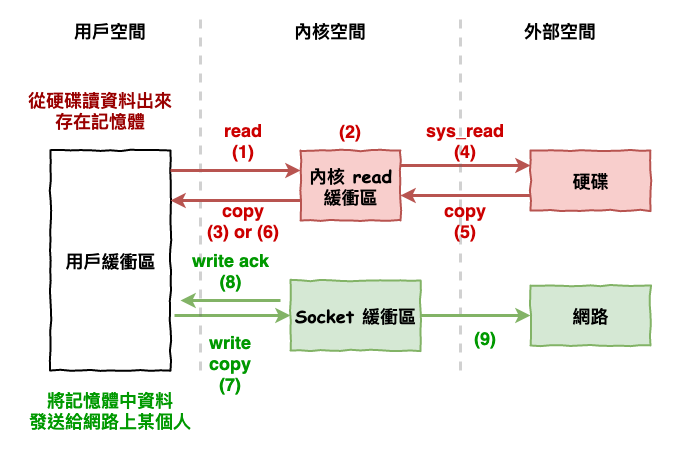
圖 4 : 作業系統 I/O 流程
~ 小知識 ~
read 是 linux 所提供的操作,它可以從 file descriptor 讀取資料,而 fd 是每一次建立檔案或網路連結都會產生的東東。通常我們大部份使用的語言,都有提供呼叫它的接口。
write 也是 linux 所提供的操作,它可以寫入資料至 file descriptor,但這裡有一個重點要注意,它是寫入到內核裡的緩衝區後就會回 ack ,而不是從網路發送出去後,或寫到硬碟後才回 ack 。
以上兩個操作都是所謂的 system call 。
上面理解完 I/O 的一些原理以,就下來我們來看看,能提升效率的地方在那 ?
假設我們有一個操作,它的過程如下 :
從硬碟讀取資料後,直接輸出到網路上 (不需特別處理)。
那這種它的傳統記憶體處理流程如下,就如下圖 5 一樣所示 :
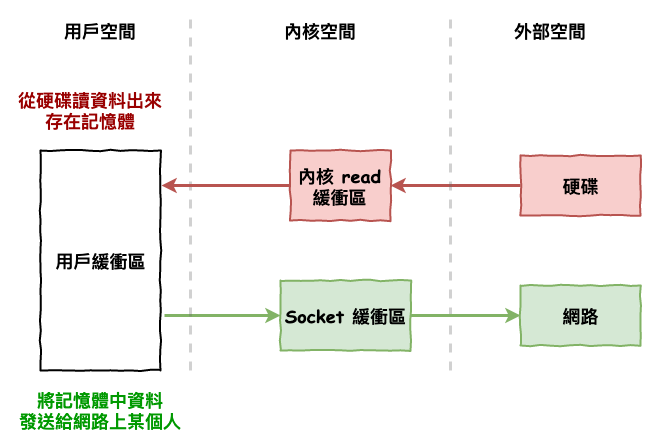
圖 5 : 作業系統讀取硬碟發給網路流程
而其中可以優化的地方在於『 內核空間 』那一塊的操作。
每當我們要從硬碟讀取資料時,要先將資料拷貝到內核緩衝區,接下來再拷貝到應用程式緩衝區,然後發送到網路時,要將應用程式記憶體資料再拷則到內核空間的 socket 緩衝區,最後再發送至網路上。
而零拷貼優化方向就在於如下圖 6 所示,如果我們可以不用再拷貝到用戶緩衝區的話,那不論是空間還是運算都省下不少工了。
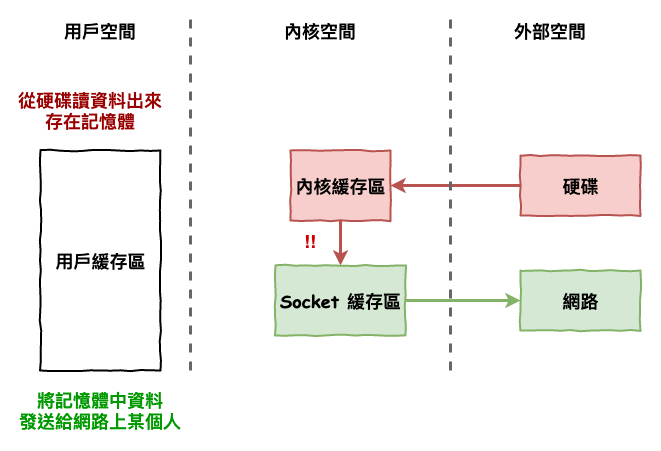
圖 6 : 零拷貝優化圖
而就是零拷貝。
linux 實現這零拷貝技術的所提供的兩個方法如下 :
在說明 mmap ( Memory-mapped )時,我們需要先理解一個東西,『 虛擬記憶體 』。
虛擬記憶體的概念如下圖,簡單的說,咱們應用程式記憶體存的不是實際的資料,而是存放對應到內核記憶體的位置,這個地方被稱為『 虛擬記憶體 』。你也可以想成應用程式記憶體與內核記憶體指向是同一個記憶體位置。
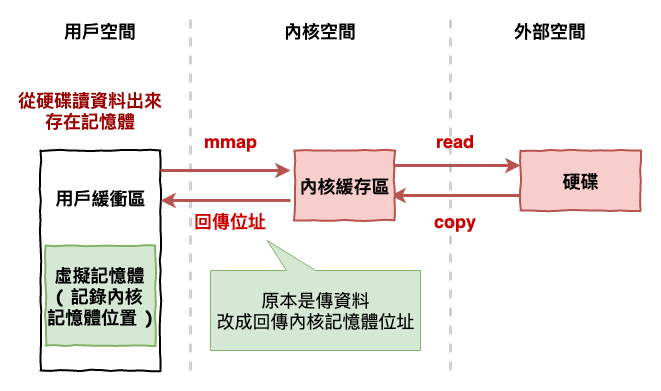
圖 7 : 虛擬記憶體概念
接下來下圖 8 為使用 mmap+write 實現零拷則的方式,當我們要 write 資料時,因為我們是存內核的記憶體位置,因此就不需要在進行拷貝,而直接將此位置資料,發送給網路世界。
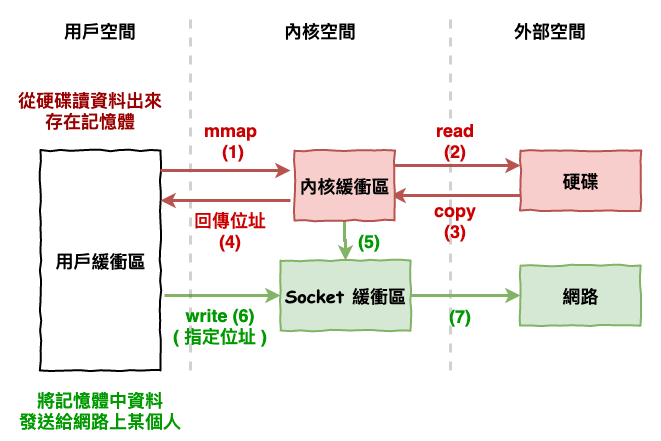
圖 8 : 使用 mmap 實現零拷貝優化
但是上面的方法還是需要運行 write,而它是所謂的 system call 方法,所以還是會讓進程或線程進行上下文切換。
因此後來又提供一個方法為『 sendfile 』,它的流程如下圖 9 所示 :
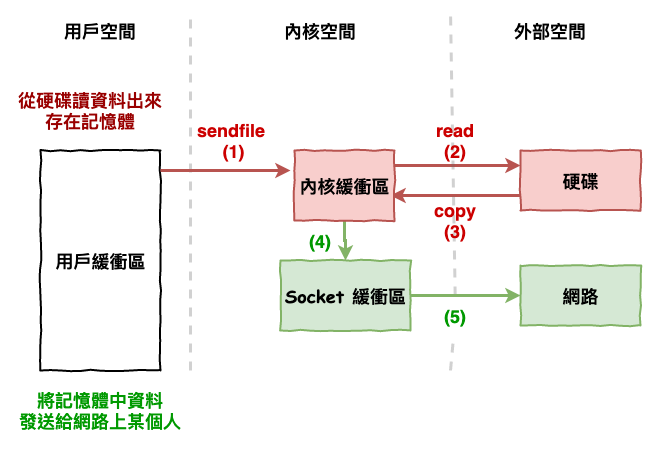
圖 9 : 使用 sendfile 實現零拷貝優化
接下來這一篇章節咱們簡單看看各種語言零拷貝的實現。
首先 java NIO 有提供 transferTo 可以實現零拷貝,它的方法如下 :
transferTo(position, count, writableChannel);
然後之後查了一下,java 的 Netty 看起來也有支援,但是有人又覺得不太一樣。由於我不是寫 java 的所以也不太懂,以下僅供參考。
对于 Netty ByteBuf 的零拷贝(Zero Copy) 的理解
nodejs 有一個『 Buffer 』 功能,這東西它可以在某個地方的記憶體,開啟一些緩衝區,而這個『 某個地方 』目前查了一下,它說 :
A Buffer is similar to an array of integers but corresponds to a raw memory allocation outside the V8 heap.
它這裡很明確的說是在 v8 之外,這是我也只能猜是內核,那這裡就可能可以動動手腳了,然後網路上好像有找到 nodejs mmap 可以參考一下。
而 php 方面,有在 swoole 看到相對應的 mmap 方法,那這個應該也有機率可以實現。
零拷貝使用上有個前提 :
那就是你要的資料不需要拉到應用端來修修改改。
所以事實上這也代表這,不太能使用需要應用端處理的東西,例如 https,但是像 tcp 這傳輸層級的東西就可以。
例如 redis 的 pubsub,它基本上是收到東西後,再直接透過 tcp 丟出去,這裡就有使用零拷貝技術。另外 kafka 被稱為高性能系統其中一個原因也在於使用了這一項技術。
這裡簡單說一下我的想法,基本上大部份的開發者都不太會碰到這個東東,而在 io 優化的情況下,除非是追求最高使用量的情況,那基本上可以先不往這方向優化,畢竟這不是所有語言都有支援。
不過我會把這章拉出來寫比較大的原因在於,觀念,這一篇文章帶入了很多關於我們常使用的 I/O 操作觀念,因此當你能理解零拷貝這東西後,基本上也代表你理解了 I/O 運行的原理,那這之後的路就會好走多囉。
