Q-learning運作跟算法講差不多了,接下來補充幾個後面重要的改進,改進後面還有更多演化變種,不過我們這30天不會講得太深入,但面臨哪些問題挑戰一定要知道~
OpenAI建構了穩定的Atari遊戲環境,用Q-learning算法完爆了Atari很多種遊戲(附註1),其中很多遊戲的本質都是連續畫面(state),所以輸入的input也不會僅有單禎的,例如OpenAI很多時候在決定輸入採用4禎(當下的畫面加前三禎畫面),讓4禎影像做一次決策。
主要遇到兩個問題讓模型收斂不太好:
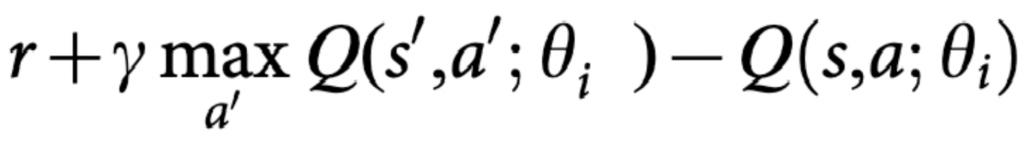
方法很簡單,搜集一定數量的樣本後,從中隨機採樣,看batch_size大小。隨機選取可以打破這相關性,讓數據分佈得更均勻,就減小了更新的方差,防止了發散或振盪,
在這裡我們可以設定一個新的model給Q現實,Q估計的model照樣訓練,但迭代到一個指定數量回合,才把參數複製給Q現實。論文表明利用這種時間的延遲,可有效降低相關性,讓模型收斂的更加穩定。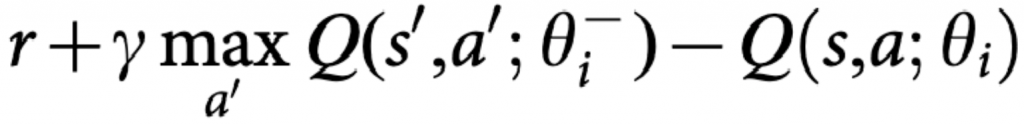
用更簡單說法,雖然reward不會做微分的話,但收斂仍有Q-max跟Q估計。用暫時的網路參數替代Q-max,這樣模型就能集中優化Q估計。雖然paper沒提及,但這想法挺直覺。
我們看到Q-table縱軸都有對照的state對嘛?但例如128x128x3的遊戲怎辦?這裡就只好交給類神經網路來做了XD 讓DQN等同於真正的Q-function。原本明確定義的state,現在改成用類神經去解析畫面,接著輸出控制。有別以往Q-table,DQN還要處理對state的解析,DQN收斂沒Q-table好,但因使用了非常多的參數去擬合,很多狀態都可以很好地泛化了!
接下來有會搭配自搭環境跟算法的章節,順便介紹DQN的結構是什麼,以及一些詳解是怎麼去設計的,不過在這之前,我們先來認識OpenAI-gym一些有趣,已經做好的環境跟算法套件吧!我們明天見囉~
附註1 Playing Atari with Deep Reinforcement Learning :https://www.cs.toronto.edu/~vmnih/docs/dqn.pdf

