上篇文章我們討論了稍微有些抽象的核方法與核轉換,這節讓我們來看看鼎鼎大名的隨機森林算法!
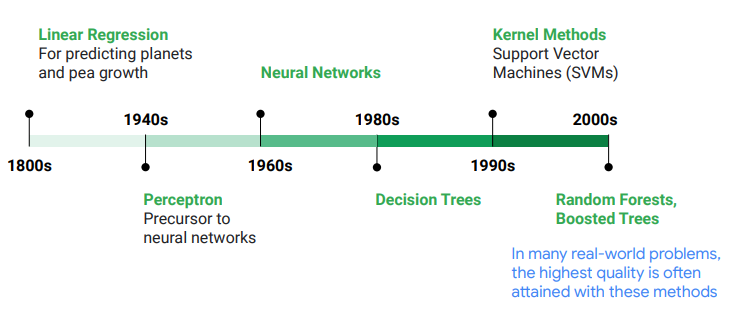
在近數十年來,機器學習的研究隨著算力(computational power)不斷的提升,可以使用所謂的集成方法(ensemble method)來獲得更好的模型性能與表現。我們可以想像如果各弱學習者的錯誤是獨立的,則合併起來則能成為一個強學習者。在DNN中,則是透過Dropout層的方法來近似,這有助於使模型正則化(regularization)並防止過擬合(overfitting)。Dropout是透過每次前進時隨機關閉不同的神經元來達成,這同時也產生了許多不同的神經網路。在現實中,多人所選出的答案往往比隨機的單人好。機器學習的集成也是如此:當你匯集了各種不同的預測器(不論是分類或是回歸),則這個組成通常都會比單個最佳模型的表現還好,這就是集成學習。
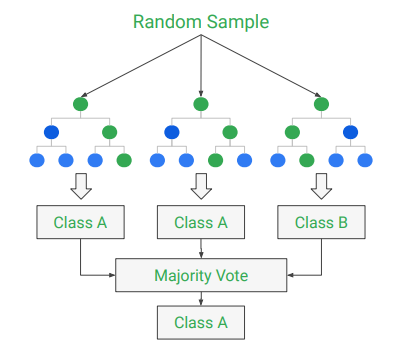
(待更)
若是覺得本文有幫助,歡迎點選Like、星星收藏或是追蹤系列文支持哦!


 iThome鐵人賽
iThome鐵人賽