Day20 TensorFlow.js 即時物件辨識(背後的技術)Part2
昨天因為只看論文
解釋起來只有文字
不是很好理解
稍微去找了一下 圖來增進理解這RCNN、Fast RCNN與Faster RCNN之間的改進與不同
RCNN 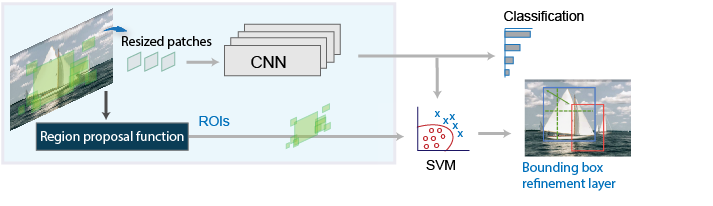
就如同昨天說的,RNN在照片上找到框框後,會將每個框框都進行CNN的計算,轉成特徵圖,在進行分類與決定位置
Fast RCNN 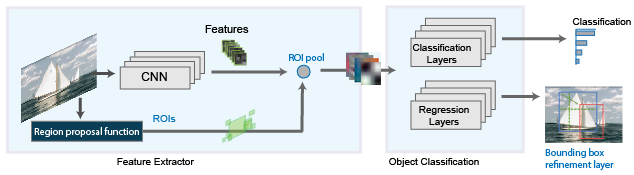
則是整張圖直接進行CNN的計算,找出特徵圖後,在透過原本的框框,擷取特徵圖,為了讓每個框框,在神經元連結數保持一致,會需要經過ROI pool
Faster RCNN 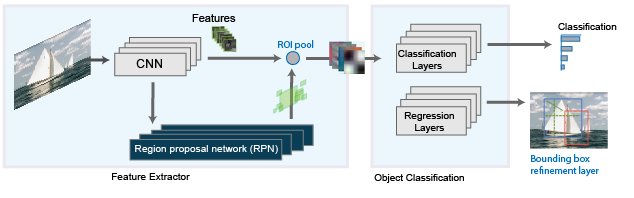
則是把找框框這件事,交給RPN去做
補充:ROI pooling layer
原本的池化層是指定池化框的大小,例如2x2,將特徵減少為原來的1/4倍。
ROI pooling則是指定特徵最後餘留的數量,在去定義池化框的大小,也就是說當指定最後特徵大小4x4,那麼原本32x32的特徵圖,池化框大小就是8x8,原本是16x16的特徵圖,池化框大小就是4x4
補充:RPN
RPN內部會有一個CNN進行卷積,得到整張圖的特徵圖
所有的特徵圖上在進行一次卷積,在卷積核通過時,此時卷積核的中心點,取不同大小,不同長寬比的anchor
(
假設20 70 100三種大小、1:2 1:1 2:1三種比例
那就會產生
20x40、20x20、20x10
70x140、70x70、70x35
100x200、100x100、100x50
這些框框
)
進入全連接層,判定這些region proposal與真實目標的重疊率,並與真實的重疊率做比較,訓練此神經網路判定這些region proposal與真實目標的重疊率的能力,訓練完後的RPN就能夠預測哪些region proposal比較可能與真實目標比較相似,再將此RPN放入Faster RCNN中,為region proposal提供可靠的建議。
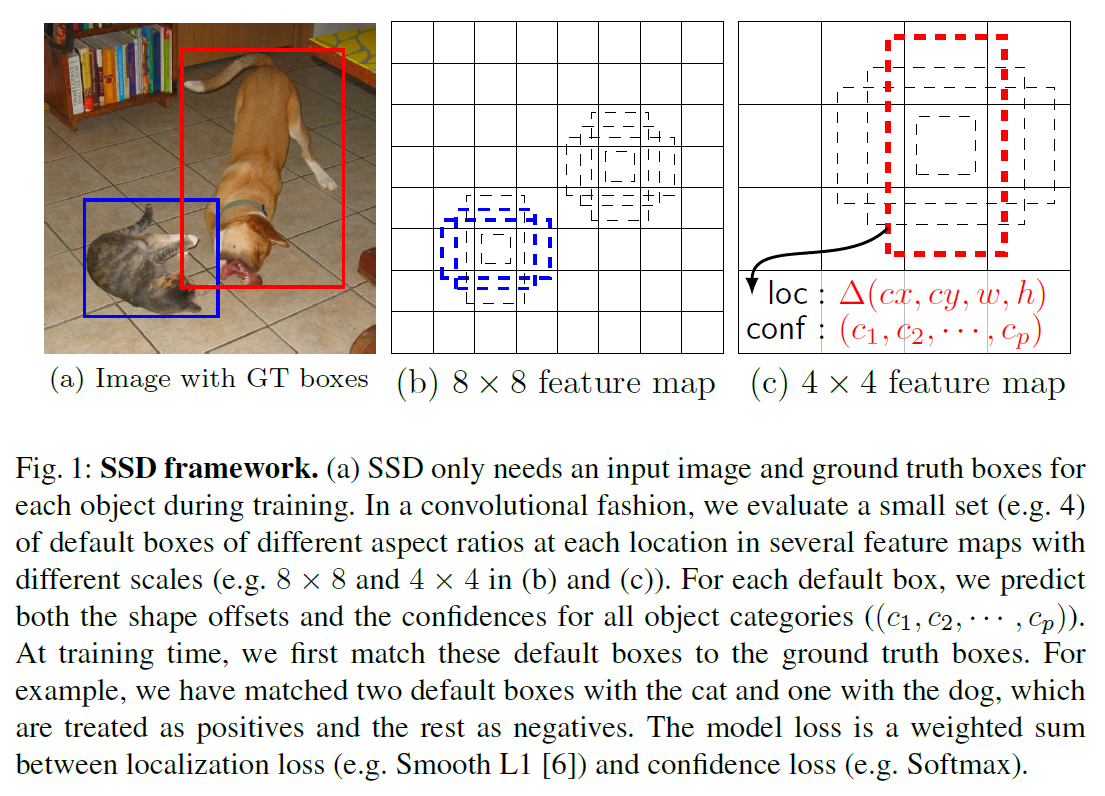
接下來來說YOLO v1(You Only Look Once: Unified, Real-Time Object Detection)
作者用了一張圖來解釋YOLO v1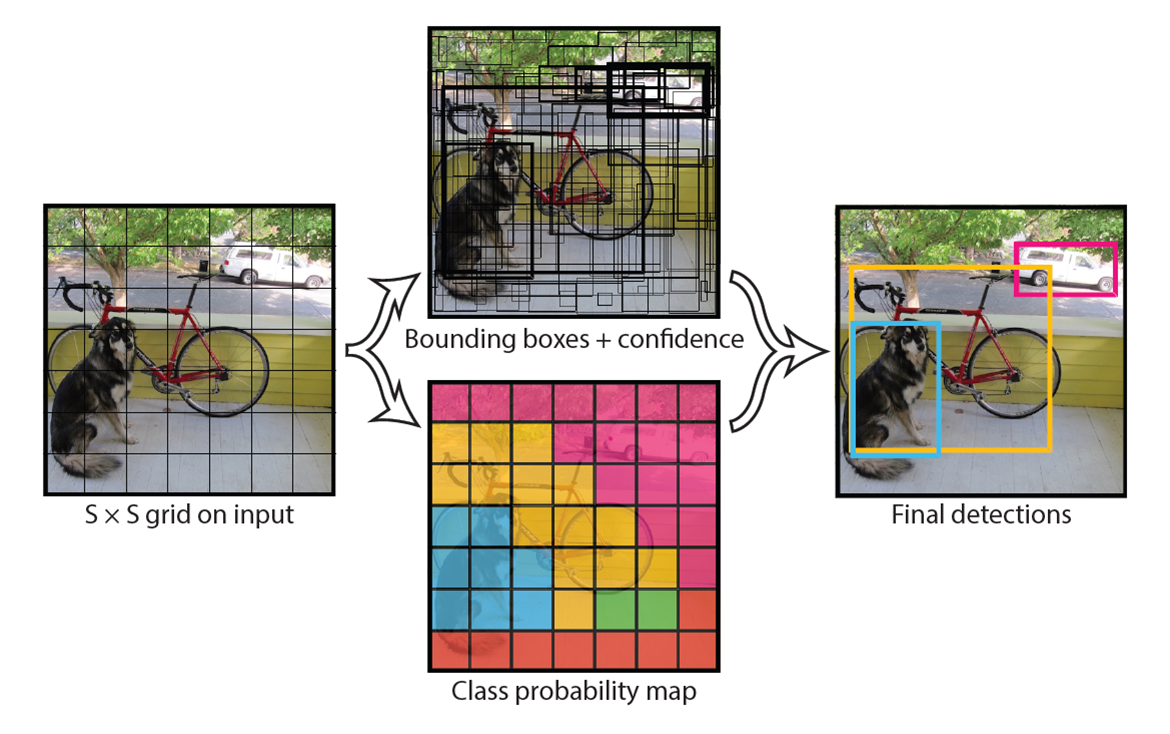
大致上可以這樣解釋
首先先將整張圖分成,7x7大小,每一格都先偵測這格是否包含物體的信心程度,如果有的話,格子就向外圈選幾個bounding box,並計算這些bbox跟真實圈選的誤差,之後每一格在針對給定的每個類別去計算這個類別的物體出現在bbox內的機率,留下有較高信心的bbox在Non-Maximum Suppression (NMS)用進行整合
訓練的目標就是讓模型在圈選bbox的預測更準
也就是說,直接計算如何回歸出bbox,
Single Shot MultiBox Detector
終於看到這裡了,上面說的YOLO有一個小小的問題,因為沒有Region Proposal所以對於物體位置並不能很精準的定位(不過這是在說YOLO v1版,我看v2版論文好像就有改善)
想法跟YOLO v1很像,不過就是YOLO v1只是努力訓練預測bbox,SSD則是先在不同的特徵圖上,採用不同的anchor,並預測這那些anchor比較準,所以第一是不用像Faster RCNN一樣要花時間去要提region proposal(這需要卷積,計算量比較大),第二是比YOLO v1提出的bbox更準,因為是根據不同特徵大小去分層擷取決定anchor,也就是說
Faster RCNN像是可能有物體就提案去檢查
YOLO v1先確定這是不是需要檢測的物體並直接猜物體的邊界
SSD先確定這是不是需要檢測的物體再去提案檢查
這邊只是大致上概述,詳細YOLO跟SSD的實作,其實我是看得不太懂,概念上大致能理解要做什麼,但實際像是YOLO bbox的產生,有點難相信,感覺像是多多訓練,就能讓其更好的猜到bbox,YOLO的訓練過程中計算誤差的數學式我看了好久,最後還是放棄了,像SSD裡面更是有很多神奇的地方,例如the ratio between the negatives and positives is at most 3:1還有像each sampled patch is resized to fixed size and is horizontally flipped with probability of 0.5,有點像是直接看到實驗資料,反正這樣調一調,結果會比較好,所以就寫在裡面了,而不是一個完整的架構,可以看清楚原理的那種把握住脈絡的感覺(有可能是我還太嫩了)。
PS:其實還有YOLOv2、YOLOv3,尤其是YOLOv3在速度跟準度上可能是比較好的選擇