總算開始了一個跟DL比較有關係的名詞啦(?)一直以來科學家總想模仿動物的大腦來做AI結構,所以或多或少你們會看過科學家研究貓的腦部來知道大腦的哪個部分是做甚麼的,像下面這張圖,以期能夠設計出一套厲害的AI系統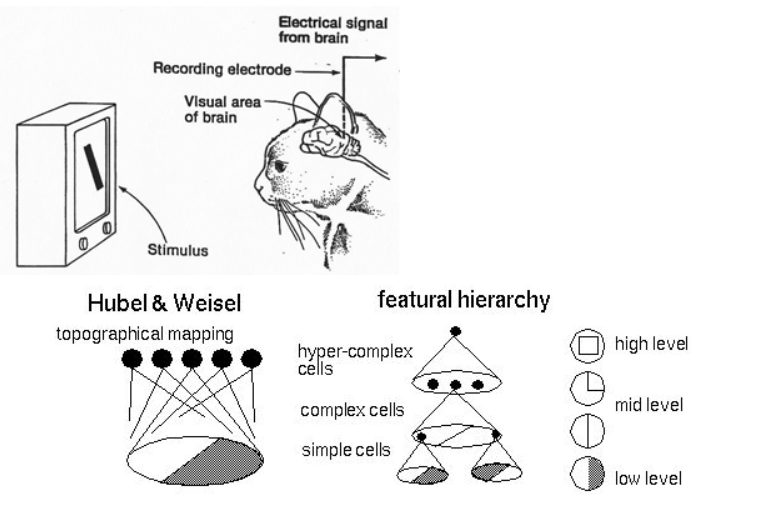
CNN做為DL崛起有著不可抹滅的功勞,像是拿到與紐約大學教授勒昆(Yann LeCun)和蒙特婁大學教授班吉歐(Yoshua Bengio)一起共同拿到 2019 圖靈獎的多倫多大學電腦科學教授辛頓(Geoffrey Hinton)在 2012 的 ImageNet 競賽提出的 AlexNet 以驚人的優勢贏了比賽。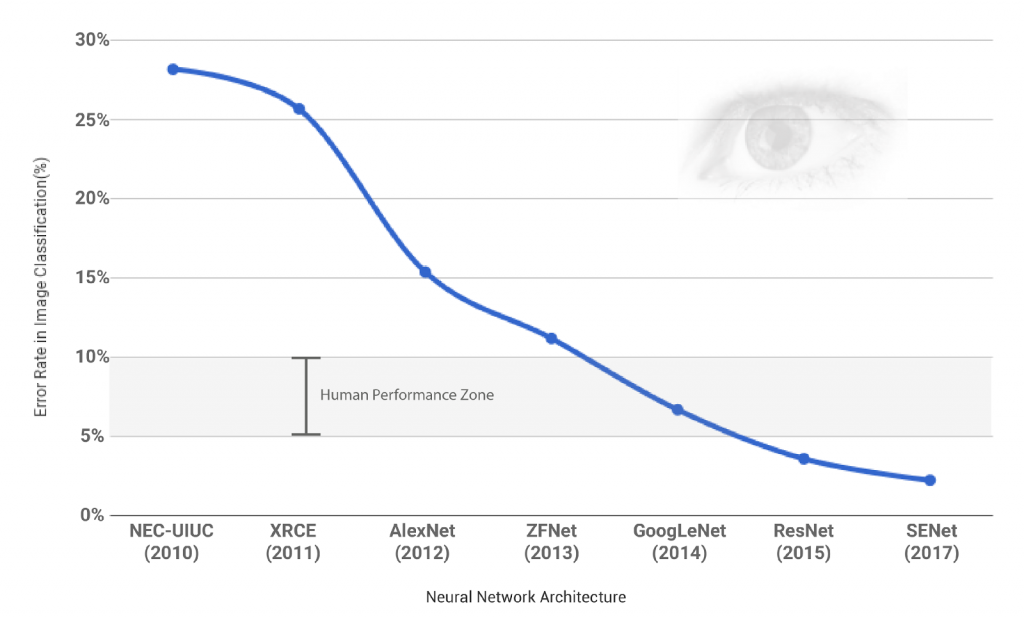
我們可以看到2012提出的 AlexNet相對於之前非 CNN-based 方法有了個非常大的進步,而之後提出的方法也是CNN-based 的,並且到了 2014 的 GoogleNet 電腦視覺的辨識能力就已經跟人類差不多了,而 ILSVRC 的classification比賽在2017年也是最後一屆,因為之後提出來的model的辨識能力已經遠遠超過人類的,這也說明了 CNN 的powerful !!
由於 CNN 的內容眾多並且也是各類型的 model (VAE、GAN)的基礎或者子結構,因此我們會花比較多的篇幅來說一下,主要會分成以下幾點來說明:
1.簡介與背景
2.結構簡介
3.Convolution、Pooling等等算法
4.Backward 更新
5.實做以及實例演練
首先先舉一個簡單的CNN例子給大家看看,如下圖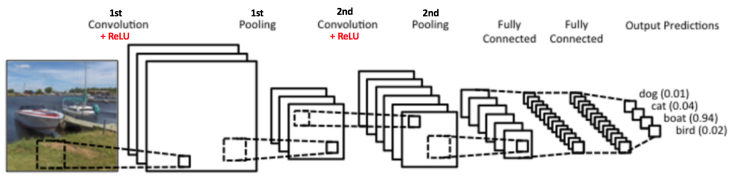
這是一個簡單的 CNN 使用例子,使用一個CNN做照片分類,我們可以看到這個CNN Model的 Input 是一張照片,中間一堆方格的意思表示著 CNN 的結構,最後輸出的是是個機率值,代表著這個model認為這張照片對這些類別的機率值,圖片中覺得這張照片最有可能是 "boat" 這個類別,因為他的機率最高(0.94)。
而這張圖片也充分提示了我們一個基本的 CNN model 會有的結構會有以下幾個:
1.Convolution Layer
2.Pooling Layer
3.Activation Function (圖片中紅字 "Relu" 的部分)
4.Fully Connected Layer
當然在CNN結構中其實也不只這一些小結構,也可以再加上像是 Batch Normaliztion 等等結構,但對於初不接觸我們先專心討論核心的結構就好,以下提點各種 Layer 的目的以及大概長啥樣:
不囉嗦先上張圖介紹 Convolution 在算的時候長啥樣
如果大家看不到上面這張這可以看下面這一張XD
Imgur
Convolution Layer 主要是用來從前一層的output中汲取 feature 或者資訊成為新的一張 feature map
用來降低採樣數,可以控制所存著並丟到下一層的資訊不會越來越多但又不會流失重要資訊
常見的像是 Max pooling: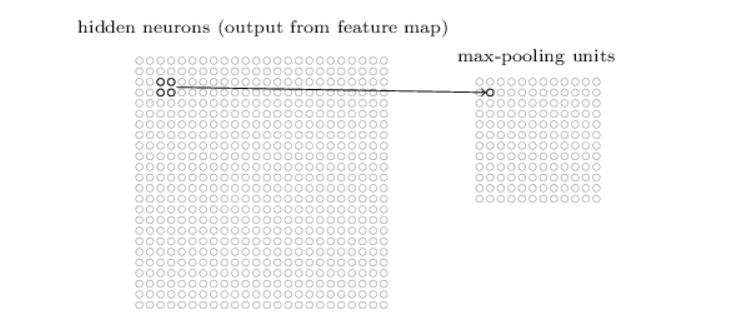
在每層 convolution layer 之後,讓output的值經過一個 non-linear 轉換,可以讓我們的 Model 去擬合更複雜、非線性的資料,常見的有像是 Relu、sigmoid等等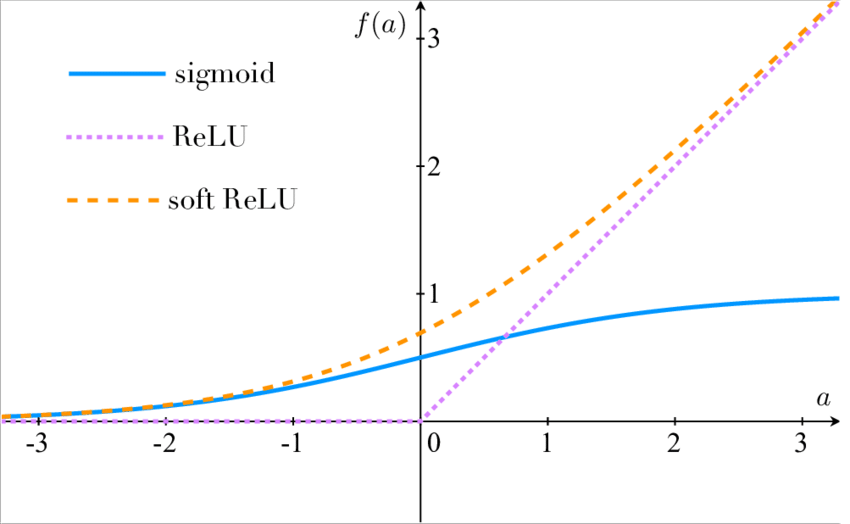
最後我們來提一下 fully connected layer,顧名思義他會與前一層的每個 unit做連結計算,因此所需要的記憶體通常不小,而convolution layer也是提出用來更有效、使用較少的變數達到一樣的計算擬合能力的 tool。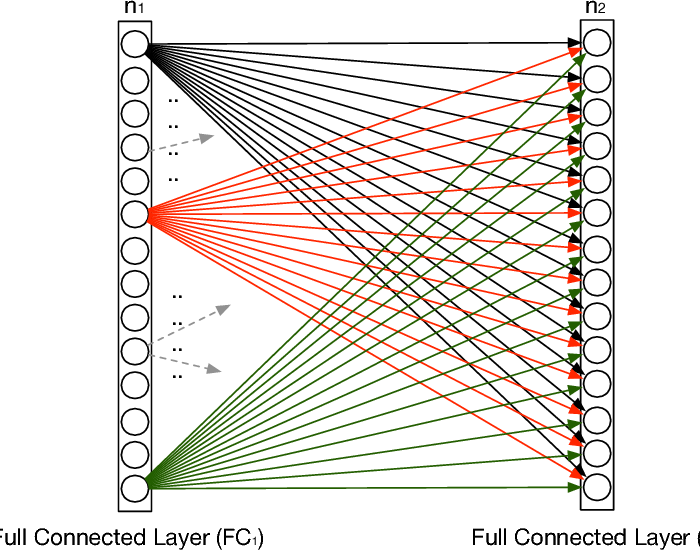
作為 DL 的入門結構, CNN 的設計我們需要好好的去掌握,知道每個部分的計算以及用意,對於之後在建構較為複雜的Model 我們就能夠更大膽的把CNN的這個子結構當零件組上去XDDD加油,這是開始的一小步,但卻是堅定的一小步!!



 iThome鐵人賽
iThome鐵人賽