今天是筆記的最後一天,
終於暫時可以告別每天看投影片、Paper的日子,
我都覺得這一次的複習比去年上課準備期末考還認真 xD
也因此這一次從頭檢視學過的知識,對於之前所學有了更深刻全面的了解,
也有了一些新的體悟。
在現今的商業世界中,
可以說基本上絕大多數的人會面臨的流量、市場只用最簡單的3-tier web architecture就可以解決。
而你的系統在走入分散式架構前,
你會有101招大學四年資工系本科 OS/Archi/DataStructure/Database 就學過的技巧,
來優化你原本的系統:
在系統走入分散式系統前,這些基本功非常重要,也很大程度可以解決絕大多數人面臨到的效能問題。
所以為什麼要學分散式系統呢?
這個問題由你我來回答可能沒什麼想法,畢竟不需要,是嗎?
反過來說,為什麼會有這麼多分散式系統的研究、paper一直在產出?
已經有了2PC、3PC,為什麼會有Paxos共識演算法為什麼會有Raft的出生?
已經有了RPC,為什麼會有RabbitMQ的出現,與K8s的Event Trigger機制,甚至RPC進化成gRPC?
已經有了OpenStack這樣的IaaS,為什麼又生出了K8s PaaS,甚至SaaS?
最大的原因還是有需要,誰需要呢?Global Company
他面臨的是全球的流量,資料不只需要做備份並放到五大洲角落的機房,還需要做Partitioning,
一個Client可能同時從不同的角落使用他的服務,他就面臨了Consensus Problem。
但是真的只有他需要嗎?不,你也需要(面試的時候XD)
大家都知道網站部署時可以用CDN服務Akamai,幫你把你的內容放到好幾個Replica Servers中,讓使用者使用服務時可以有地利之便,除了加速外還可以分散流量。
這是分散式系統啊,
他要解決多個Replica Servers的Caching/Replication問題,
關鍵字: il2p
George Pallis, Konstantinos Stamos, Athena Vakali, Dimitrios Katsaros, Antonis Sidiropoulos, Yannis Manolopoulos.
"Replication based on Objects Load under a Content Distribution Network", In Proceedings of the 2nd IEEE International Workshop on Challenges in Web Information Retrieval and Integration (WIRI) (In conjunction with ICDE'06), IEEE Press, Atlanta, Georgia, USA, April 3rd, 2006.
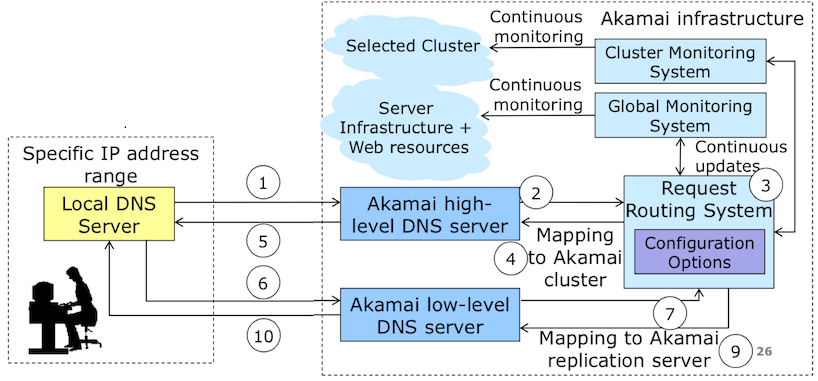
他要解決Routing/DNS問題,
這30天的內容都是他的基礎。
網站設計牽扯到多個資料庫,
如何用2PC來做跨資料庫的Transaction (好像有既視感?PXX?)
你要知道2PL來Serialized 多個平行的 Transactions,
你要知道Vector Clock來比較系統之事件發生先後次序,
A發送請求給B,Message可能丟失,你要知道RPC提到的At-most-once機制,避免B多次執行同一個請求。
網路上一堆系統經典面試題
Cache是網站加速必提的技術
Facebook洋洋灑灑寫了一篇論文 "Scaling Memcache at Facebook" 整篇就講效能如何再加速
裡面也提到了Distributed Hash Table來做Data Partitioning
ㄧ樣實際點,面試也會碰到像這樣的經典問題
現在MicroServices正夯,
最重要的一個核心就是服務發現
你可能使用Consul、Zookeeper或是etcd,他們本身就是分散式系統
把玩K8s絕不會漏掉Rook/Ceph,
他也是分散式儲存,
什麼是Volume、File、Object Store,
他怎麼使用CRUSH這種Distributed Hash Table來把資料做Partitioning與Replication放到他的儲存單元裡。
即使服務在AWS上面,所有底層的那些分散式服務通通抽象掉你都看不見,
但是默默的你搭出來的系統也是分散式系統,
怎麼做Autoscaling來加更多replica servers應付流量,
如果客製化Proxy怎麼實作 (E.g. Zookeeper Reverse Proxy)。
最後攤開DynamoDB的論文,也是綜合了這30天的內容。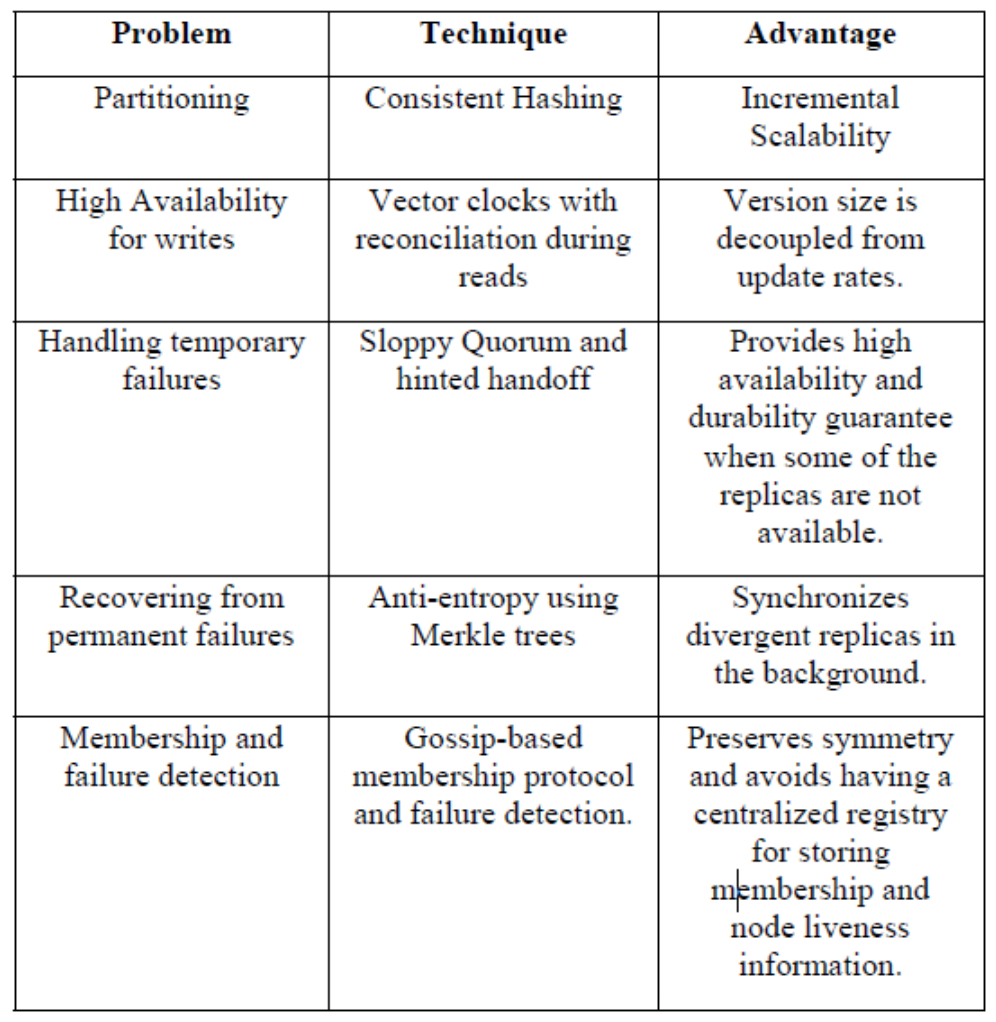
Consistent Hashing、Vector Clock、Sloppy Quorum/Hinted Handoff、Merkle Trees 全部攬在同一篇論文中。
所以為什麼學分散式系統?
因為,
我們已經在不知不覺中站在巨人的肩膀了,
如果不認識一下巨人長什麼樣子不是很無聊嗎
30天的內容說長不長,說短不短。
這一個系列雖然沒有像預期中的寫完所有主題,像是Distributed File System、Distributed Message Queue、Distributed Cache等
但是也剛剛好
Data Replication + Data Partitioning 完整的介紹完
符合了大主題 - "分散式系統 - 在分散的世界中保持一致"
如果內容有任何的錯誤還請多多指教 ><
也希望這30天有帶給大家一點點新知!

