
那讓我們進入第一個所要介紹的KNearestNeighbors(KNN),KNN是實現k值最鄰近分類的算法分類器。
機器學習可以分為監督和非監督兩種,兩者最大的不同在於有沒有給資料學習,knn屬於監督式,所以預測之前需要給定資料讓他學習規則,KNN演算法算是一種"很懶"的演算法,一般的學習需要調整演算法中的參數,但是knn幾乎沒有參數是需要調整的,因此也不需要太多的訓練時間。
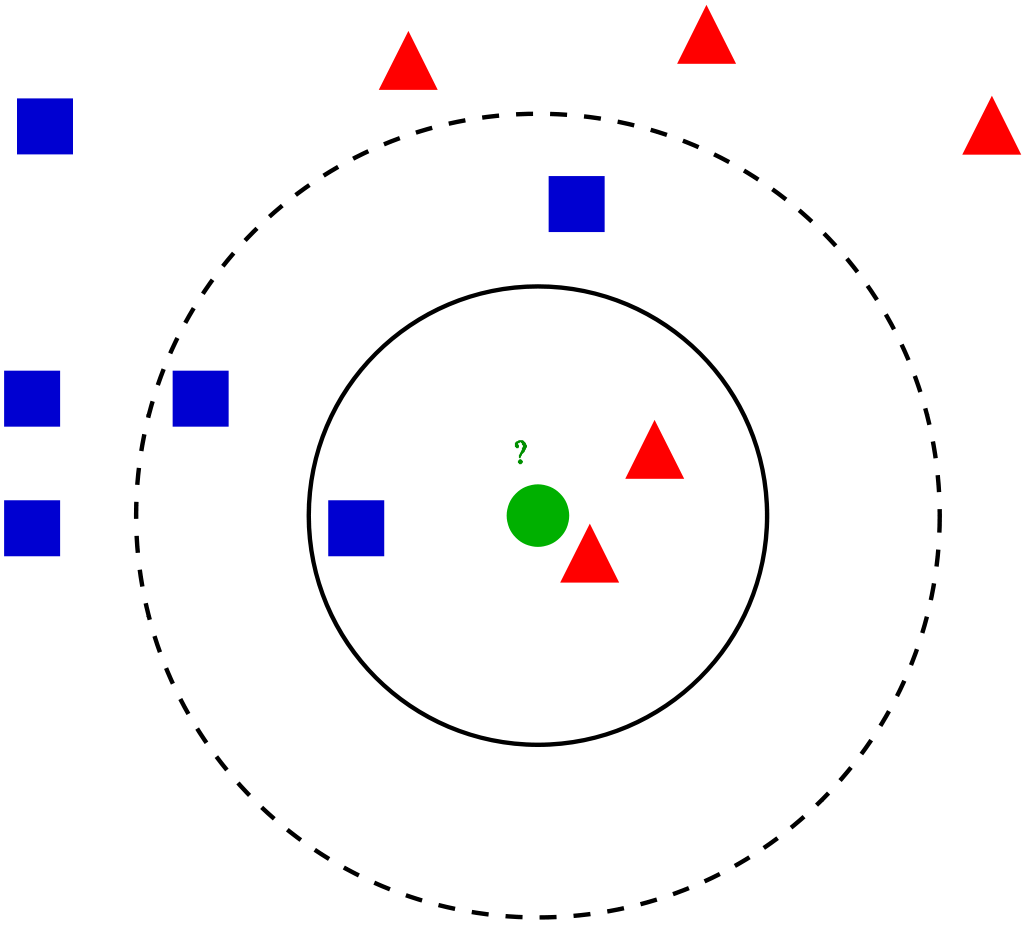
摘自wiki
KNN的分類原理由距離算法語K值兩個參數調整,距離就是計算我預測的數值點與其他訓練資料的距離,
我們比較普遍使用是歐式距離,也就是直線距離,兩點最近的距離,接下根據K值的值決定找出最近的K個樣本統計,
把位置的樣本預測為數量最多的類別。
下一篇,將帶大家來體驗一下官網所提供的KNN範例
