關於深度學習的文章, 當然要推一下IT邦友寫的
英雄集結:深度學習的魔法使們, 非常的詳細介紹深度學習的來龍去脈。
所以小編這裡也快速的整理一下:
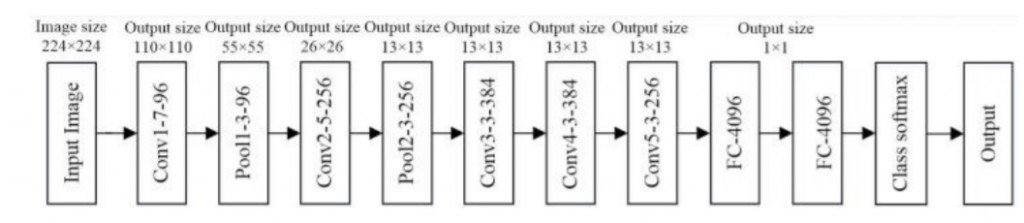
AlexNet(8層):一到5層做converlution operation and Pooling, 6到8層到fully connected layers。
程式的部份可參考:
git clone https://github.com/deep-diver/AlexNet
當然AlexNet太出名, 小編只參考一篇文章簡單說明AlexNet的運作:
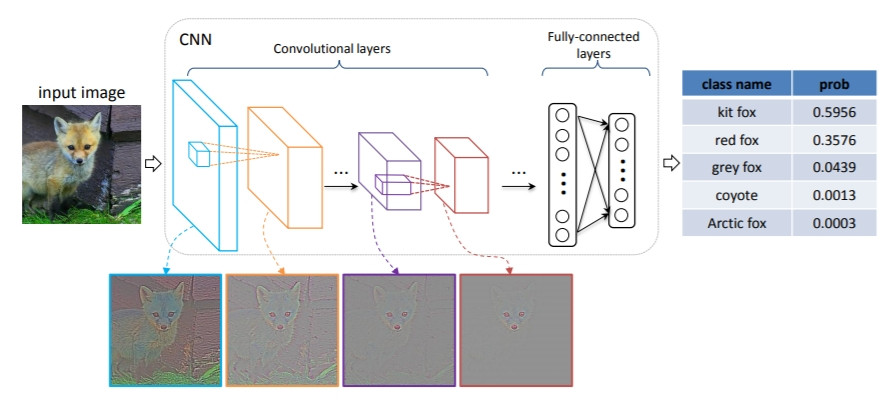
ZFnet架構是由AlexNet修改而來, 可參考這篇文章, 基本上就是比AlexNet多了卷積層:
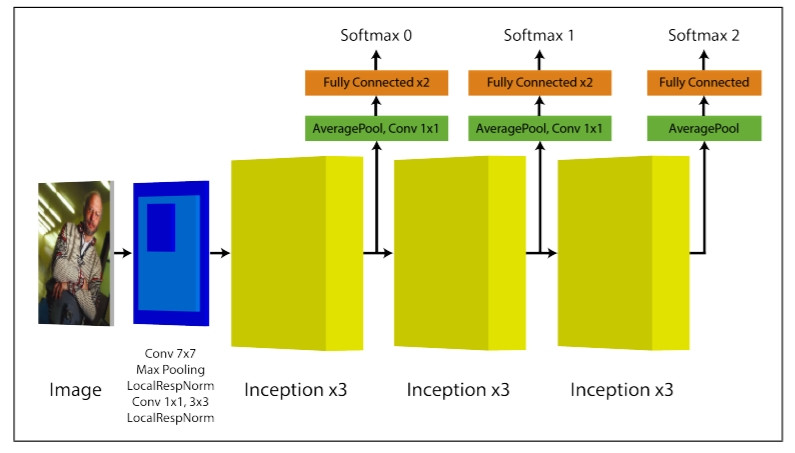
GoogLeNet比AlexNet用的參數還少, 是Google為了向LeNet表達敬意而取名, 但比AlexNet更精準, 其深度4x4的Convolution可達256層, 比較重要的名詞是Inception V1 to V4, 可參考這篇文章:
ResNet全名Residual Neural Network由微軟開發, 2015所用的是152層, 比前一年GoogLeNet的22層多了7倍, 這裡提節的是Residual Block, 可參考這篇文章。

GDB-Net雖然在2016年由中國隊拿到冠軍, 但整體效率也比2015提升2.2%
SeNet由新加坡團隊研發, 比ResNet錯誤率少了36%, 全名為Squeeze-and-Excitation Networks, 重點是在執行時要先squeez然後excitation再scaling。
這裡的深度學習資料很多, 實際上的應用分析也可參考這篇文章:
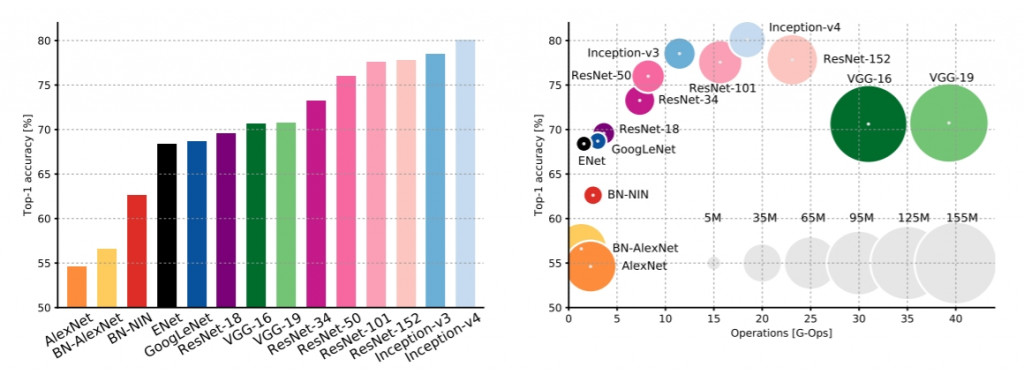
總結來說, 不一定準確率高, 訓練的方法就會快, 沒有百分之一百好用的深度學習模型, 當適合的模型搭配適合的硬體及適合的訓練好的Model, AI就可以發揮到最大的CP值。

 iThome鐵人賽
iThome鐵人賽