The president of the United States is Donald Trump. (美國總統是川普。)
資訊抽取技術在看到這句話時,會提取:
president(United States, Donald Trump).
資訊抽取的主要目標是將文字轉換成有架構的資料,讓這些以類似資料庫的方式呈現。取得有架構的資料庫之後,能夠進一步的幫助許多應用進行決策。例如:
資訊抽取有兩個步驟,首先將取得的資料進行命名實體辨識,接著進行「關係抽取」。用上述的例子,命名實體辨識時會取得「United States」和「Donald Trump」,而關係抽取會根據語句來找出「United States」和「Donald Trump」之間的關係,也就是「president」。
在關係抽取時,有時我們會有「關係資料庫」
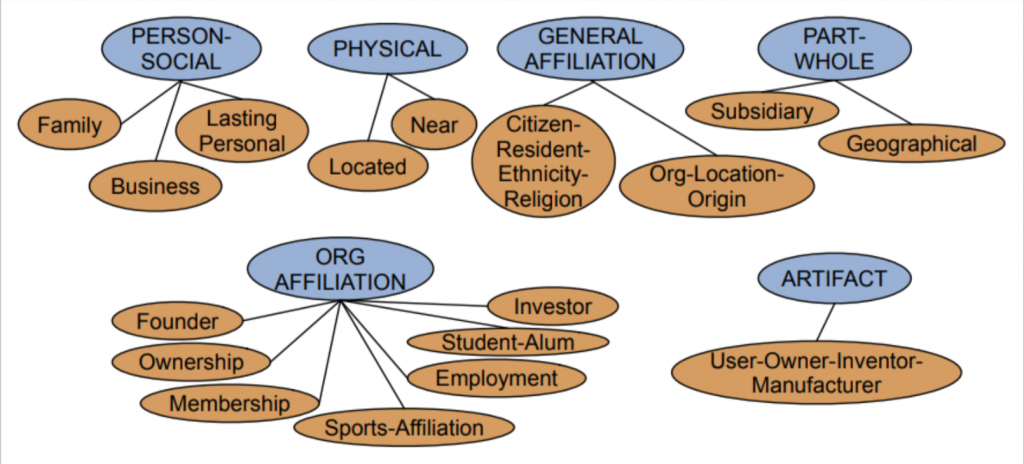
像是president(United States, Donald Trumps)的關係應該是ORG AFFILIATION下的Employment吧(笑)。
在有關係資料庫的情況下,我們可以採用幾種方法來實作關係抽取:
其他還有Semi-Supervised以及Distant Supervision的方法。
那麼,若是沒有關係資料庫的話,或是目標是要發掘新關係,該怎麼辦呢?OpenIE。OpenIE使用了Unsupervised learning(非監督式學習),輸入少量的關係(規則或實體pair)來訓練出一個通用的關係抽取模型。

