前面幾篇的文章中,我們知道如何儘可能的在單機上,可以以最少的資源做最多的事,但是單機一定有它的限制,因此接下來我們要開始正式進入所謂的『 分散式系統 』。
分散式系統不是簡單的增加機器就可以增加效能那麼簡單,它不是簡單的 1 + 1 = 2 的這種概念,有時後 1 + 1 還會小於 2 或小於 1。
最要的原因在於要達成一致性的難度更高,並且維護與管理更複雜,除非你單機真的已經到了極限,不然如果是為了『 性能 』而加機器,那也只是會浪費你更多的時間,不過在實務上有時是為了可用性而加機器那這到還可接受。
本篇文章將分為以下幾個章節 :
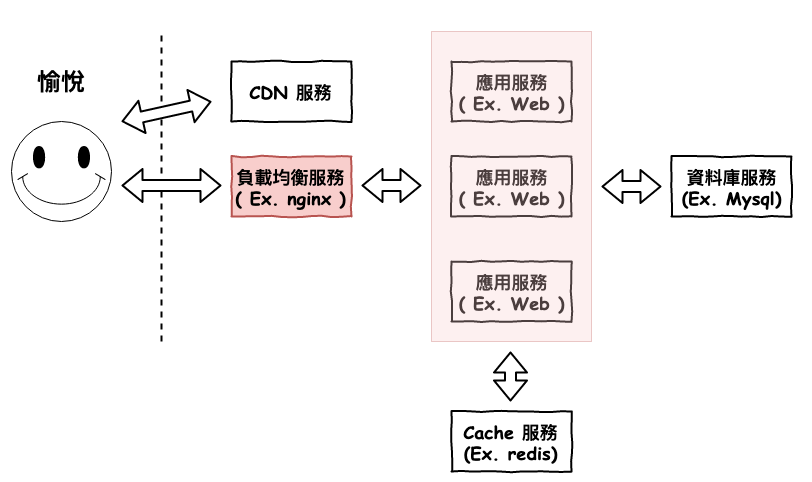
應用層擴展基本上 90 % 都會是長的如下圖 1 架構。
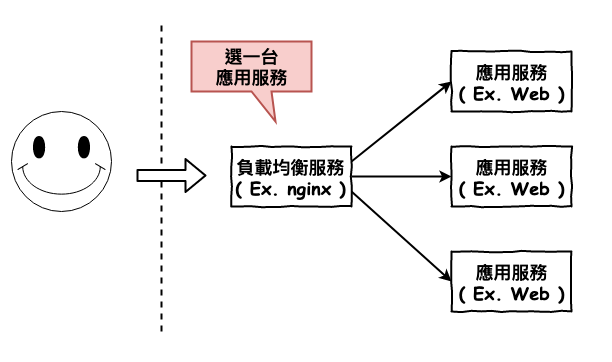
圖 1 : 基本擴展型
基本上會將應用服務變成多台,然後前面加一個負載均衡 ( Load balancing ),每當用戶有請求進來時,會先通過負載均衡服務,然後它會選一台應用服務來將請求送過去。
目前在 web 領域比較常用的負載均衡服務應該是『 nginx 』,它的基本架構就如同咱們前面章節所說的 reactor 架構,所以基本上它可以處理非常多的連線。
30-07 之應用層的 I/O 優化 - 非阻塞 I/O 模型 Reactor
然後 nginx 它有提供以下幾種的分配演算法 :
接下來這個章節,咱們要來看看負載均衡的一些優化方向
首先咱們先看最基本型的詳細運行流程,如下圖 2 所示。
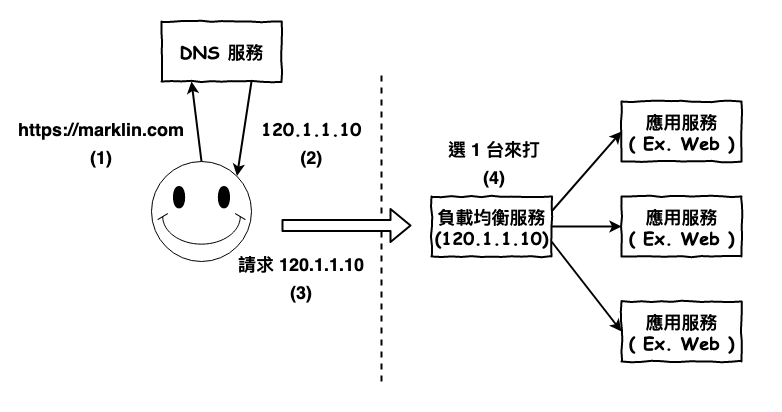
圖 2 : 基本型的傳輸流程
上面的基本型有什麼問題呢 ?
負載均衡服務單機固障
嗯對很明顯,如果負載均衡服務固障了,那就整個系統就要說掰掰了,所以通常會準備多台的服務然後使用 keepalived 機制來確保某個正在服務的服務固障時,可以快速的轉換成備用的。
keepalived 是一個使用 vrrp 協議的高可用方案,有興趣的有友人可以自已去 google 研究一下。
接下來咱們來看一下加入以後整個流程是如何跑。
其中這裡要注意,keepalived 是會裝在兩台 nginx 機器中,然後對外都統一用 keepalived 這配置的虛擬 ip ( 10.1.1.120 ),當 master 有問題時 ( slave 偵測到 ),會自動的將 slave 升為 master。還有對外都是使用 keepalived 所配置的 ip,所以也不需要修改 nat 的轉換表。
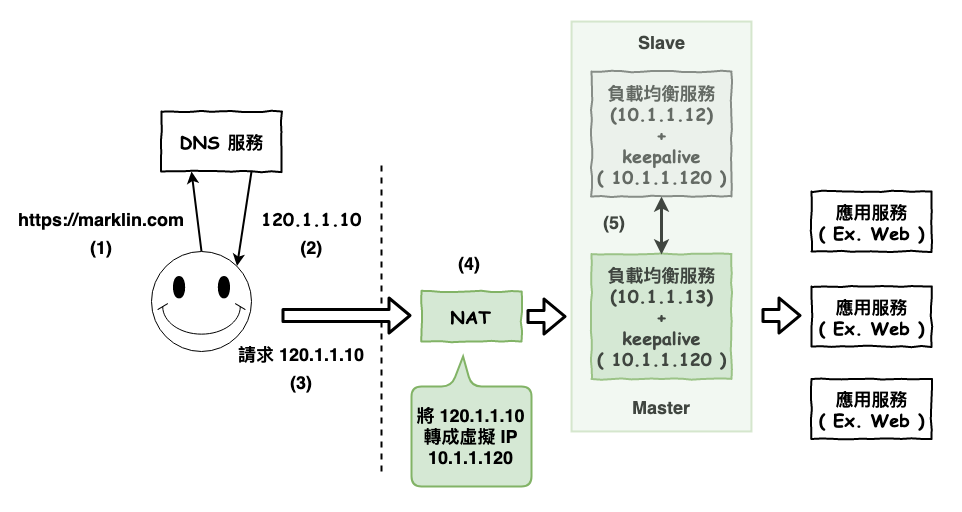
圖 3 : nginx 加入高可用性
對了為啥要用虛擬 ip 呢 ? 首先第一個原因靈為快與省對外封包,你可以想成虛擬 ip 都是包含在同一個內網世界,每當某台內網服務要找另一台服務時,只要擴播到內網就夠了,而如果是在外網 ip 上,你就要去每個中端機器問一下這是你家的東西嗎 ? 然後找到這個 ip 是某家族的以後,在內裡面才會在擴播一次,這裡只是很簡單的說一下,詳細的內容自已去找找。
第二個原因,安全,通常躲在內網裡,正常的情況下,前面都要放一層防火牆,有些情況下 nat 本身也有防火牆的功能,這樣可以防止你內部的服務不被打。
第三個原因,外網 ip 很貴,你覺得有可能每一台備機都要有個外網 ip 嗎 ?
~ 小知識 ~
這上面多了一個叫做 nat 的服務,它專門用來將公網 ip 轉換成內網 ip,詳細 nat 的知識可以參考之前寫的這一篇文章。
30-28之 WebRTC 連線前傳 - 為什麼 P2P 連線很麻煩 ? ( NAT )
到了這裡要來介紹另一個負載均衡服務『 LVS ( Linux Virtual Server ) 』。
上面說提到的 nginx 負載均衡服務它被稱為『 第七層負載均衡 』,而這裡所提的第七層就是指網路協議的『 應用層 』,也就是說它是專門用來負載均衡一些 http 這種應用層協議的服務。
而 lvs 被稱為『 第四層負載均衡 』,它就是專門用來處理第四層『 傳輸層 』協議的,也就是說它是用來專門處理 tcp 或 udp 傳輸層的負載均衡。
事實上在台灣大部份的系統大約上面兩個階段就很足夠了,下面這種結構除非你真的衝過頭,不然基本上應該是用不太到的,不過這裡還是可以來理解一下。
這種架構如下圖 4 所示。運行流程如下。
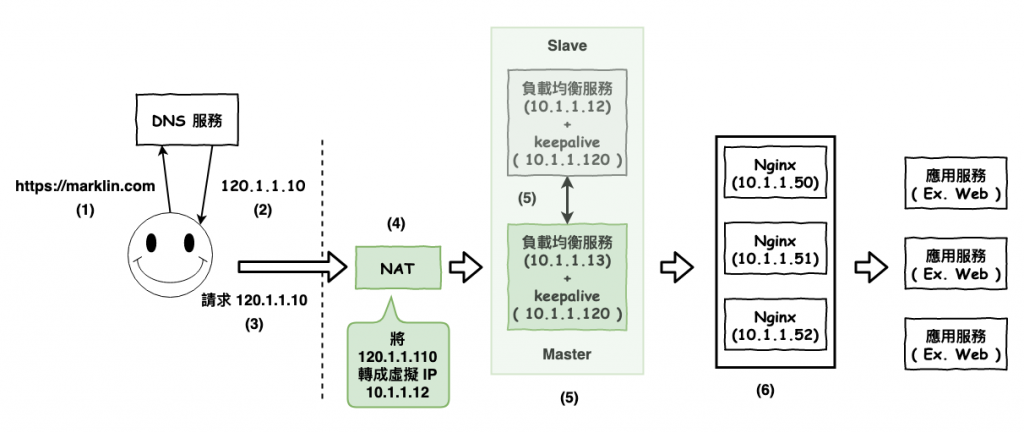
圖 4 : 加入第二層負載均衡。
~ 小備註 ~
lvs 它事實上也有所所謂的 nat 功能,所以事實上可以將前面的 nat 拿掉。
上面基本上就是咱們比較常見的應用層擴展架構,那接下來咱們要來談談,當應用層擴展以下,你通常會碰到的第一個問題 :
那就是 session 如何處理呢 ?
這裡先簡單說一下 session 的概念。
session 簡單的說代表這『 狀態 』,咱們都知道 http 是屬於無狀態的協議,但通常咱們還是會需要有狀態的情況,例如登入以後,接下來的請求就代表這某個人,所以通常運行會是如下圖 6 所示。
注意一下通常咱們會將 sessionId 設定在 cookie 上,如圖 6 的第 2 個步驟,然後接下來的所有請求,都會自動代這個 sessionId 來進行請求,就如同第 3 個步驟,也就代表接下來的請求都是某個用戶所發的。
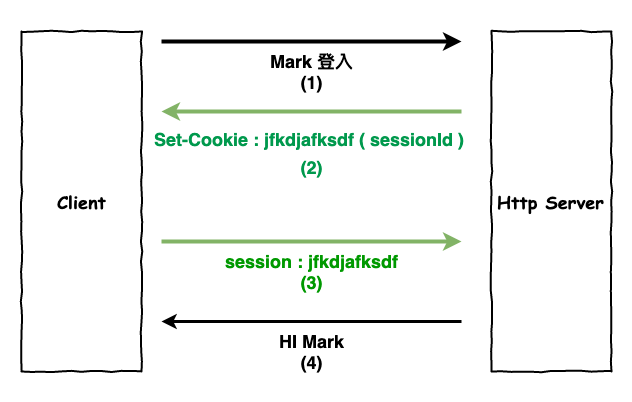
圖 6 : session 狀態
接下來來在應用層擴後,問題就出在 :
session 是存在某一台 server 上
所以如果有多台 server 就會發生如下圖 7 這種事情。
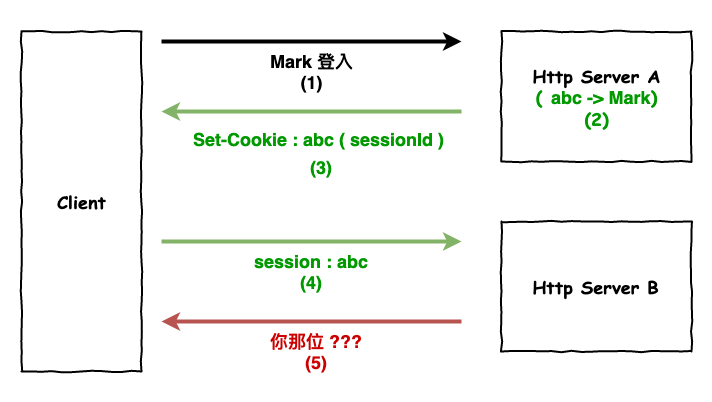
圖 7 : server session 混亂圖
然後在現在咱們看看以下幾個常見的解法。
解法就是將 session Id 所對應到的用戶資訊儲放在外部儲放服務,例如 redis,它的運行流程如下圖 8 所示。
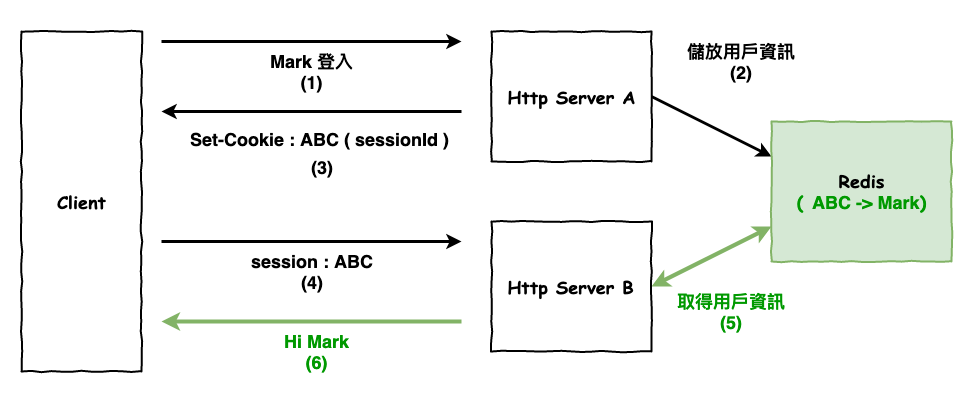
圖 8 : 使用外部儲存服務解決 session 問題
簡單的說就是同一個使用者只會打到同一台 server,這樣就不會發生找不到用戶 session 的問題。這個方法在某些情況下不錯用,例如需要多次請求建立連線的 socket.io,則下一篇會詳說。
然後接下來這個解法嚴格來說就是不要用 session 來代表 user,而改用 token 來代表 user,這個 token 的產生方法有不少,不過比較常看到的是所謂的『 JWT Token 』,這裡就不說它是如何產生,反正它就是個 token,只是它是不好破的東東。
然後這裡有個重點那就是 :
token 中包含使用者資訊
也就是說 server 解完這個 token 後,它就知道是誰了,也就不需要在去其它地方拿用戶資料。
接下來咱們看一下這個方法的流程,如下圖 9 所示,由於 server 又變回所謂的『 無狀態 』模式後,又沒有擴展所帶來的問題囉。
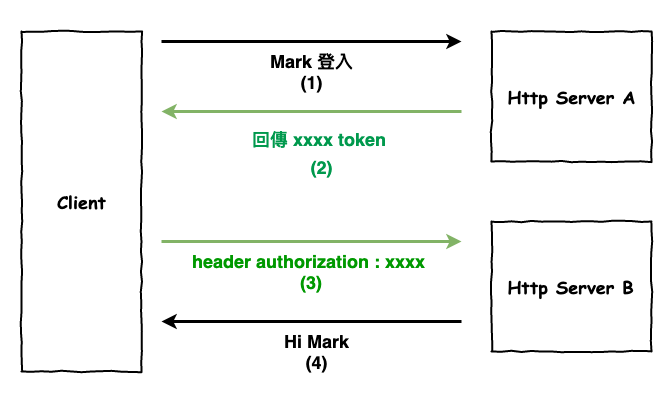
圖 9 : token 的解決流程
本篇文章中,咱們簡單的學習了應用層的基本擴展,最基本的用法就是前面加一台負載均衡服務,然後後面在放幾台應用層服務。
但是這感覺沒啥毛病啊 ? 好像也沒有發生什麼一致性的問題啊 ?
嗯對在大部份的情況下,應用層如果用上述這種基本擴展,是沒啥毛病的,因為每一台基本上都是獨立無相關,唯一相關的項多就是咱們上面提到的 session 問題。
但如果是有相關的話,就不是很好處理了……

