一、Jetson Nano 介紹以及安裝
Jetson Nano是由Nvidia所開發的邊緣運算設備,大小僅只有75x45 mm,具備 472 GFLOP 的運算能力,可快速執行現代人工智慧演算法並且只需耗費5~10瓦就可以達到強大的運算能力,以下就開始介紹環境安裝流程
首先準備16G以上的SD卡,到這個網址 下載jetson nano image後,用rufus或image writer燒入,使用然後插入板子後方接電後會自動開啟,再來就是ubuntu介面系統安裝流程,這邊就不多做介紹。

最後成功進入桌面如下
之後為了節省不必要螢幕顯示,我就直接安裝 ssh (sudo apt-get install openshh-server) 透過遠端連線方式進行操作, 因為我這邊是接無線網卡所以是設置無線網路的固定ip
#vim /etc/network/interfaces
auto wlan0
iface wlan0 inet static
address 192.168.1.51
netmask 255.255.255.0
gateway 192.168.1.1
wpa-ssid wifi #wifi名稱
wpa-psk rootroot #wifi密碼
二、Tensorflow 安裝
1.安裝tensorflow 所需的套件
sudo apt-get install python3-pip python3-dev
sudo apt-get install libhdf5-serial-dev hdf5-tools libhdf5-dev zlib1g-dev zip libjpeg8-dev
2.安裝tensorflow-gpu
我是安裝1.13.1版本的tensorflow ,原先沒有特別指定版本安裝了1.14版遇到很多的問題才降至1.13
sudo pip3 install --extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v42 tensorflow-gpu==1.13.1+nv19.4
3.Swap
由於Jetson nano只有 4G 的記憶體,inference的時候容易會超過導致當機,所以需要Swap
sudo fallocate -l 6G /swap
sudo chmod 600 /swap
ls -lh /swap
sudo mkswap /swap
sudo swapon /swa
#重啟後自動掛載
sudo cp /etc/fstab /etc/fstab.bak
echo '/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab
這邊也有別人寫好的bash檔(連結),直接下bash installSwapfile.sh 也可以幫你建好6G 的Swap
三、Inference model
這邊我是使用自己訓練的SRCNN Model進行inference,先將frozen model透過tensorRT優化後寫成另一個.pb檔,如果沒有訓練好的模型可以到tensorflow官網下載
def save_frozen_to_trt():
with tf.gfile.GFile('frozen_srcnn.pb', 'rb') as f:
frozen_graph = tf.GraphDef()
frozen_graph.ParseFromString(f.read())
#TensorRT 優化
trt_graph = trt.create_inference_graph(
is_dynamic_op=True,
input_graph_def=frozen_graph,
outputs=["out_pred"], #模型的output node name
max_batch_size=1,
max_workspace_size_bytes=1<<25, #配給TensorRT的記憶體空間
precision_mode="FP16") #FP32/16 INT8
with gfile.FastGFile("tensorRT_model.pb", 'wb') as f:
f.write(trt_graph.SerializeToString())
再來是讀取優化後的pb,透過get_tensor_by_name方法找到模型中的輸入輸出,我訓練的模型輸入需要300X300的圖片,先將SET5使用opencv resize過並且修改rgb後,就可以丟到模型中inference。
def inference_trt():
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction = 0.7)
tf_config = tf.ConfigProto(gpu_options=gpu_options)
tf_config.gpu_options.allow_growth = True
with tf.Graph().as_default() as graph:
with tf.Session(config=tf_config) as sess:
#read TensorRT model
trt_graph = read_pb_graph('TensorRT_model.pb' )
#取得模型input、output *tensor name
tf.import_graph_def(trt_graph, name='')
input_node = sess.graph.get_tensor_by_name('images:0')
output_node = sess.graph.get_tensor_by_name('out_pred:0')
image = cv2.imread('butterfly_GT.bmp',cv2.IMREAD_COLOR)
resize_image = cv2.resize(image,(300,300),interpolation=cv2.INTER_CUBIC)
#將opencv取得的矩陣bgr 改為rgb
b,g,r = cv2.split(resize_image)
origin_img = cv2.merge([r,g,b])
rgb_img = origin_img/255.0
test_list = list()
test_list.append(rgb_img)
input_dict = {input_node: test_list}
for i in range(0,10):
start = int(round(time.time() * 1000))
out_pred = sess.run(output_node, feed_dict=input_dict)
end = int(round(time.time() * 1000))
print("inference cost %d ms "%((end-start)))
#rgb 轉回bgr後儲存
image =out_pred[0,:,:,:]
r,g,b = cv2.split(image)
pred_img = cv2.merge([b,g,r])
cv2.imwrite('butterfly.bmp', pred_img*255)
下面圖片為執行時間跟輸出的圖片、每次執行的第一張圖需要warm up需要久一點,雖然TensorRT的執行速度較原本的快一些,但是warm up時間反而是原先的frozen model快很多,這邊還在思考是什麼原因造成的。
tensorRT model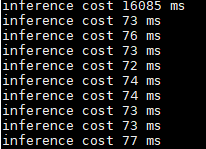
frozen model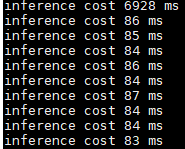
output
備註:jetson nano讀取模型時可能會很久很久,我嘗試使用deeplabv3,僅讀取模型就花費時間大概是15~20分鐘左右,這個問題可以參考這篇文章,安裝protobuf-python3,它使用c++方式去讀取,安裝時間需要很久,但讀取deeplab模型直接降為20秒左右。
以上是jetson nano的簡單使用~
參考
https://medium.com/aiot-taipei/jeston-nano-tensorflow-gpu-%E5%AE%89%E8%A3%9D-b26d42f7c3f3https://developer.nvidia.com/embedded/learn/get-started-jetson-nano-devkit#next



 iThome鐵人賽
iThome鐵人賽