特徵工程的資料類型有包含三種,
數值型、類別型、時間型,
需要進行填補空值、特徵處理等,
以下來源參考機器學習百日馬拉松。
數值型資料,除了填補缺值和去除離群值外,主要進行「去偏態」,
讓原本左偏或右偏的資料可以符合「常態假設」。
對數去偏就是使用「自然對數」去除偏態,
常見於計數、價格這類非負且可能為 0 的欄位。
df_fixed['LotArea'] = np.log1p(df_fixed['LotArea'])
將數值減去最小值後開根號,最大值有限制適用,
通常用於成績轉換。
df_fixed['LotArea'] = stats.boxcox(df['LotArea'])[0]
採⽤boxcox轉換函數,需代入函數的 lambda(λ) 參數。
df_fixed['LotArea'] = stats.boxcox(df['LotArea'], lmbda=0.5)
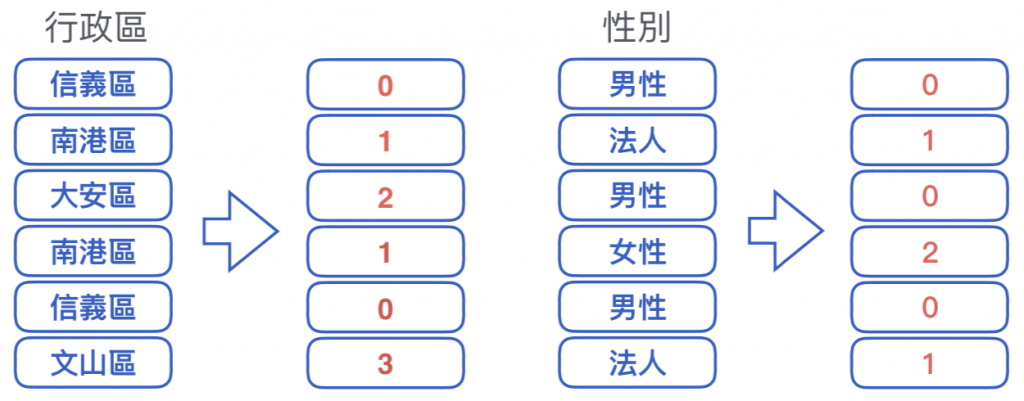
類似於流⽔水號,
依序將新出現的類別依序編上新代碼。
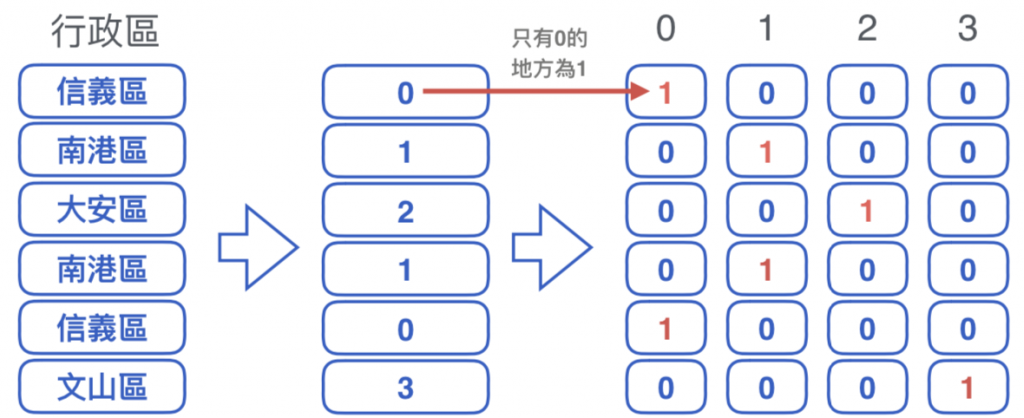
為了改良數字⼤小沒有意義的問題,
將不同的類別分別獨立為⼀欄。
取用兩個相關欄位,使⽤目標值的平均值,取代原本的類別型特徵。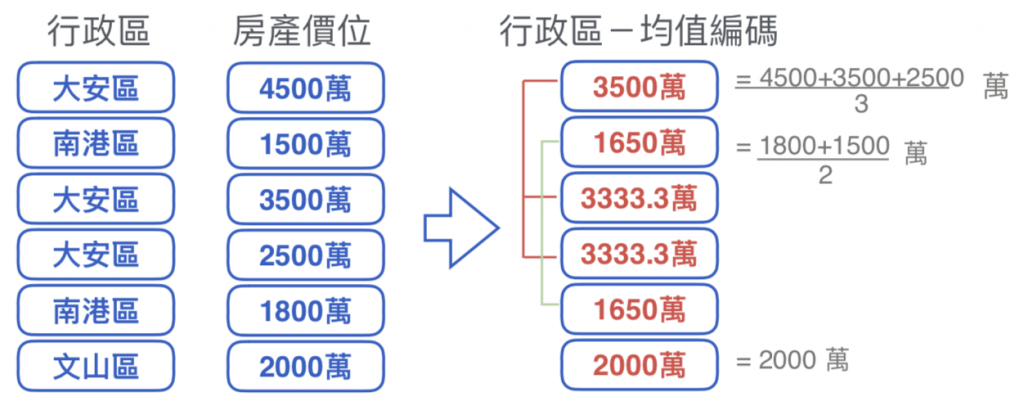
類別的⽬標均價與類別筆數呈正相關(或負相關),也可以將筆數本⾝身當成特徵。
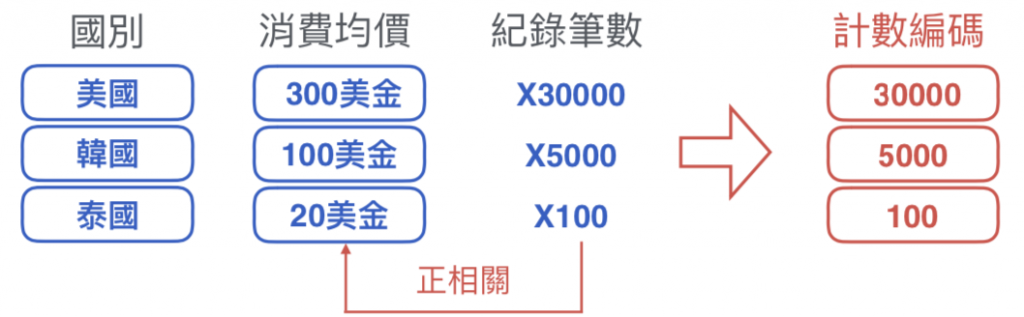
將類別由雜湊函數定應到⼀組數字,需調整雜湊函數對應值的數量。
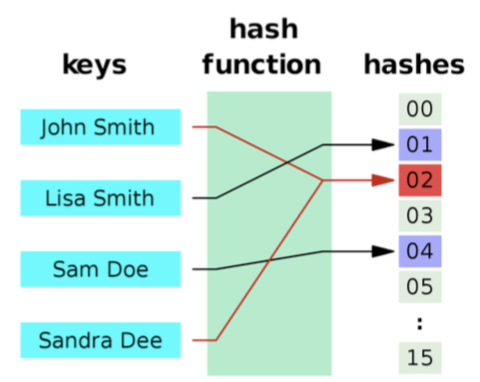
最直覺的⽅式,就是依照原意義分欄處理,或加上第幾周或星期幾。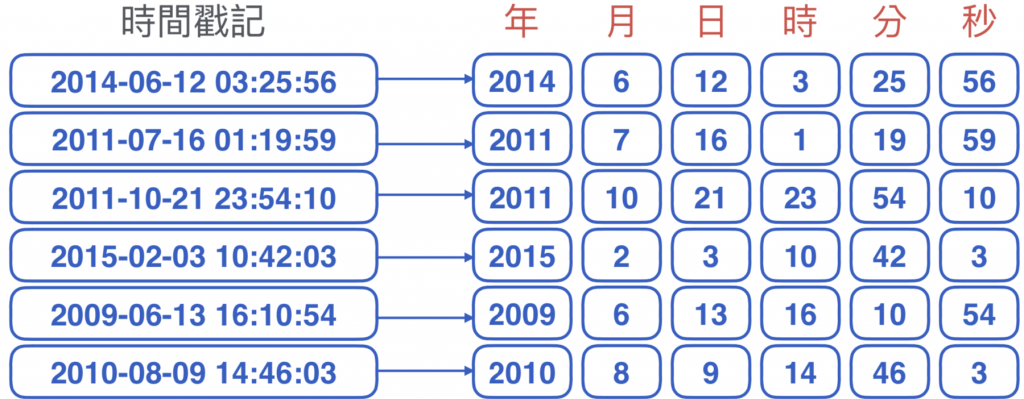
時間也有週期的概念,可以用週期合成一些重要的特徵。

除了針對不同資料類型做不同處理,
後續還有特徵組合、特徵篩選和特徵評估,
來提昇機器學習的準確率和效率。
以上,打完收工。


 iThome鐵人賽
iThome鐵人賽