
均一教育平台身為台灣目前規模最大的線上教育平台之一,團隊打拼的方向一是建構優質而免費的線上學校,二是透過功能開發、師資培訓,協助老師、家長能夠更省時省力地陪伴孩子「用自己的步調學習」。
當 data team 發現,老師在面對同一班學生學習速度的差異時,總是分身乏術的問題,就開始嘗試透過科技打造「自動推薦機制」,想要成為老師的智慧小助手!那麼,data team 到底怎麼應用技術完成這個機制呢?AI 工程師柏任在這篇文章中分享了他們的思考和技術應用。
在教室裡,每一個學生學習的起始點都不一樣,因此就算老師上課的進度都一樣,每個學生遇到的困難可能不盡相同,學得比較快的學生已經學完老師指定的內容,學得比較慢的學生可能還卡在前面的學習中。
老師在面對這樣的狀況,總是顯得分身乏術,需要讓學得比較快的學生可以繼續學習什麼或者讓他幫助其他同學,也要去協助遇到困難的學生。但比起學習比較快的學生,遇到困難的學生更需要即時的協助。
因此均一想成為老師的小幫手,分擔老師的負擔,我們希望從「當學生學習時遇到困難時,均一該怎麼協助他」開始嘗試。
要有好的人工智慧,向專家取經是必經之路,好的專家知識會是人工智慧發展的基石。於是我們到教學現場觀察、訪談現場的老師面對這樣的狀況,是怎麼協助學生的呢?
我們發現,老師看到學生卡住的問題時,會從過往的教學經驗以及對於教材的了解,找出跟這個題目有關的相關知識。
接著,老師會順著題目的解題步驟,一個步驟一個步驟的跟學生解釋,如果有不懂的,馬上針對步驟進行教學。
於是,我們開始思考如何將這個協助過程重現在均一?
如果要把這個協助過程重現在均一的話,這其中最關鍵的是,我們要知道這個題目有哪些步驟?每個步驟牽涉到哪些觀念?
均一教育平台上的每個題目都有提示,而這些提示都是我們的內容製作者用他們的專家知識製作而成的解題步驟,這就是我們的最佳學習對象。
所以,問題就變成了:「我們怎麼將提示對照出學習概念?」
也就是幫提示上標籤?經過討論後,我們決定嘗試自然語言處理,把提示文字轉換成向量,再將這些向量對照回概念。

(將題目拆解成數學概念示意圖)
首先,我們使用 jieba 這個套件將提示文字做斷詞,並用 big5 語料庫,加上常見的停止詞(Stop Words)。
但是初步斷詞的結果讓人不太滿意,例如:「真分數」會被斷成「真/分數」、「通分成分母一樣」會被斷成「通分/成分/母/一樣」或者「通/分成/分母/一樣」。
這樣無法把重要的數學概念包含在內,因此我們需要調整斷詞的權重。
我們需要增加數學詞彙的權重,數學詞彙的來源,就是均一教育平台上的單元名稱,因為通常單元名稱會非常清楚的把這個單元要學會的概念寫出來,例如:認識直角三角形、真分數與假分數、一位數的除法等等。
(均一「帶分數與假分數」單元頁面)
因此我們把這些數學詞彙用一些連接詞(例如:的、與等)分隔,去除一些常用的概念動詞(例如:認識、了解、計算等),就可以得到重要的數學概念列表。
利用這個重要的數學概念列表,就可以讓斷詞結果更精準,也更能保留這句話想傳遞的重要資訊。
(找出數學詞彙示意圖)
接下來,我們遇到的下一個問題是數學式,因為數學題目裡,有很多數學式,而我們是透過 LaTeX 來撰寫數學公式。
造成題目文字會長這樣,有許多重複且沒有意義的符號例如:「 \、{、}、底線」。
{'content':分子 $5$ 和分母 $60$ 有最大公因數 $5$ 所以可以約分:\n\n$=\\dfrac{\\cancel{5}^1}{\\cancel{60}^12}$\n\n$=\\color{fuchsia}{\\drafc{1}{12}}$\n\n答案是$\\color{fuchsia}{\\drafc{1}{12}}$公尺','images':{},'widgets':{}}
有些符號我們可以透過增加停止詞來移除,但有些數學式我們需要經過一些預處理。例如:$12 \div 4 = $ 這個數學式,我們不在意是什麼數字除以什麼數字,只在意他是二位數除以一位數。
又例如分數在 LaTeX 語法下有兩種:\dfrac{1}{4}」和\frac{1}{4},除了含義上是一樣的以外,同樣我們並不在意他是幾分之幾,我們在意的是他是真分數、假分數還是帶分數,因此我們需要把他轉換成更抽象一點的數學概念。
還好 LaTeX 語法寫出來的數學式都有共通的規則,因此我們利用 Regular Expression 將這些數學式做轉換,處理後就如下圖所示,看起來就更清楚好懂一些了!
分子/一位數/分母/二位數/最大公因數/一位數/約分/等於/frac/cancel/一位數/一位數/cancel/二位數/二位數/等於/真分數/答案/真分數/公尺
在這邊我們用的是 gensim 套件,在詞向量的訓練上我們的詞庫是用 wikipedia 的公開資料集,但,很快的,我們又遇到問題了⋯⋯
wikipedia 擁有很大量的詞資料庫,但是我們看一下「垂直」的相關詞彙,就會出現下列結果:「正交、投影」等等較為專業的數學詞彙。
就數學的概念上這的確是相關的,但是我們現在的題庫是國小的題庫,這些詞彙的關係太過專業,就像大學教授所教的數學課程,無法清楚表示國小學習內容詞彙的關聯一樣,因此我們想試試看用別的資料集。
剛開始,我們想到的就是我們自己的資料庫,均一有這麼多題目、題目又這麼接地氣,用我們的題目應該也不錯!
結果⋯⋯我們的資料量還是太少,不足以訓練出一個足夠好的模型。於是,我們就想,那我們來讓大學教授教國小數學吧!
所以我們先用 wikipedia 訓練出來的模型當基底,再拿均一的題庫做 finetune,想不到結果還不錯!代表只要提供對的資料,大學教授也可以教國小數學的。
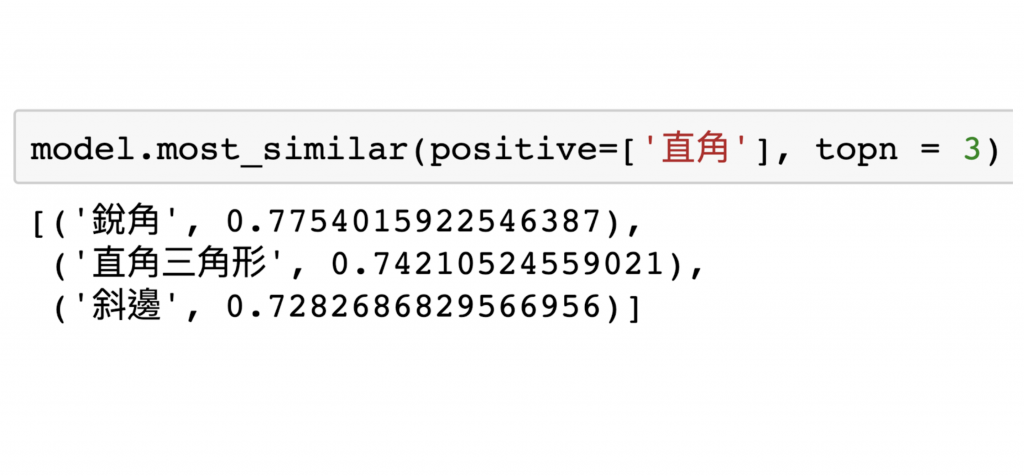
(經過均一題目 finetune 後的結果)
可以把詞轉換成詞向量後,接著就要準備組合成代表這個提示的向量,這個組合方式有很多種。
例如:把所有提示內的詞向量平均、用 tf-idf 加權平均、直接組合等等。因為在數學概念中,「二位數除以一位數」跟「一位數除以二位數」是完全不同的概念,所以順序是否可以被很好的保留下來是非常重要的。
因此我們選擇用直接組合的方式:統計提示發現將近 70% 提示的長度都在 30 個字以內,所以用最簡單的方式,只保留每個提示的前 30 個,其餘都先捨棄,不足的就補結尾向量。
為了讓這 30 個字有最大效率的應用,我們將詞頻率出現太低的過濾掉,這些頻率太低的可能是名字、地名等題目的情境包裝。
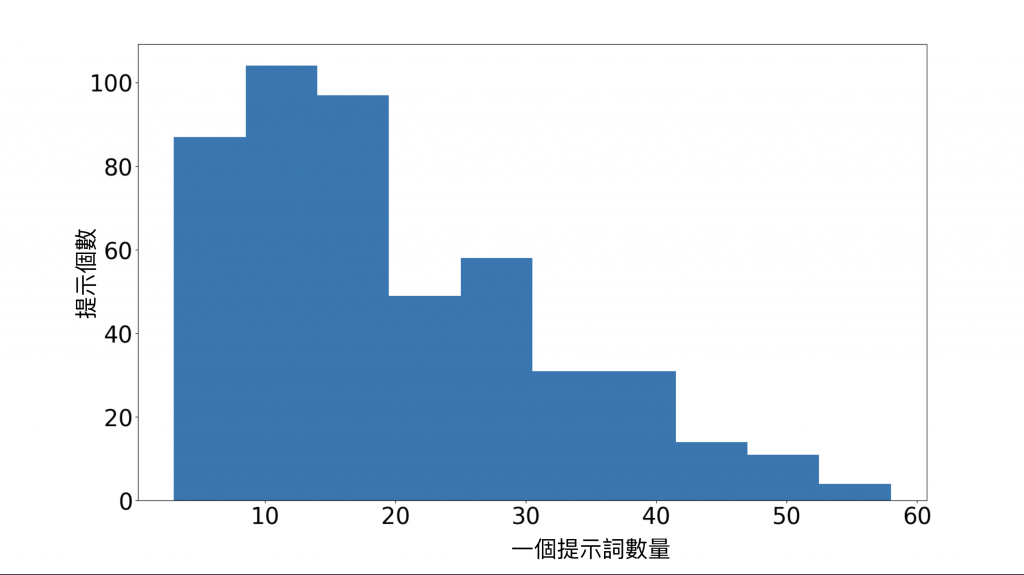
(提示個數與一個提示詞數量分布長條圖)
要進一步優化之前,我們先測試一下目前的模型效能到什麼程度,驗證這個構想在技術上的可行性。
我們使用 cosine 相似度來計算向量的相似度,發現這樣組合而成的向量對於找類題的處理還不錯!代表了向量目前的資訊量一定程度足夠代表原本的題目,因此我們就可以往下一步嘗試。

(左圖是原題,右圖是找出來的類題,cosine 相似度 0.7562)
接下來,就要看技術上是否可以做到上概念標籤。
因為我們是 multi-label 的分類問題,處理 multi-label 分類問題的方法也很多,例如:每個標籤各別訓練分類器、只要上的標籤不同就當成不同的類別來訓練、加入標籤之間的關係訓練等等。
初期驗證,我們先用 One Vs Rest Classifier 這個比較簡單的方式,也就是為每一個標籤訓練各自的分類器,有該標籤的 groundtruth 就是 1,沒有該標籤 groundtruth 就是 0。
測試一個單元的結果,並用 Exact Match Rate 當成指標,結果標籤全對的比率高達 78%。從上面這兩個測試,我們已經滿有信心技術上應該是可以做到的。
模型永遠都有優化空間,但是我們的想法是否行得通?對使用者有沒有用呢?這我們就需要上線測試才能得到解答。
我們選擇幾個單元上標籤,並上線測試,觀察接受推薦的學習者看了推薦的影片後,是否可以幫助他解決困難?
經過一個月的測試,我們觀察到,接受推薦的人,下一題答對率上升了 11%(從 54%提升到 65%)。但是對於正在學習的學生來說,似乎不想被打斷,接受推薦的比例不高,只有約 13%。
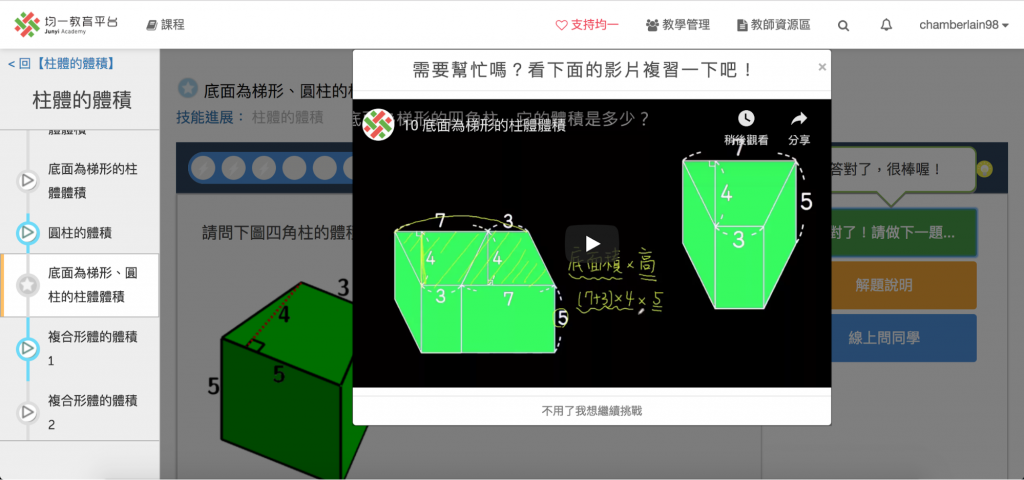
(推薦功能測試畫面)
那下一步呢?雖然從市場面來看接受推薦的比例不高,但是算是有效果的。
因此,接下來有兩個方向:
我們的猜測是,學生遇到困難其實會想要自己再努力試試看,只有在真的覺得沒辦法突破,才會尋求協助,例如:問老師、同學等。
學生心態是否真如我們所猜測的?這就是我們要去研究的地方。
期待未來能透過這兩個方向的改善,更能貼近到學生的需求去提供他們需要的協助。
你對技術充滿熱情,想要跟柏任一起,用 code 協助學生度過難關嗎?均一正在招募軟體工程師、資深前端工程師,馬上打開招募頁面了解詳情、投遞履歷!
作者|陳柏任(均一平台教育基金會軟體工程師)
編輯|陳又慈(均一平台教育基金會實習生)
 junyiacademy_小均
junyiacademy_小均
