
哈囉,我們又見面了,昨天介紹了詢問 Youtuber 訂閱數的 LineBot 專案,今天我們來實作其中最重要的爬蟲功能。
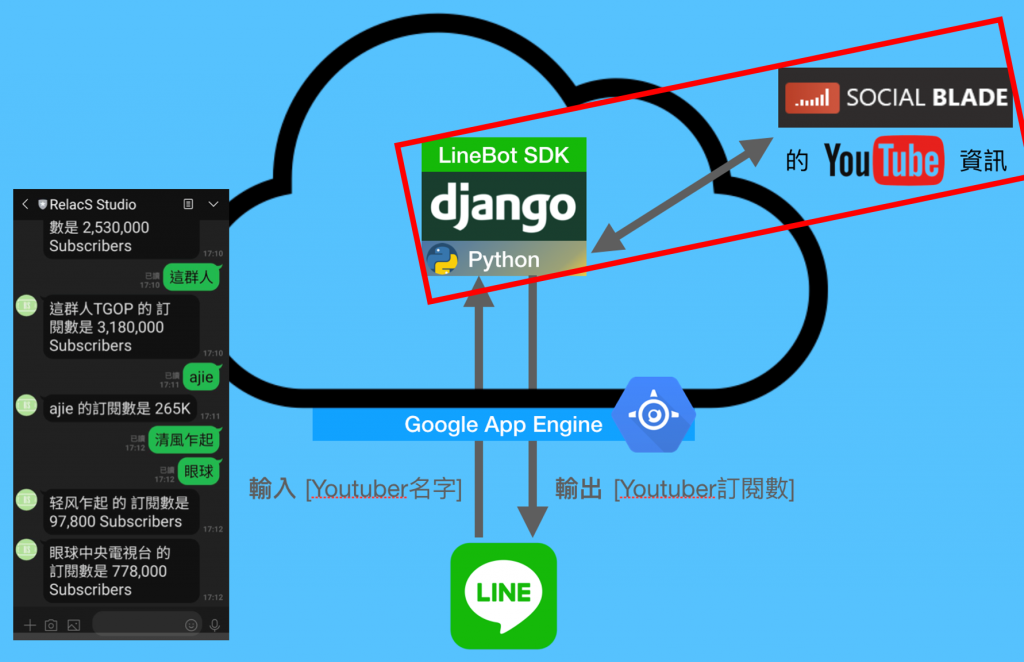
目標就是對 Social Blade 輸入 Youtuber 名稱的關鍵字,然後抓出 html 原始碼,並且擷出藏在 html 中的訂閱數。
今天的爬蟲內容,需要有點爬蟲基礎,才會知道我在寫什麼,推薦各位先照著 [Day 09] 實戰:用Requests&bs4 爬PTT (1) 做過一次,ptt 算是相對好爬的網站,因為它沒有複雜的 css 元件,也沒有爬蟲防禦
也就是透過 觀察目標網站的行為,來決定我們怎麼爬
Social Blade 的 Youtube 搜尋頁面: https://socialblade.com/youtube/
點擊右上角的搜尋框框,輸入你想尋找的 Youtuber 頻道名稱
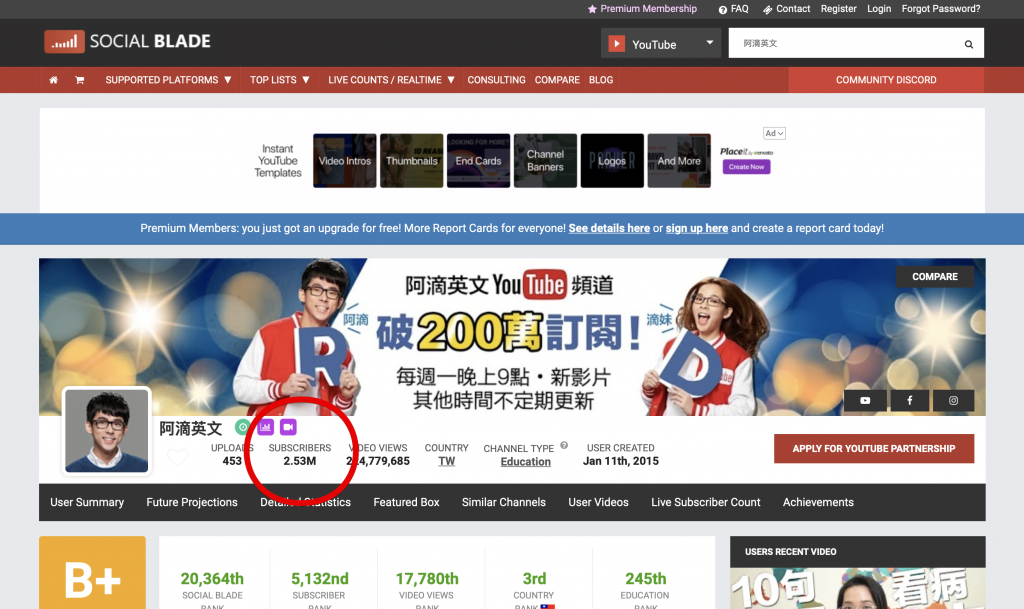
假設我們要想知道 阿滴英文 的頻道訂閱數,搜尋結果的網址長這樣: https://socialblade.com/youtube/channel/UCeo3JwE3HezUWFdVcehQk9Q,看起來很醜,但其實你把網址改成 https://socialblade.com/youtube/channel/阿滴英文,也是沒問題的,這網站的中英文編碼轉換做得很不錯 XD
打開 開發者工具(F12),切換到 Elements 的分頁,然後點選下圖的箭頭處小按鈕,就可以用指的,找到你想要的元件,所相對應的 html
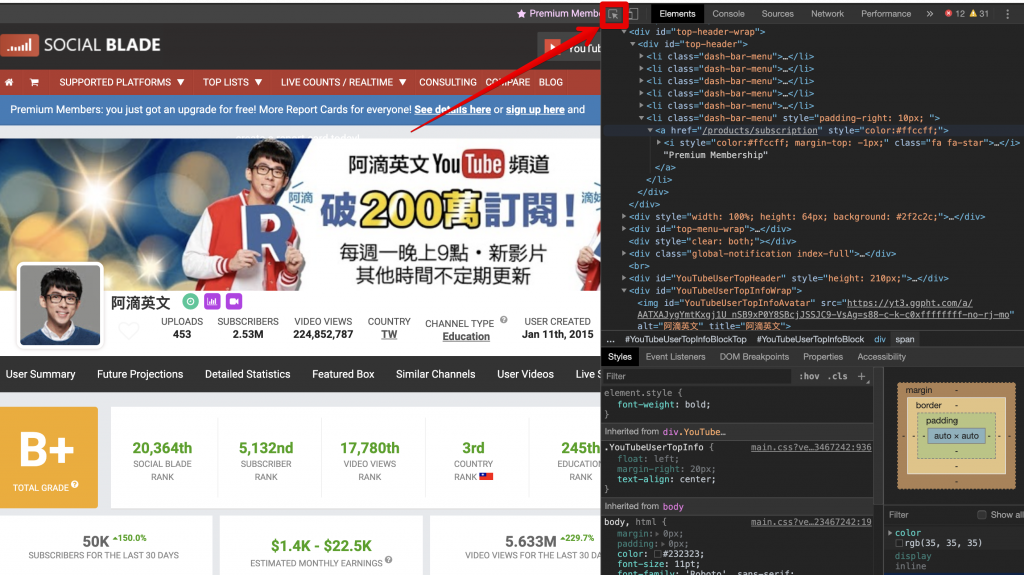
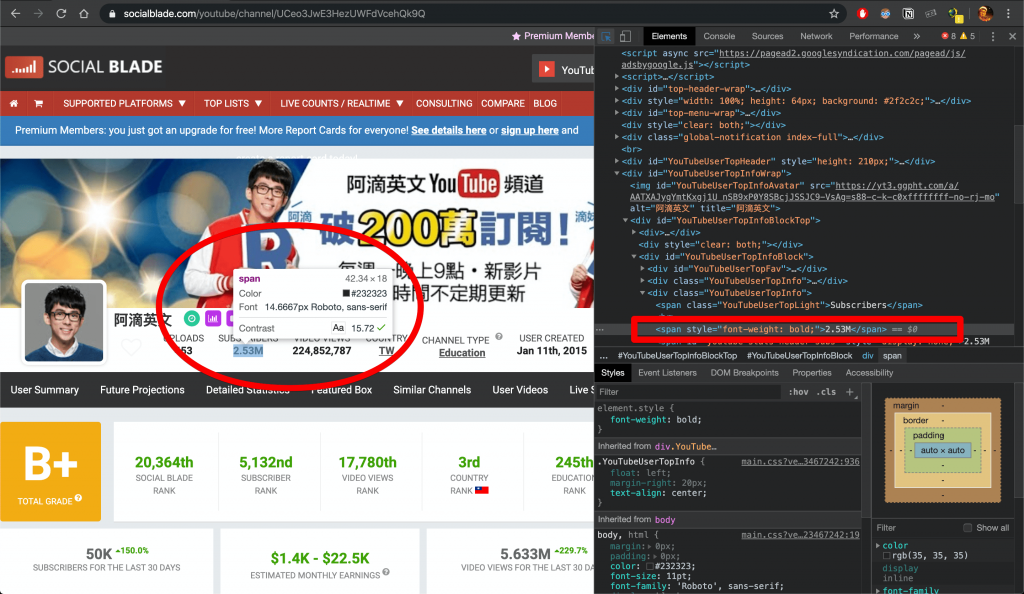
那麼我們現在知道,目標是 2.53M 這串數字,它藏在 div class=YouTubeUserTopInfo 標籤底下
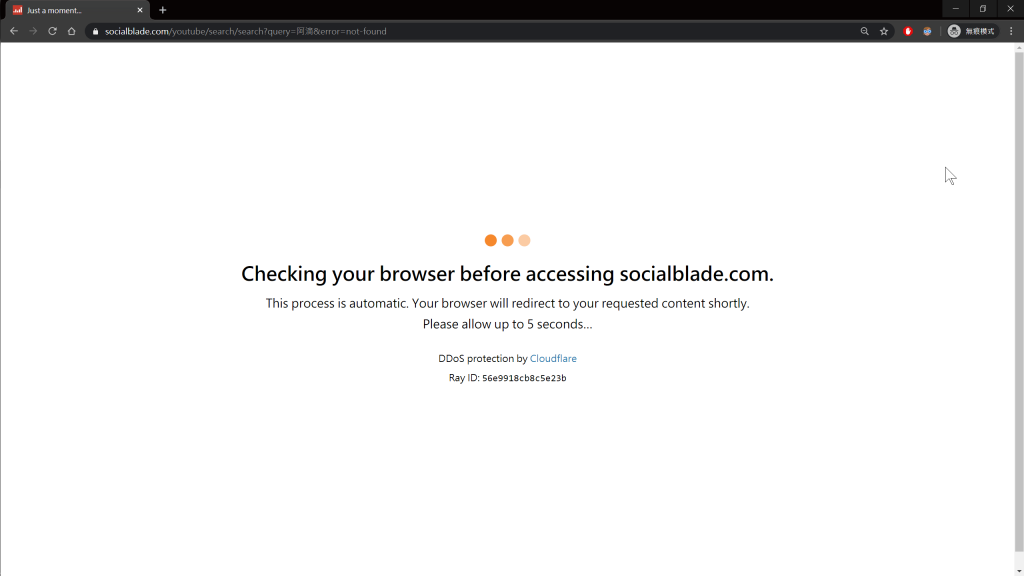
假如我搜尋 阿滴 兩個字,實際上阿滴的頻道是 阿滴英文、阿滴日常,Social Blade 在搜尋不到時,會出現一個頁面,下面有一句話叫
DDoS protection by Cloudflare
也就是防止 DDoS 攻擊 的防禦機制,是 CloudFlare 這家網路安全公司提供的服務,但爬蟲玩家就是想辦法繞過它的防禦機制,這樣對玩家才有挑戰性麻 XD
會透過一個轉址,轉到搜尋相關結果的頁面,然而我們想要搜尋的,就在搜尋相關結果的第一個 !
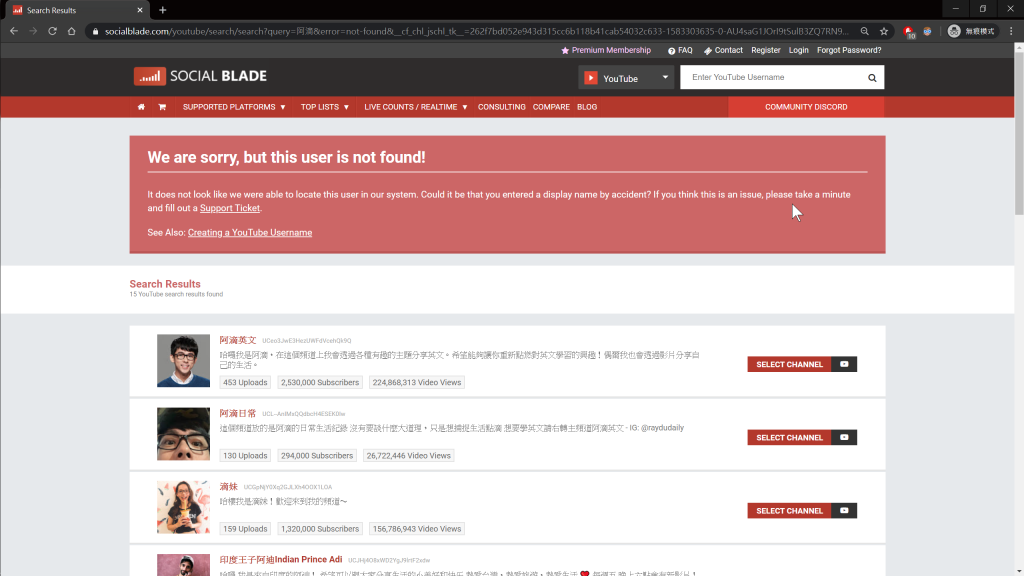
中間轉址的行為是透過植入 javascript,動態生成下一個頁面的 html 原始碼,所以只依靠 requests 的爬蟲就只會抓到一堆程式碼,這件事情其實就是,我在 Day22 寫 RESTful API 中提到的第六點: Code on Demand,這次的爬蟲案例完美詮釋了這一點。
(venv)$ pip install requests cloudscraper bs4
requests 目前是 2.23.0 版,用來模擬瀏覽器發出 request 的套件,可以自定 header agent,是爬蟲必備套件cloudscraper 目前是 1.2.24 版,用來繞過 cloudflare 對爬蟲的阻擋,因為爬蟲稍有不慎,就是一種網頁攻擊,通常大型網站都會有防禦爬蟲的機制,不管你是不是一個有良心的爬蟲 XD,BeautifulSoup,目前是 4.4.0 版本,用來對 html 擷取出我們想要的資訊from django.shortcuts import render
from bs4 import BeautifulSoup
import requests, time, cloudscraper
name = "阿滴英文"
# 目標網站 social blade,需先觀察送出搜尋關鍵字之後的網址變化
base_url = "https://socialblade.com/youtube/user/" + str(name)
# 告訴目標網站說「我是透過A作業系統的B瀏覽器C版本,來拜訪你的網站」
# 可從瀏覽器的開發者工具,裡面的 `Network` 分頁,
# 抓其中一個 request header 找出 `user-agent` 欄位
agent = {"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36'}
# 模擬瀏覽器送出 GET method request
# 回傳回來的 `r`,就是搜尋結果的 response
r = requests.get(base_url, headers=agent)
# 而 response 裡的 text 屬性
# 就是 response 後的 html 原始碼
print(r.text)
'''
輸出就像
<!DOCTYPE html>
<head>
...
</head>
</html>
'''
# 再以 BeautifulSoup 解析 html
soup = BeautifulSoup(r.text, 'html.parser')
# select() 是 css 的選擇器,
# 更多關於 select() 的用法
# 參考 https://www.crummy.com/software/BeautifulSoup/bs4/doc/#css-selectors
all_div = soup.select("div")
# 可以得到 html 內,所有的 div 標籤,裡面的內容
print(all_div)
'''
輸出就像
<div class="...">
<div class="..." id="...">
<div class=...
<span>...
...
'''
Cloudflare 的 javascript 轉址阻擋# 先找出轉址後的網址,可透過瀏覽器的開發者工具的 `Network` 分頁
base_url = "https://socialblade.com/youtube/search/search?query=" + str(name) + "&error=not-found"
# 這邊用 cloudscraper 取代 requests,這套件幫我們
new_response = cloudscraper.create_scraper().get(base_url)
# 得到繞過轉址後的 html
print(new_response.text)
網站防禦駭客的方式有百百種,聰明的駭客有千千萬萬個,攻擊和防禦的方法日新月異,就看遇到什麼情況,再去想辦法解決它,但起碼,我們目前知道了一種繞過 cloudflare 轉址的方法了~
crawler/views.py (完整爬蟲 code)
# -*- coding: utf-8 -*-
from django.shortcuts import render
from bs4 import BeautifulSoup
import requests, time, cloudscraper
def crawl_subscribes_of_youtuber(name):
try:
base_url = "https://socialblade.com/youtube/user/" + str(name)
agent = {"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36'}
# 發出 request 到 social blade 進行搜尋
# r.text 就是搜尋後的 html 原始程式碼
r = requests.get(base_url, headers=agent)
# 套用 BeautifulSoup 來截取對我們有用的資訊(訂閱數)
soup = BeautifulSoup(r.text, 'html.parser')
# 擷取資訊的規則,希望從所有的 div class=YouTubeUserTopInfo,
# 抓出裡面的 span 標籤
all = soup.select("div.YouTubeUserTopInfo span")
'''
以下是為了讓使用者有輸入的容錯機制,也就是我不用輸入完全
'''
# 如果抓不到東西,也就是搜尋不到這位 Youtuber
if len(all) <= 0:
# 換成失敗時的網址,這串網址是觀察 Social Blade 的轉址行為看到的
# 可以透過瀏覽器的開發者工具裡的 Network 分頁,去看看轉址會轉到哪
base_url = "https://socialblade.com/youtube/search/search?query=" + str(name) + "&error=not-found"
# 這邊取代 requests 套件,改用 cloudscraper 來抓 html 原始碼
# 因為 social blade 會透過轉址,來阻擋爬蟲,
# 而 cloudscraper 能繞過 cloudflare 的轉址行為,抓到轉址後的 html
new_body = cloudscraper.create_scraper().get(base_url).text
# 得到 html 後,依舊可以使用 BeautifulSoup 來擷取資訊
soup = BeautifulSoup(new_body, 'html.parser')
# 抓出所有 div 以下的 h2 裡面的 a 標籤
channel_all = soup.select("div h2 a")
if len(channel_all) <= 0:
return "我找不到這位 Youtuber QQ"
else:
# 抓出所有 div 以下的 p 裡面的 span 標籤
subscribe_all = soup.select("div p span")
# 不要學我不檢查,就直接讀取陣列的元素QQ
return channel_all[0].text + " 的 訂閱數是 " + subscribe_all[1].text
else:
# 不要學我不檢查,就直接讀取陣列的元素QQ
return name + " 的訂閱數是 " + all[4].text
except:
return "伺服器出現問題QQ,可以幫我聯絡開發者嗎~~"
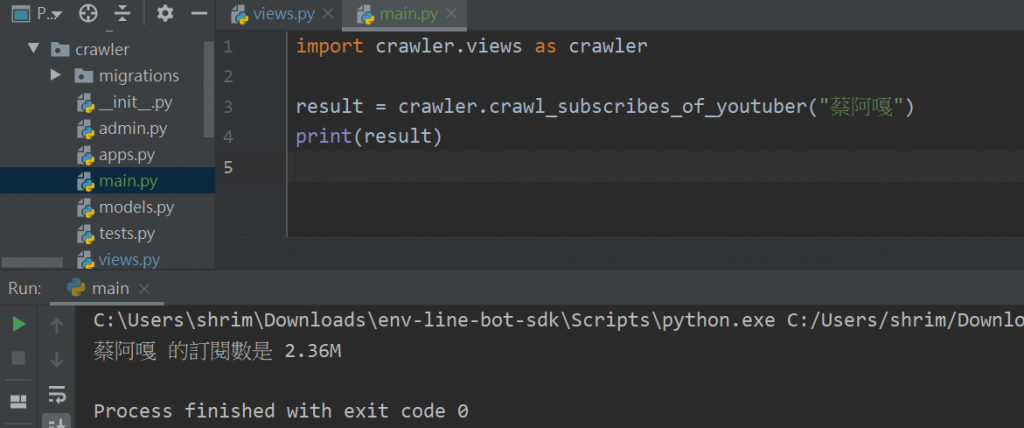
另外寫一個 main.py,放在和 crawler/views.py 的同資料夾下,單純來測試這支爬蟲即可 (不需要執行 django)
import crawler.views as crawler
result = crawler.crawl_subscribes_of_youtuber("蔡阿嘎")
print(result)
輸出為
今天這篇文不是詳細教學,無法照著做就做出來,也有許多基本的概念無法穿插在文章內解釋,不然會讓整篇文章架構很雜亂,如果大家有需要詳細的步驟教學,再留言告訴我。
你可能會想問我,為什麼不直接爬 Youtube 就好了 ? 其實 Youtube 有開出 Youtube Data API,我記得需要一些驗證,有點小麻煩,所以繞了點路,就改爬相關的網站~
今天我們就先做到這裡,這篇是爬蟲篇,下次我們再把爬蟲結合 LineBot SDK,讓我們直接對 Line 機器人發問,就能得到訂閱數吧~
我是 RS,這是我的 不做怎麼知道系列 文章,我們 明天見。
 Sam
Sam
