當我們有了一系列的匹配資料之後,
我並不知道每個影像之間的相機姿態資訊
(當然有些影像可能會有GPS或是有些影像定位系統會有IMU搭配計算誤差),
我必須先挑兩個匹配良好的影像進行第一次的點雲初始化,
再無序的影像資料中,如何挑選哪兩張影像作為第一次的點雲初始化也是種學問,
點雲的初始化好壞會直接影響之後相機姿態的估計,
而這邊因為知道影像是有序的就直接拿前兩張影像做點雲的初始化。
類似於我們之前找兩個影像的基礎矩陣,然而這次我們因為有對相機做校正,
所以我們可以從基礎矩陣從中提取本質矩陣(Essential Matrix),
進而推估兩個影像之間的相機姿態。
std::vector<cv::Point2d> init_point_img1, init_point_img2;
init_point_img1.reserve(ALL_good_matches[0][0].size());
init_point_img2.reserve(ALL_good_matches[0][0].size());
for (auto i = ALL_good_matches[0][0].begin(); i != ALL_good_matches[0][0].end(); i++)
{
init_point_img1.emplace_back(cv::Point(list_of_keypoints[0].at(i->queryIdx).pt.x, list_of_keypoints[0].at(i->queryIdx).pt.y));
init_point_img2.emplace_back(cv::Point(list_of_keypoints[1].at(i->trainIdx).pt.x, list_of_keypoints[1].at(i->trainIdx).pt.y));
}
cv::Mat E, R, t, mask_ofE;
E = findEssentialMat(init_point_img1, init_point_img2, cameraMatrix, cv::RANSAC, 0.999, 1.0, mask_ofE);
我們先從匹配表取出ALL_good_matches[0][0]也就是第一張相片與第二張相片特徵點的匹配,
透過匹配表回去查詢對應的特徵點清單,找到對應的特徵點影像座標,
塞入std::vectorcv::Point2dinit_point_img1、init_point_img2準備之後求解本質矩陣所需要的參數
求解完之後透過將本質矩陣分解成R|t,從中得知兩張相片之間的運動方式,
recoverPose(E, init_point_img1, init_point_img2, cameraMatrix, R, t, mask_ofE);
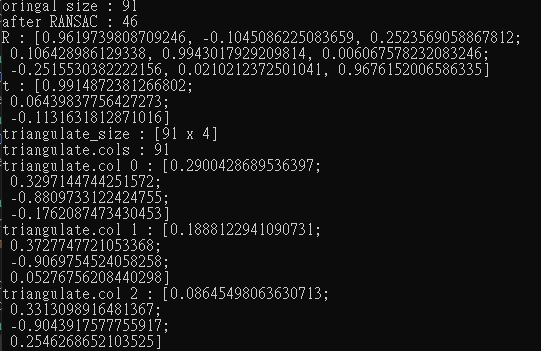
std::cout << "oringal size : " << init_point_img1.size() << std::endl;
std::cout << "after RANSAC : " << countNonZero(mask_ofE) << std::endl;
cv::Mat image01;
image01 = cv::imread(imagelist[0], cv::IMREAD_COLOR);
cv::resize(image01, image01, cv::Size(640, 480), 0, 0, CV_INTER_AREA);
cv::Mat image02;
image02 = cv::imread(imagelist[1], cv::IMREAD_COLOR);
cv::resize(image02, image02, cv::Size(640, 480), 0, 0, CV_INTER_AREA);
cv::Mat img_Match_E;
cv::drawMatches(image01, list_of_keypoints[0], image02, list_of_keypoints[1], ALL_good_matches[0][0], img_Match_E, cv::Scalar::all(-1), cv::Scalar::all(-1), mask_ofE, cv::DrawMatchesFlags::NOT_DRAW_SINGLE_POINTS);
cv::imshow("img_Match_E", img_Match_E);
std::cout << "R : " << R << std::endl;
std::cout << "t : " << t << std::endl;
cv::Mat triangulate;
recoverPose(E, init_point_img1, init_point_img2, cameraMatrix, R, t,1.0, mask_ofE, triangulate);
std::cout << "triangulate_size : " << triangulate.size() << std::endl;
std::cout << "triangulate.cols : " << triangulate.cols << std::endl;
for (size_t i = 0; i < triangulate.cols; i++)
{
std::cout << "triangulate.col "<<i <<" : "<< triangulate.col(i) << std::endl;
}
cv::waitKey();
而分解完畢之後recoverPose似乎也有triangulation的overload,
我嘗試將其結果輸出出來,以便對照之後呼叫 triangulatePoints()的結果。
初步來看findEssentialMat會將原本91個點過濾掉剩下46個去求解本質矩陣,
而在recoverPose的時候,會將全部的匹配點都做三角測量回復其3D資訊,
這邊看輸出的結果triangulate的size是91X4
其點座標應該是齊次座標的形式,未來在使用solvePNP算第三張第四張影像的姿態的時候,
應該還需要做正規化的處理,
而其順序應該是對應匹配表裡面特徵匹配的順序。

