
今天要介紹的是 「爬蟲」,我會使用 HttpClient 和 Regex 實作靜態爬蟲,結合前兩篇的內容完成 「it 幫文章瀏覽數增加排名」 功能。
完整功能如下:
爬蟲可以分為 靜態爬蟲 和 動態爬蟲。
程式取得 Response 後,直接分析網頁原始碼獲取所需資訊,這類型的爬蟲稱為靜態爬蟲,直接呼叫 API 的也算此類。
而動態爬蟲則是為了因應 SPA 網站而生,SPA 網站使用大量的 AJAX 技術,必需透過 JS 引擎執行網頁,才能獲得所需資訊,這類的稱為動態爬蟲。
it 幫屬於可以直接分析原始碼的網站,所以使用靜態爬蟲即可
這篇我會使用 C# 的 HttpClient 和 Regex 實作,因為功能簡單,就不另外找爬蟲套件。
這篇內容會接續之前介紹的東西,想了解完整過程的讀者可以先看。
[Day08] 使用 WebJob + Logic App 製作定時排程器
爬蟲簡單來說就是透過程式,模擬瀏覽器送出 Request 的動作,取得網頁原始碼,在 C# 可以使用 HttpClient 完成此操作。
GET 是最常用到的方法,在瀏覽器上以輸入網址的方式進入網站,就屬於此法。
using (var client = new HttpClient())
{
var html = await client.GetStringAsync("https://xxxxx");
}
本篇只會用到 GetStringAsync 方法,以下內容可以略過。 (́◕◞౪◟◕‵)*
POST 常見於需要填表的地方,例如: 查詢火車時刻表,需要填出發、抵達站。
using (var client = new HttpClient())
{
var data = new FormUrlEncodedContent(new Dictionary<string, string>
{
["出發站"] = "台中",
["抵達站"] = "台北"
});
var response = await client.PostAsync("https://xxxxx", data);
//如果失敗會拋出錯誤
response.EnsureSuccessStatusCode();
//取得結果
var html = await response.Content.ReadAsStringAsync();
}
這個比較少見,很少用到。
using (var client = new HttpClient())
{
using (var data = new MultipartFormDataContent())
{
//一般欄位
data.Add(new StringContent("台中", Encoding.UTF8), "出發站");
data.Add(new StringContent("台北", Encoding.UTF8), "抵達站");
//檔案
var streamContent = new StreamContent(File.OpenRead("xxx.jpg"));
streamContent.Headers.Add("Content-Type", "image/jpg");
data.Add(streamContent);
var response = await client.PostAsync("https://xxxxx", data);
//如果失敗會拋出錯誤
response.EnsureSuccessStatusCode();
//取得結果
var html = await response.Content.ReadAsStringAsync();
}
}
網站如果未設定 CharSet 或設錯了,資料會出現亂碼。
有兩種做法:
using (var client = new HttpClient())
{
var response = await client.GetAsync("https://xxxxx");
//如果失敗會拋出錯誤
response.EnsureSuccessStatusCode();
//設定編碼
response.Content.Headers.ContentType.CharSet = "gb2312";
//取得結果
var html = await response.Content.ReadAsStringAsync();
}
using (var client = new HttpClient())
{
//取得 bytes
var bytes = await client.GetByteArrayAsync("https://xxxxx");
//自行轉換編碼
var html = Encoding.GetEncoding("gb2312").GetString(bytes, 0, bytes.Length);
}
※ 補充說明:
在 .NET Core 中無法直接使用 gb2312 編碼
需安裝套件 (Nuget)
並在使用前呼叫此方法
System.Text.Encoding.RegisterProvider(System.Text.CodePagesEncodingProvider.Instance);
內容來源:
https://www.cnblogs.com/chr-wonder/p/8464204.html
有些網站會阻擋爬蟲,這時可以將爬蟲偽裝成瀏覽器。
using (var client = new HttpClient())
{
//增加 User-Agent 標頭
client.DefaultRequestHeaders.Add("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36");
//取得結果
var html = await client.GetStringAsync("https://xxxxx");
}
如果遇到需要登入的網站,可以開啟 Cookie 維持登入狀態。
using (var httpClientHandler = new HttpClientHandler())
{
//開啟 Cookie
httpClientHandler.UseCookies = true;
using (var httpClient = new HttpClient(httpClientHandler))
{
var html = await httpClient.GetStringAsync("https://xxxxx");
}
}
手動操作 Cookie 也可以。
using (var httpClient = new HttpClient(httpClientHandler))
{
var baseUrl = "https://xxxxx";
//取得 Cookies 的方式
var cookies = httpClientHandler.CookieContainer.GetCookies(new Uri(baseUrl)).Cast<Cookie>();
//設定 Cookie 的方式
httpClientHandler.CookieContainer.Add(new Uri(baseUrl), new Cookie("aaa", "123"));
//取得結果
var html = await httpClient.GetStringAsync("https://xxxxx/QQ");
}
爬蟲怎麼能少了檔案下載。
using (var httpClient = new HttpClient())
{
var response = await httpClient.GetAsync("https://xxxxx");
using (var stream = await response.Content.ReadAsStreamAsync())
{
//儲存檔案
var fileInfo = new FileInfo("xxx.jpg");
using (var fileStream = fileInfo.OpenWrite())
{
await stream.CopyToAsync(fileStream);
}
}
}
有了檔案下載,自然會想知道下載進度。
需安裝的套件 (Nuget):
var progress = new ProgressMessageHandler();
progress.InnerHandler = new HttpClientHandler();
progress.HttpReceiveProgress += (sender, e) =>
{
//取得工作百分比
var progress = e.ProgressPercentage;
};
using (var httpClient = new HttpClient(progress))
{
var response = await httpClient.GetAsync("https://xxxxx");
using (var stream = await response.Content.ReadAsStreamAsync())
{
//儲存檔案
var fileInfo = new FileInfo("xxx.jpg");
using (var fileStream = fileInfo.OpenWrite())
{
await stream.CopyToAsync(fileStream);
}
}
}
開始之前推薦一個 Regex 網站,開發測試都很方便。
https://regex101.com/
| Regex | 說明 |
|---|---|
| . | 比對任意字元 |
| a | 比對 a |
| 0 | 比對 0 |
| \s | 比對空白字元 (包含空白、換行、Tab) |
| \S | 比對非空白字元 (同上) |
| Regex | 說明 | 範例 |
|---|---|---|
| [0-9] | 包含數字的字串 | 123 |
| [a-z] | 包含小寫字母的字串 | abc |
| [a-zA-z] | 包含大寫或小寫字母的字串 | ABC |
| [abc] | 包含 abc 其中一個字母的字串 | adc |
| [^0-9] | 不包含數字的字串 | xyz |
| Regex | 說明 | 範例 |
|---|---|---|
| ^abc | 開頭是 abc 的字串 | abcd |
| xyz$ | 結尾是 xyz 的字串 | ggxyz |
| ^a[0-9]z$ | 開頭是 a,結尾是 z,中間是數字的字串 | a5z |
| Regex | 說明 | 範例 | 錯誤範例 |
|---|---|---|---|
| [0-9] * | 比對 0 - n 個數字 | 123456 | abc |
| abc+ | 比對 ab 後面接著 1 - n 個 c | abccc | ab |
| a{3} | 比對 3 個 a | aaa | aa |
| a{2,} | 比對 2 - n 個 a | aaaaa | a |
| a{2,5} | 比對 2 - 5 個 a | aaa | aaaaaa |
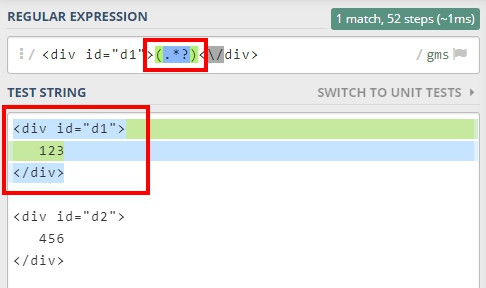
問號除了可以表示次數外,還可以表示 「最短距離」。
什麼是最短距離???
這裡的最短距離是指最短字串的意思,因為 Regex 預設採用貪婪法,會匹配符合規則的最長字串,加上問號則表示匹配最短字串。
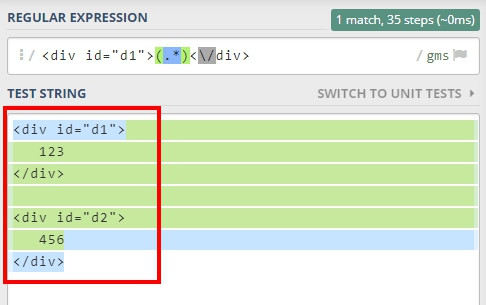
舉個例子,假設有兩個 <div> 如下。
<div id="d1">
123
</div>
<div id="d2">
456
</div>
我想取得 d1 的內容,直覺會這樣寫。
//用 .* 取得中間的內容 (single line)
<div id="d1">(.*)<\/div>
不過結果如下,d2 也被包含在其中,因為預設會取符合規則的最長字串。
這時可以用問號表示要取最短字串。
正規式可以使用 「小括號」 表示群組。
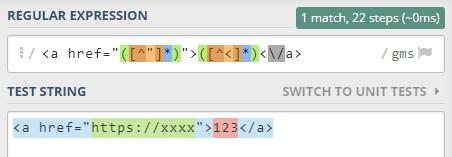
例如,有個 <a> 標籤如下,如何在一個正規式內,將網址和文字分開。
<a href="https://xxxxx">123<\/a>
可以這樣寫。
<a href="([^"]*)">([^<]*)<\/a>
結果如下,網址和文字被分成兩個不同的群組。
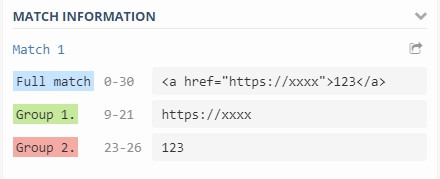
翻譯是斷言,不過我覺得從字面上很難看出它的用途,我挑兩個常用的介紹。
有「向前看」的意思,不過我更喜歡理解為「比對後方」。
//寫法
aaa(?=xxx)
意思是比對 aaa 後面接著 xxx 的字串,且比對後的結果不會包含自己。
舉個例子,我想比對 <a> 標籤前的 <div>,可以這樣寫
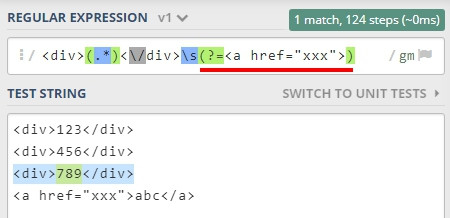
有「向後看」的意思,不過我更喜歡理解為「比對前方」。
//寫法
(?<=xxx)aaa
意思是比對 aaa 前面接著 xxx 的字串,且比對後的結果不會包含自己。
舉個例子,我想比對 <a> 標籤後的 <div>,可以這樣寫
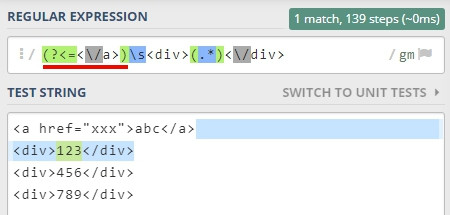
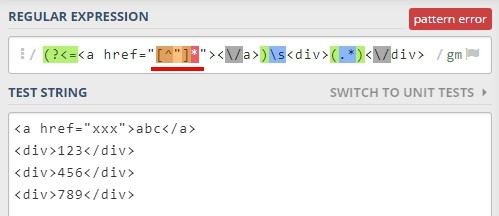
要注意的是 lookbehind 內,不能寫 「*」 或 「+」 這類不固定字元數的規則,
而 lookhead 則沒有此限制,如下。
一般正規式比對時,比對過的字元是不會回頭比的,不過 lookhead 例外,它具有可回朔的特性,舉個例子。
有一段 HTML 如下。
<ul>
<li>1</li>
<li>2</li>
<li>3</li>
</ul>
<ol>
<li>4</li>
<li>5</li>
<li>6</li>
</ol>
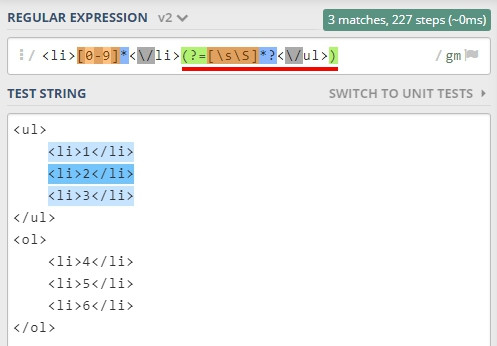
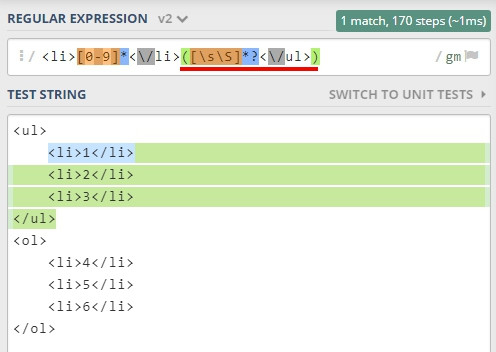
如果想匹配 <ul> 內的所有 <li> 可以這樣寫。
<li>[0-9]*<\/li>(?=[\s\S]*?<\/ul>)
比對過程:
1.比對第一組 <li>1</li>
2.接著 [\s\S]*? 會比對中間所有的 <li>
3.最後遇到 <\/ul> 時完成第一組完整的匹配
接下來換比第二組時,就會發生回朔,會從第一組的結尾繼續往下找,而不是直接結束,因為一般比對,比過的地方是不會回頭比的,而 lookhead 卻打破了這個規則,所以我才稱之為回朔,但我不知道真正的原因是什麼,這個歡迎有經驗的大大分享。
一般的寫法如下。
HttpClient 和 Regex 都介紹完了,接下來要進入爬蟲實作的部分。
功能可以分為三個部分:
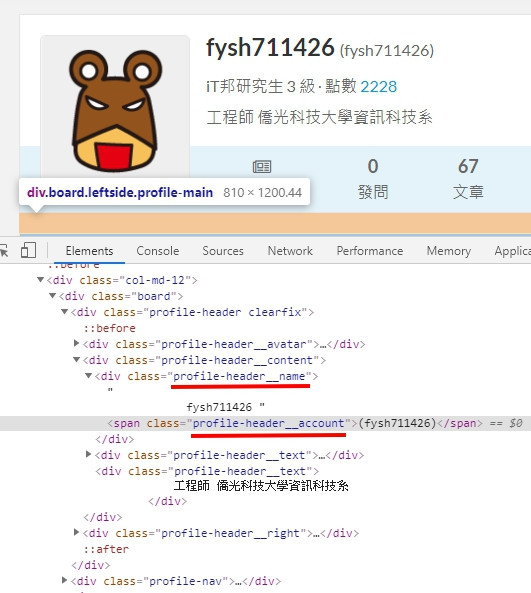
第一步需要觀察 HTML,找到所需資訊的位置,不過原始碼不好直接閱讀,需要輔助工具,我會使用 Chrome 的開發人員視窗,快捷鍵是 F12,開啟後對畫面按右鍵,選擇檢查,可以快速移動到指定標籤上。
暱稱和帳號可以從 profile-header__name 和 profile-header__account 取得。
程式如下,使用 HttpClient 取得 html 原始碼,接著使用 Regex 將資訊取出。
//取得個人資訊
private async Task<(string name, string account)> GetUserInf(HttpClient httpClient, string url)
{
var html = await httpClient.GetStringAsync(url);
//取得名稱
var name = Regex.Match(html, @"(?<=class=""profile-header__name"">)([^<]*)").Value.Trim();
//取得帳號
var account = Regex.Match(html, @"(?<=class=""profile-header__account"">\()(.*?)(?=\)<)").Value;
return (name, account);
}
Regex 說明:
(?<=class="profile-header__name">)([^<]*)
從 profile-header__name"> 的地方開始取,取 n 個不等於 < 的字元。
(?<=class="profile-header__account">\()(.*?)(?=\)<)
從 profile-header__account">( 的地方開始取,取 n 個字元 (最短距離),
後面需接著 )<。
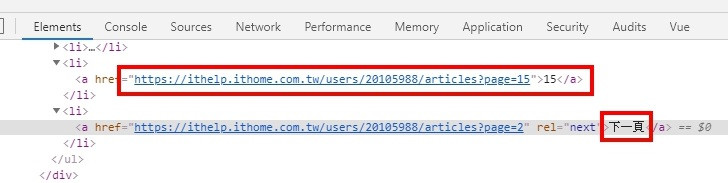
it 幫的分頁還蠻好取的,因為分頁是用 QueryString 串在網址後面。
https://xxxxx?page=10
只需要取得最大頁碼,再跑個迴圈就可以得到所有的網址。

只要找到 「下一頁」 前一個 <li>,就可以得到最大頁碼。
程式如下
//取得所有分頁網址
private async Task<List<string>> GetPaginations(HttpClient httpClient,string url)
{
var result = new List<string> { url };
var html = await httpClient.GetStringAsync(url);
//篩選出 <ul> 區塊的 html
var ul = Regex.Match(html, @"(?<=<ul class=""pagination"">)([\s\S]*?)(?=<div class=""rightside)").Value;
//取得所有 <li>
var matches = Regex.Matches(ul, @"<li><a href=""([^""]*)"">([^<]*)");
//最後一個匹配項目
var lastMatch = matches.ToList().LastOrDefault();
//找到最大的頁碼,沒有匹配項表示只有一頁
var maxPage = lastMatch.Success ? int.Parse(lastMatch.Groups[2].Value) : 1;
for (var i = 2; i <= maxPage; i++)
{
result.Add($"{url}?page={i}");
}
return result;
}
Regex 說明:
(?<=<ul class="pagination">)([\s\S]*?)(?=<div class="rightside)
從 class="pagination"> 的地方開始取,取 n 個字元 (最短距離),後面需接著 <div class="rightside,因為中間有換行 * 會被斷開,所以用 [\s\S]。
<li><a href="([^"]*)">([^<]*)
使用小括號分組,取得網址和頁碼。
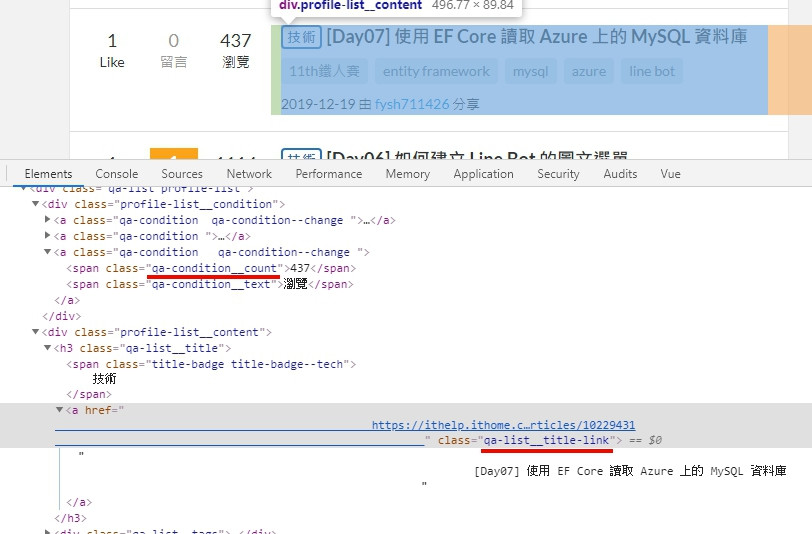
接著將上一步得到的所有分頁網址都跑過一次,就可以得到所有的文章資訊,網址、標題、瀏覽數,可以透過 qa-condition__count 和 qa-list__title-link 取得。
正規式內使用 Group,將瀏覽數、網址、標題一次取出。
程式如下
//取得文章網址、標題、瀏覽數
private async Task<List<(int viewCount, string url, string title)>>GetArticles(HttpClient httpClient, string url)
{
var html = await httpClient.GetStringAsync(url);
//取得所有文章項目
var matches = Regex.Matches(html, @"([0-9]+)(?=<\/span>[\s]*?<span class=""qa-condition__text"">瀏覽)[\s\S]*?<a href=""([^""]*)[^>]*>([\s\S]*?)<\/a>");
return matches.ToList()
.Select(it =>
{
var viewCount = int.Parse(it.Groups[1].Value);
var url = it.Groups[2].Value.Trim();
var title = it.Groups[3].Value.Trim();
return (viewCount, url, title);
})
.ToList();
}
Regex 說明:
([0-9]+)(?=<\/span>[\s]*?<span class="qa-condition__text">瀏覽)[\s\S]*?<a href="([^"]*)[^>]*>([\s\S]*?)<\/a>
這段分為三個部分。
([0-9]+)(?=<\/span>[\s]*?<span class="qa-condition__text">瀏覽)
第一部分匹配瀏覽數,取 1-n 個 0-9 字元,後面需接著 qa-condition__text">瀏覽,中間的 [\s]*? 用來匹配 HTML 間的空白和換行。
<a href="([^"]*)
第二部分匹配網址,找到 <a href=" 接著取 n 個不等於 " 的字元。
>([\s\S]*?)<\/a>
第三部分匹配標題,要取 <a> 中間的內容,從 > 開始取 n 個字元,到 <\/a> 的最短距離,內容有換行所以用 [\s\S]。
完整程式
public class Worker : IHostedService
{
private readonly IHostApplicationLifetime _lifeTime;
private readonly CoreDbContext _db;
public Worker(IHostApplicationLifetime lifeTime, CoreDbContext db)
{
_lifeTime = lifeTime;
_db = db;
}
public Task StartAsync(CancellationToken cancellationToken)
{
Task.Run(() =>
{
//使用新執行續執行
ExecuteAsync().ConfigureAwait(false).GetAwaiter().GetResult();
//可以用 Console.WriteLine 輸出 Log
Console.WriteLine("Finish!!");
//結束後關閉視窗
_lifeTime.StopApplication();
});
return Task.CompletedTask;
}
public Task StopAsync(CancellationToken cancellationToken)
{
return Task.CompletedTask;
}
public async Task ExecuteAsync()
{
//現在時間
var now = DateTime.Now;
//從 DB 取得所有被訂閱者資訊
var iTHomeList = await _db.ITHomes.ToListAsync();
using var httpClient = new HttpClient();
foreach (var iTHome in iTHomeList)
{
//更新個人資訊
var userInfo = await GetUserInfo(httpClient, iTHome.Url);
iTHome.Name = userInfo.name;
iTHome.Account = userInfo.account;
await _db.SaveChangesAsync();
//從 DB 取得所有文章
var iTHomeArticleDictionary = await _db.ITHomeArticles
.Where(it => it.ITHomeId == iTHome.Id)
.ToDictionaryAsync(it => it.Url);
//更新文章資訊
var paginations = await GetPaginations(httpClient, iTHome.Url);
var articles = paginations
.SelectMany(
it =>
{
//延遲0.5秒
Thread.Sleep(500);
return GetArticles(httpClient, it)
//將非同步改為同步
.ConfigureAwait(false)
.GetAwaiter()
.GetResult();
})
.ToList();
foreach (var article in articles)
{
var iTHomeArticle = iTHomeArticleDictionary.ContainsKey(article.url)
? iTHomeArticleDictionary[article.url] : null;
//新增
if (iTHomeArticle == null)
{
iTHomeArticle = new ITHomeArticle
{
ITHomeId = iTHome.Id,
Title = article.title,
Url = article.url
};
_db.ITHomeArticles.Add(iTHomeArticle);
iTHomeArticleDictionary.Add(iTHomeArticle.Url, iTHomeArticle);
}
//更新
else
{
iTHomeArticle.Title = article.title;
}
}
await _db.SaveChangesAsync();
//從 DB 取得今日所有瀏覽數
var articleViewCountDictionary = await _db.ArticleViewCounts
//JOIN ITHomeArticle
.Include(it => it.ITHomeArticle)
.Where(it => it.ITHomeArticle.ITHomeId == iTHome.Id)
//只取今天的資料
.Where(it => it.DateTime >= now.Date && it.DateTime < now.Date.AddDays(1))
.ToDictionaryAsync(it => it.ITHomeArticleId);
//更新瀏覽數
foreach (var article in articles)
{
var iTHomeArticle = iTHomeArticleDictionary[article.url];
//如果今天已經新增過,則略過
if (!articleViewCountDictionary.ContainsKey(iTHomeArticle.Id))
{
var articleViewCount = new ArticleViewCount
{
ITHomeArticleId = iTHomeArticle.Id,
ViewCount = article.viewCount,
DateTime = now
};
_db.ArticleViewCounts.Add(articleViewCount);
}
}
await _db.SaveChangesAsync();
}
}
//取得個人資訊
private async Task<(string name, string account)> GetUserInfo(HttpClient httpClient, string url)
{
var html = await httpClient.GetStringAsync(url);
//取得名稱
var name = Regex.Match(html, @"(?<=class=""profile-header__name"">)([^<]*)").Value.Trim();
//取得帳號
var account = Regex.Match(html, @"(?<=class=""profile-header__account"">\()(.*?)(?=\)<)").Value;
return (name, account);
}
//取得所有分頁網址
private async Task<List<string>> GetPaginations(HttpClient httpClient, string url)
{
var result = new List<string> { url };
var html = await httpClient.GetStringAsync(url);
//篩選出 <ul> 區塊的 html
var ul = Regex.Match(html, @"(?<=<ul class=""pagination"">)([\s\S]*?)(?=<div class=""rightside)").Value;
//取得所有 <li>
var matches = Regex.Matches(ul, @"<li><a href=""([^""]*)"">([^<]*)");
//最後一個匹配項目
var lastMatch = matches.ToList().LastOrDefault();
//找到最大的頁碼,沒有匹配項表示只有一頁
var maxPage = lastMatch.Success ? int.Parse(lastMatch.Groups[2].Value) : 1;
for (var i = 2; i <= maxPage; i++)
{
result.Add($"{url}?page={i}");
}
return result;
}
//取得文章網址、標題、瀏覽數
private async Task<List<(int viewCount, string url, string title)>> GetArticles(HttpClient httpClient, string url)
{
var html = await httpClient.GetStringAsync(url);
//取得所有文章項目
var matches = Regex.Matches(html, @"([0-9]+)(?=<\/span>[\s]*?<span class=""qa-condition__text"">瀏覽)[\s\S]*?<a href=""([^""]*)[^>]*>([\s\S]*?)<\/a>");
return matches.ToList()
.Select(it =>
{
var viewCount = int.Parse(it.Groups[1].Value);
var url = it.Groups[2].Value.Trim();
var title = it.Groups[3].Value.Trim();
return (viewCount, url, title);
})
.ToList();
}
}
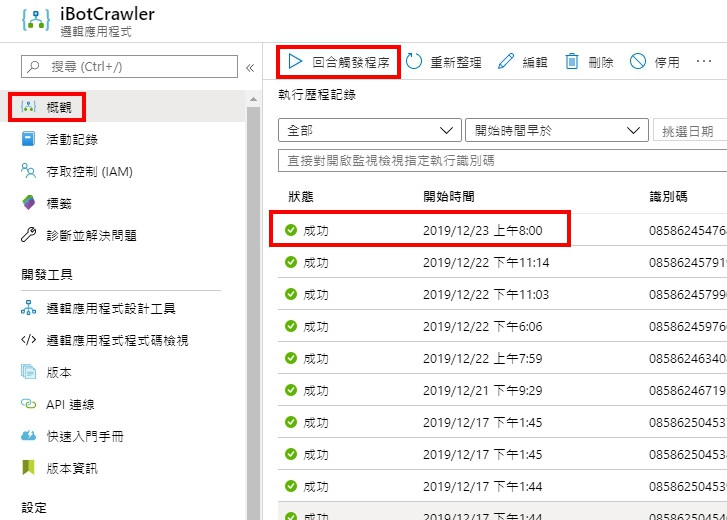
將程式部屬後,開啟 Logic App 測試,部屬方式可以參考上一篇的內容。
選擇回合觸發程序,成功下方會顯示綠色勾勾
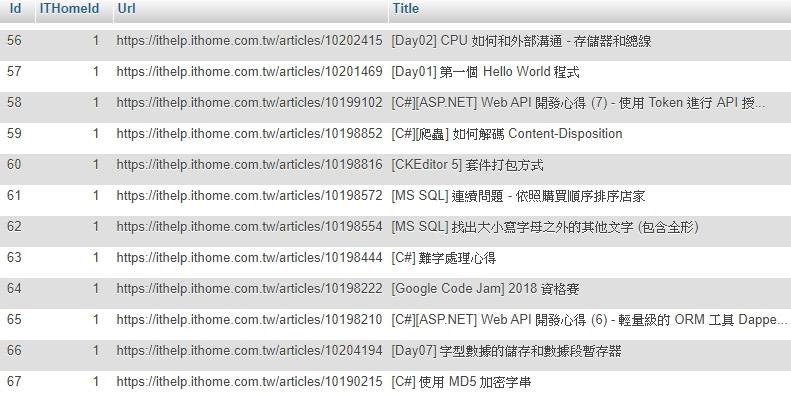
查看資料庫,資料正確有 67 筆。
不過順序怎麼是亂的,愣!!
算了不想查了 (╯‵□′)╯︵┴─┴
爬蟲完成,接下來繼續完成 Line Bot 部分 ~~~
Line Bot 功能如下:
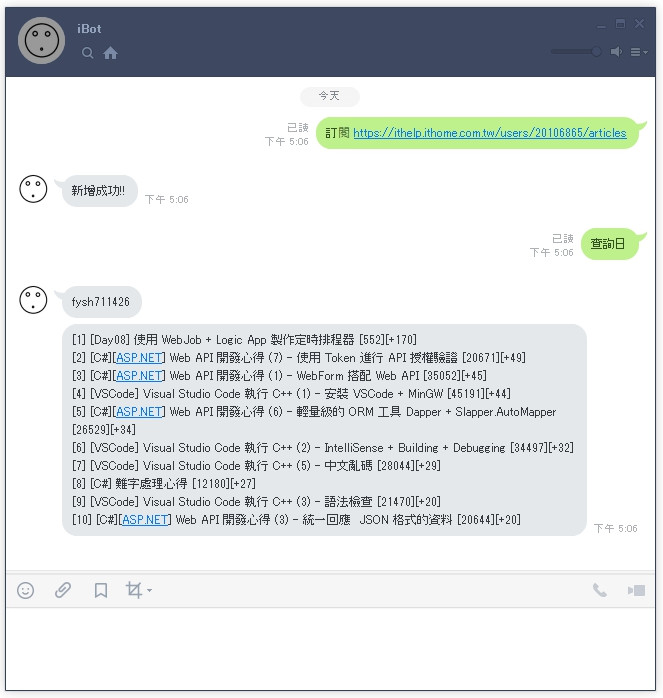
使用者可輸入 「訂閱 https: //xxxxx」 訂閱某人的文章。
訂閱後,使用者可輸入 「查詢日」、「查詢週」、「查詢月」 查詢文章排名。
※ 這邊會接續上上一篇的 LineBotApp.cs 繼續。
[Day07] 使用 EF Core 讀取 Azure 上的 MySQL 資料庫
1. 訂閱功能
程式會先檢查網址是否正確,接著處理 ITHomes 和 Subscribes 這兩張資料表,這邊就不細說,可以參考下方完整程式。
2. 查詢功能
以查詢月舉例,我先取得一個月內的所有瀏覽數,並按日期排序,接著用第一筆的數字減去最後一筆,這樣就可以得到一個月的增加數量。
不過總感覺哪裡怪怪的。 Σ(・ω・`|||)
如有更好的做法歡迎留言告知我。
//計算瀏覽數增加
var now = DateTime.Now;
var days = 0;
if (textMessage.Text == "查詢日")
days = 1;
if (textMessage.Text == "查詢週")
days = 7;
if (textMessage.Text == "查詢月")
days = 30;
//取得查詢天數內的瀏覽數
var articleViewCountList = await_db.ArticleViewCounts
.Include(it => it.ITHomeArticle)
.Where(it => it.ITHomeArticle.ITHomeId == subscribe.ITHomeId)
.Where(it =>
it.DateTime < now.Date.AddDays(1) &&
it.DateTime >= now.Date.AddDays(days * -1))
.ToListAsync();
//計算前十名
var topList = articleViewCountList
.GroupBy(it => it.ITHomeArticleId)
.Select(it =>
{
var query = it.OrderByDescending(itt => itt.DateTime).ToList();
var first = query.FirstOrDefault();
var last = query.LastOrDefault();
return new
{
inc = first == null || last == null
? 0 : first.ViewCount - last.ViewCount,
article = first?.ITHomeArticle,
count = first?.ViewCount
};
})
.Where(it => it.inc > 0)
.OrderByDescending(it => it.inc)
.Take(10)
.ToList();
//處理成文字
var txt = new StringBuilder();
for (var i = 0; i < topList.Count; i++)
{
var item = topList[i];
txt.Append($"[{i+1}] {item.article.Title} - [{item.count}][+{item.inc}]\n");
}
txt.Remove(txt.Length - 1, 1);
完整程式
public class LineBotApp : WebhookApplication
{
private readonly LineMessagingClient _messagingClient;
private readonly CoreDbContext _db;
public LineBotApp(LineMessagingClient lineMessagingClient, CoreDbContext db)
{
_messagingClient = lineMessagingClient;
_db = db;
}
protected override async Task OnMessageAsync(MessageEvent ev)
{
var result = null as List<ISendMessage>;
switch (ev.Message)
{
//文字訊息
case TextEventMessage textMessage:
{
//頻道Id
var channelId = ev.Source.Id;
//使用者Id
var userId = ev.Source.UserId;
//訂閱功能
{
var regex = new Regex(@"(?=^訂閱[\s]*)?(https:[\S]+)", RegexOptions.IgnoreCase);
var match = regex.Match(textMessage.Text);
if (match.Success)
{
var url = match.Value;
//檢查網址是否正確
try
{
using (var httpClient = new HttpClient())
{
var html = await httpClient.GetStringAsync(url);
var test = Regex.Match(html, @"(?<=class=""profile-main__title"")([^<]*)").Value;
if (!test.Contains("發文列表"))
{
throw new Exception();
}
}
}
catch
{
//回傳訊息
result = new List<ISendMessage>
{
new TextMessage("網址錯誤,需為 it 幫文章列表!!")
};
break;
}
//處理 ITHome
var iTHome = await _db.ITHomes
.Where(it => it.Url == url)
.FirstOrDefaultAsync();
if (iTHome == null)
{
//新增
iTHome = new ITHome
{
Url = $"{url}",
Name = "",
Account = ""
};
_db.ITHomes.Add(iTHome);
await _db.SaveChangesAsync();
}
//處理 Subscribe
var subscribe = await _db.Subscribes
.Where(it => it.UserId == userId)
.FirstOrDefaultAsync();
if (subscribe == null)
{
//新增
subscribe = new Subscribe
{
UserId = userId,
ITHomeId = iTHome.Id,
};
_db.Subscribes.Add(subscribe);
}
else
{
//更新
subscribe.ITHomeId = iTHome.Id;
}
await _db.SaveChangesAsync();
//回傳訊息
result = new List<ISendMessage>
{
new TextMessage("新增成功!!")
};
break;
}
}
//查詢功能
{
var regex = new Regex(@"^查詢日$|^查詢週$|^查詢月$", RegexOptions.IgnoreCase);
if (regex.IsMatch(textMessage.Text))
{
//取得訂閱資訊
var subscribe = await _db.Subscribes
.Where(it => it.UserId == userId)
.FirstOrDefaultAsync();
if (subscribe == null)
{
//回傳訊息
result = new List<ISendMessage>
{
new TextMessage("尚未訂閱!!")
};
break;
}
//取得 ITHome
var iTHome = await _db.ITHomes
.Where(it => it.Id == subscribe.ITHomeId)
.FirstOrDefaultAsync();
//計算瀏覽數增加
var now = DateTime.Now;
var days = 0;
if (textMessage.Text == "查詢日")
days = 1;
if (textMessage.Text == "查詢週")
days = 7;
if (textMessage.Text == "查詢月")
days = 30;
//取得查詢天數內的瀏覽數
var articleViewCountList = await _db.ArticleViewCounts
.Include(it => it.ITHomeArticle)
.Where(it => it.ITHomeArticle.ITHomeId == subscribe.ITHomeId)
.Where(it =>
it.DateTime < now.Date.AddDays(1) &&
it.DateTime >= now.Date.AddDays(days * -1))
.ToListAsync();
//計算前十名
var topList = articleViewCountList
.GroupBy(it => it.ITHomeArticleId)
.Select(it =>
{
var query = it.OrderByDescending(itt => itt.DateTime).ToList();
var first = query.FirstOrDefault();
var last = query.LastOrDefault();
return new
{
inc = first == null || last == null
? 0 : first.ViewCount - last.ViewCount,
article = first?.ITHomeArticle,
count = first?.ViewCount
};
})
.Where(it => it.inc > 0)
.OrderByDescending(it => it.inc)
.Take(10)
.ToList();
//處理成文字
var txt = new StringBuilder();
for (var i = 0; i < topList.Count; i++)
{
var item = topList[i];
txt.Append($"[{i+1}] {item.article.Title} [{item.count}][+{item.inc}]\n");
}
txt.Remove(txt.Length - 1, 1);
//回傳訊息
result = new List<ISendMessage>
{
new TextMessage(iTHome.Name),
new TextMessage(txt.ToString())
};
break;
}
}
}
break;
}
if (result != null)
await _messagingClient.ReplyMessageAsync(ev.ReplyToken, result);
}
}
終於完成了,這篇程式好多,從構思到完成花了好幾天的時間,完全當成一個小的 Side Project 在做。
爬蟲是個敏感的技術,大家平時使用要小心觸法
下列幾點是需要注意的事項
來源: 你的爬蟲會送你進監獄嗎?
下一篇要介紹 Line Bot 的 Flex Message 功能,後面幾篇都會和 Line Bot 相關,不然快變成 Azure 系列了 ~( ̄▽ ̄)~
今天就到這裡,感謝大家觀看。
本篇內容為教學用途,如有違規麻煩告知,我會修改或刪除文章
小心.NET HttpClient
[Web API] HttpClient Response 中文亂碼問題排除
[C#] 使用 HttpClient 上傳檔案至伺服器
.NET Core 中使用GB2312编码报错的问题
RegExp 應用: lookahead , lookbehind
[實用] 用 Regular Expression 做字串比對
