在前面監控的部份,作為單一系統使用,基本上是可行的。但,若要運用在實際環境,還是有些問題,需要解決。
因異常終止的原因,造成其他相依服務的異常,必然會造成使用者的困擾。所以必需 確保系統在不管在何種情況下,都能持續提供服務。這種特性,又稱為不死性、復原力或軔性。
需求四、當系統異常終止後,可自己重新啟動。
要達到這個目標,就需要額外建立一個服務,姑且先稱為 Manager。在 Node 中,增加一個 EchoLift 的元件,負責跟 Manager 的溝通。
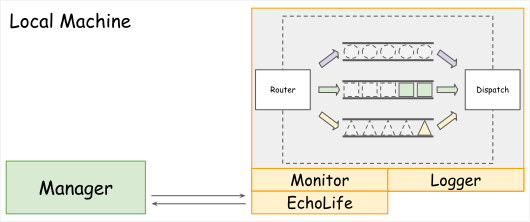
Manager 這個服務本身的責任很單純,就是週期性的固定詢問 Node 的狀態。當 Node 無回應時,就必需進行處理,移除無反應的服務與重新啟動服務。
對本機而言,只要有權限,一個服務可以輕易控制其他服務。所以當 Node 發生異生,Manager 就可以直接刪除、建立 Node 的服務。
但對於兩支服務放置於不同主機的情形下,就沒有那麼容易。就需要再一個服務Agent來負責 Node 的移除與啟動。同时,它也可能作為 Node-EchoLift 與 Manager 的溝通橋樑。
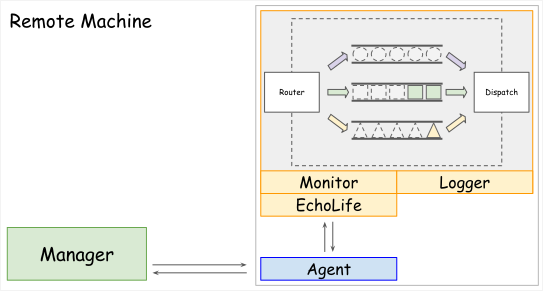
可是這樣又延伸另一個問題,Manager 與 Agent 要如何得知道對方的位置?最簡易的方式,就是採用 Configuration 的方式,記錄對方的位置。
當儲存在 Manager 的 configuration 之中,表示 Manager 需要主動去訪查 Agent ,Node 數量少還可以,數量一多,維運時的管理就會變成一個負擔。
依筆者的想法,將 Manager 的連線位置記錄於 Agent 的 configuration 是比較好的作法,考量點如下:
相關的作法有 Service Registory、Service Mash、Service Disvery ,這些後面會簡單提到。有興趣的人,可以看 Rick 大寫的 聊聊分散式系統。

