在介紹eager mode和tf.function的時候,就提到了 tf.Variable 如何在這兩種執行環境中使用。今天,我們一開始仍舊把重心放在tf.Variable, 隨後則是介紹無狀態版本的tf.Tensor,最後則是介紹 Ragged Tensor。
Ragged Tensor 是有著不同長度序列的 Tesnor 物件,這在處理 RNN 時相當常見,我們會將大部分的文章用來介紹 Ragged Tensor,以及該如何在 eager mode evaluate Ragged Tensor。
tf.Variabletf.keras 取得 tf.Variable 參數我們在建制 optimizer 時,或需要客製化梯度計算,都需要模型提供可訓練參數的名單,能夠在複雜的模型中仍保持參數的參考,是一件非常重要的事。
這種情況可能發生在使用者撰寫自己的 tf.keras.layers.Layer。下面的程式碼會建立兩個tf.keras.layers.Layer子類別,分別是 MyLayer 和MyOtherLayer。其中,MyOtherLayer擁有MyLayer物件,因此需要能夠 access MyLayer 的變數個數。MyLayer 則是利用一個 python list 來不僅管理所有的變數,也方便追蹤變數。
class MyLayer(tf.keras.layers.Layer):
def __init__(self):
super(MyLayer, self).__init__()
self.my_var = tf.Variable(1.0)
self.my_var_list = [tf.Variable(x) for x in range(10)]
class MyOtherLayer(tf.keras.layers.Layer):
def __init__(self):
super(MyOtherLayer, self).__init__()
self.sublayer = MyLayer()
self.my_other_var = tf.Variable(10.0)
m = MyOtherLayer()
print(len(m.variables)) # 印出 12,MyLayer 有 11 個 Variables
# 再加上 my_other_var
倘若使用者不希望自己撰寫追蹤 tf.Variable 的原始碼,可以繼承 tf.Module。該類別有兩個屬性:variables 和 trainable_variables 可以提供使用者提取模型參數。
其次,若 tf.Module 擁有另一個 tf.Module物件,則可以用 submodule 的屬性來 access 該物件。
如果要如 Tensorflow 1.x 對變數給予自訂的命名空間,以在 Tensorboard 可以階層是的方法顯示,而方便除錯。使用者可以用 @tf.Module.with_name_scope 來 decorate 實作正向傳播的 __call__方法,然後在 with self.name_scope 進入同樣的命名空間,如下面程式碼所示:
class MLP(tf.Module):
def __init__(self, input_size, sizes, name=None):
super(MLP, self).__init__(name=name)
self.layers = []
with self.name_scope: # 進入相同的命名空間
for size in sizes:
self.layers.append(Dense(input_size=input_size, output_size=size))
input_size = size
# 使用命名空間
@tf.Module.with_name_scope
def __call__(self, x):
for layer in self.layers:
x = layer(x)
return x
tf.TensorRagged Tensor 是一種 Tensor 其內容物擁有非一致的長度。除了常見不定長度的序列資料,具有階層或結構式的架構資料,如 graph 表示或自然語言中的解析樹架構。了解為何有 ragged tensor 後,我們進入如何建制一個 ragged tensor 和 如何使用它。Tensorflow 將 Ragged Tensor 的實作寫在 tf.ragged 模組。現在就來看看官方網頁提供,有關Ragged tensors的範例吧!
tf.ragged.constant 建構子來建立 RaggedTensor 物件: tf.ragged.constant 接受 python 的 list of lists,lists 的長度不需要一致,但元素的資料型態則需要一致,不能將混合的資料型態,如數值與字串放置在 RaggedTensor 內。這個方法是最簡單的方法來建構RaggedTensor物件,但需要使用者使先提供資料。呼叫方法,如右:digits = tf.ragged.constant([[3, 1, 4, 1], [], [5, 9, 2], [6], []])
tf.RaggedTensor.from_value_rowids, tf.RaggedTensor.from_row_lengths 和 `tf.RaggedTensor.from_row_splits:這些方法都需要使用者提供列方向的切割方法(row-partitioning tensors),通常這個方法的實作,會將所有的元素儲存在一塊聯繫的記憶體,而依靠使用者提供的切割方法來取得元素。RaggedTensor怎麼做存取:tf.RaggedTensor.from_value_rowids:如圖,每一個元素有對應自己的 row id。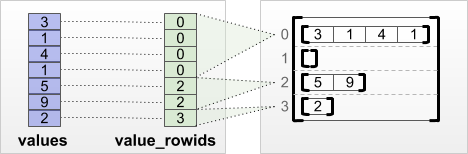
tf.RaggedTensor.from_row_lengths:上面的方法很直覺但有點浪費空間,如果我們知道每一列的長度,我們就可以以比較精簡的記憶體空間來存取,如下圖,右方的 row_lengths 陣列,每一個元素儲存的是該列的長度。如,第一個元素為 4 代表的是第一列的長度為 4: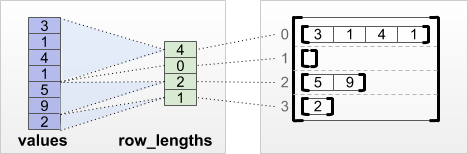
tf.RaggedTensor.from_row_splits:上者儲存的是長度資訊,然而當我們需要取出第二或第三列時,我們都比須對長度陣列做累加方能使用 slice 取出該列的所有元素。所以,from_row_splits 就是針對 slice 所設計的。現在右方儲存的是每一列的 slice 或列分裂(row splits)資訊,長度比from_row_lengths 多了一個元素。若要取出第一列的所有元素,則右邊的第一個元素為第一列的起始 index,而第二個元素為第一列的結束 index + 1,有了這兩個值就可以建構 slice 物件,將第一列所有元素都取出。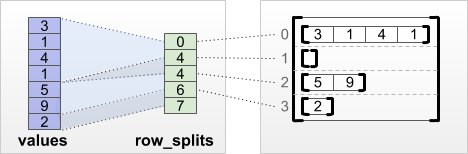
在運算元方面,tf.RaggedTensor 和 tf.Tensor相同,計算運算元被複寫,而使執行運算元時,是以元素為單元來運算。然而,tf.RaggedTensor多了一個限制,那就是運算元兩邊的維度需要相同,包括列的長度也需相等。
在 indexing 方面,tf.RaggedTensor 支援 python-style 的 indexing,也就是沿著每一個維度,用 slice 來取出元素。然而,應用在 tf.RaggedTensor,有一些限制。限制包括了,不得在 ragged dimension,或擁有長度不一的象限上 indexing。
接下來我們來看一些原始碼範例,瞭解一下如何用另一個 tf.RaggedTensor 來作 indexing。
queries = tf.ragged.constant(
[['Who', 'is', 'George', 'Washington'],
['What', 'is', 'the', 'weather', 'tomorrow'],
['Goodnight']])
print(queries[1:]) # 除了第一列,列出所有
#=> <tf.RaggedTensor
#[[b'What', b'is', b'the', b'weather', b'tomorrow'], # row 1
#[b'Goodnight']]> # row 2
print(queries[:, :3]) # 每一列的前三個字,使用 slice 非 exact indexing
#=> <tf.RaggedTensor
#[[b'Who', b'is', b'George'],
#[b'What', b'is', b'the'],
#[b'Goodnight']]>
print(queries[:, 3]) # 每一列的第三個字,使用 exact indexing
# ValueError: Cannot index into an inner ragged dimension.
tf.RaggedTensor vs tf.SparseTensorstf.RaggedTensor雖然使用相似的方式來儲存,但兩者在意義上和實作上則有相當大的不同。就以 concat這個運算元來說,要沿著 ragged dimension,或該軸擁有長度不一的序列來合併兩個 tf.RaggedTensor ,結果是 ragged dimension 的序列長度合併,如下圖:
若是 tf.SparseTensors,則需要擴展 dimension,再將元素放到擴展完成的位置上,可以看下圖說明: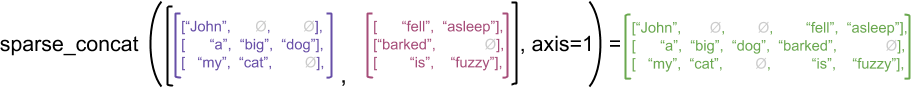
總之,tf.RaggedTensor可以看作為在 ragged dimension 是密集儲存的 Tensor 物件。
Tensroflwo 提供tf.RaggedTensor到tf.Tensor 型態轉換,以及 tf.RaggedTensor到tf.SparseTensors 。前者的轉換邏輯很簡單,就是把長度不一的那個維度,用最大長度填滿即可。
所以,結論是:
tf.RaggedTensor到tf.Tensor: 呼叫 tf.RaggedTensor物件的 to_tensor方法,若長度不足則用使用者所給的預設值(default_values)填入。tf.Tensor 到 tf.RaggedTensor: 呼叫 tf.RaggedTensor 類別的 from_tensor方法,需要使用者提供 padding 所用的值,建立 tf.RaggedTensor 時移掉 paddingtf.RaggedTensor到tf.SparseTensors: 呼叫 tf.RaggedTensor物件的 to_sparse方法tf.SparseTensors 到 tf.RaggedTensor: 呼叫 tf.RaggedTensor類別的 from_sparse方法ragged_sentences = tf.ragged.constant([
['Hi'], ['Welcome', 'to', 'the', 'fair'], ['Have', 'fun']])
print(ragged_sentences.to_tensor(default_value=''))
# => tf.Tensor( #每一個序列長度最大為 4,用 default_value 不足 4
#[[b'Hi' b'' b'' b'']
# [b'Welcome' b'to' b'the' b'fair']
# [b'Have' b'fun' b'' b'']], shape=(3, 4), dtype=string)
print(ragged_sentences.to_sparse())
# => SparseTensor(
#indices=tf.Tensor(
#[[0 0]
# [1 0]
# [1 1]
# [1 2]
# [1 3]
# [2 0]
# [2 1]], shape=(7, 2), dtype=int64),
#values=tf.Tensor([b'Hi' b'Welcome' b'to' b'the' b'fair' b'Have' #b'fun'], shape=(7,), dtype=string), dense_shape=tf.Tensor([3 4], #shape=(2,), dtype=int64))
x = [[1, 3, -1, -1], [2, -1, -1, -1], [4, 5, 8, 9]]
print(tf.RaggedTensor.from_tensor(x, padding=-1))
# => <tf.RaggedTensor [[1, 3], [2], [4, 5, 8, 9]]>
st = tf.SparseTensor(indices=[[0, 0], [2, 0], [2, 1]],
values=['a', 'b', 'c'],
dense_shape=[3, 3])
print(tf.RaggedTensor.from_sparse(st))
#=><tf.RaggedTensor [[b'a'], [], [b'b', b'c']]>
在 eager mode 裡,所有的陳述句都會被 python 直譯器上執行以及評估。而為了符合 eager mode 的特性,tf.RaggedTensor 的使用者可以有以下方法來檢視:
tf.RaggedTensor.to_list()的方法,把對 Python 不透明的tf.RaggedTensor物件轉成 python list。tf.RaggedTensor 轉為 EagerTensor 並用 numpy 屬性來取值。tf.RaggedTensor 的屬性分開檢視。如果適用 row_splits 的方法建構的tf.RaggedTensor物件,則可以分別呼叫 tf.RaggedTensor.values 和 tf.RaggedTensor.row_splits分開檢視。現在用程式碼說明:
rt = tf.ragged.constant([[1, 2], [3, 4, 5], [6], [], [7]])
print(rt.to_list()) # 方法一,使用 to_list 方法
# =>[[1, 2], [3, 4, 5], [6], [], [7]] # python list
#方法二,使用 python indexing,在呼叫 numpy() 轉成 numpy.ndarray
print(type(rt[1]), rt[1].numpy())
# => <class 'tensorflow.python.framework.ops.EagerTensor'> [3 4 5]
#方法三,分別呼叫
print(rt.values)
#=> tf.Tensor([1 2 3 4 5 6 7], shape=(7,), dtype=int32)
print(rt.row_splits)
#=> tf.Tensor([0 2 5 6 6 7], shape=(6,), dtype=int64)


 iThome鐵人賽
iThome鐵人賽