此文是《10周入門資料分析》系列第11篇
想瞭解學習路線,可以先閱讀“ 學習計畫 | 10周入門資料分析 ”
講完概率分佈,再來講講統計學的最後一個知識點 — — 假設檢驗。
假設檢驗是數理統計學中根據一定假設條件由樣本推斷總體的一種方法。事先對總體參數或分佈形式作出某種假設,然後利用樣本資訊來判斷原假設是否成立,採用邏輯上的反證法,依據統計上的小概率原理。
為了更好的解釋,這裡舉個例子。
假設我有一袋豆子,袋子裡有紅豆,也有黑豆,我想知道紅豆和黑豆是不是一樣多。若是一個個去看怕是要瘋了。於是偷個懶,從袋子裡拿了一把豆子,看看這把紅豆多還是黑豆多。用這把豆子作為樣本,去推斷這袋豆子。既然是用樣本推斷總體,就有抽樣誤差的可能性。不管袋子裡紅豆多還是黑豆多,這一把不一定能真實反映這袋豆子,那怎麼辦呢?這就要用到假設檢驗了。
說假設檢驗之前,先要知道小概率事件。統計大牛覺得如果一件事情發生的可能性小於0.05,就可以定義為小概率事件了,也就是說,在一次研究中該事件發生的可能性很小,如果只進行一次研究,可以視為不會發生。
回到豆子的話題。現在是想透過樣本(一把豆子)去推斷總體(一袋豆子)。先做一個假設,一般是我們心裡特別不想承認的那一種可能,也稱無效假設。和無效假設對立的是備擇假設,是無效假設的對立面。
無效假設:袋子裡紅豆和黑豆是一樣多的,如果觀察到紅豆黑豆不一樣多完全是由抽樣造成的。備擇假設:袋子裡紅豆和黑豆的確不一樣多。
假定袋子裡有100個豆子,50個紅豆,50個黑豆。拿的這把豆子有3個紅豆,7個黑豆。在無效假設成立的前提下,也就是說紅豆黑
這告訴我們,在紅豆和黑豆一樣多的假設下,拿到3個紅豆7個黑豆的可能性為0.11,是很常見的,說明所做的假設是可以成立的,還沒有理由能拒絕無效假設。
假定袋子裡有100個豆子,50個紅豆,50個黑豆。拿的這把豆子有1個紅豆,9個黑豆。
在無效假設成立的前提下,能拿到1個紅豆、9個黑豆的概率為:
這告訴我們,在紅豆和黑豆一樣多的假設下,拿到1個紅豆9個黑豆的可能性為0.007<0.05,為小概率事件,在一次研究中是不應該發生的,而現在發生了,可能是所做的假設有問題,有理由拒絕無效假設。
簡言之,假設檢驗的核心思想是小概率反證法,在假設的前提下,估算某事件發生的可能性,如果該事件是小概率事件,在一次研究中本來是不可能發生的,現在發生了,這時候就可以推翻之前的假設,接受備擇假設。如果該事件不是小概率事件,我們就找不到理由來推翻之前的假設,實際中可引申為接受所做的無效假設。
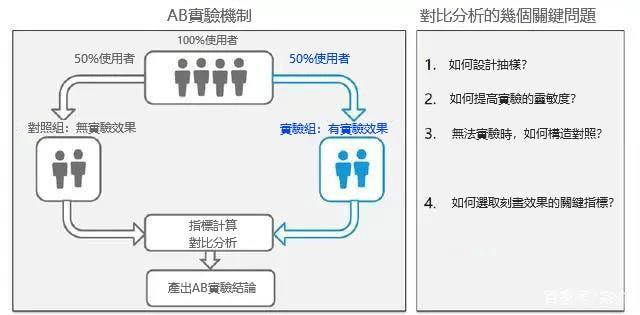
互聯網運營分析師與產品經理都很熟悉的方法:ABtest。適用方面:往往新版本或者新功能上線之前,需要驗證新需求的是否有正收益,傳統模式往往就是新版本發佈,然後觀察留存率、跳轉率等核心指標,如果觀察表現期內,流量正增長,那麼則認可該版本,如果效果回饋不佳,則快速回滾舊版本。但在移動互聯網時代,千人千面講究用戶差異化的時代,產品經理在面對海量使用者流量,就可以實現ABtest,過程:抽樣小規模流量,進行灰度測試,檢驗新需求是否有正收益,如果觀察週期校驗效果顯著,則大規模上線測試反覆運算,直至全流量覆蓋。
ABtest其本質核心就是假設檢驗,但是實際操作中,這裡有幾個關鍵:
1、如何設計抽樣,儘量實現對照實驗兩邊公平;
2、如何提高靈敏度,即效果收益穩定性,多組交叉驗證流量平衡;
3、對照組設定,避免引入幹擾因素;
4、收益評價指標,正收益、用戶體驗,當然我們T檢驗也要通過。
實際應用中,我們會發現產品經理的腦洞實在太大,需求太多,能否實現少設置測試流量批次?能否縮短收益評價週期?這裡就牽涉到上面第一個問題:如何抽樣?抽樣才是ABtest關鍵,根本原則是希望控制對照組兩邊客群一樣,儘量公平。抽樣方法也很多:簡單抽樣、分層抽樣、正交抽樣等等。這裡為何提到一個正交抽樣呢?正交抽樣滿足一次測試,多組對照的抽樣方法。關於細節,大家可以關注並評論,後面我給相應解答。
實際上用戶增長運營是件很有挑戰工作,單純資料流程量ABtest是用戶體驗辨別方法,如果從運營監控角度去分析,也需要從不同群組去分析客群增長模型,學會從業務中抓取核心關鍵公式或者模型,然後細化至各個維度,交叉對比,隱藏冰山下問題。
假設檢驗常用的方法有u — 檢驗法、t檢驗法、χ2檢驗法(卡方檢驗)、F — 檢驗法,秩和檢驗等。以t-假設檢驗舉例。
某藥廠研發了一種能夠降低血壓的新藥,現在為了瞭解該藥的療效,隨機抽取了15名高血壓患者,並得到他麼在使用該藥治療前後的舒張壓資料,如下圖所示,現在需要判斷:該藥是否有效?如果有效,是否能夠讓高血壓患者的舒張壓平均降低6.5mmHg?
根據上面的資料,我們可以使用Excel中的假設檢驗方法來判斷(以前我用手算過,好累呀,有了Excel等工具,很簡單方便,省時省力)。分析工具中的假設檢驗方法有多種,使用不同的方法,觀察值在檢驗前後的關係就不同,所以需要先選擇合適的方案。
由於樣本量較小,且樣本值中的觀察值存在治療前後的配對關係,所以可先使用“t-檢驗:平均值的成對二樣本分析”方法判斷該藥的有效性,我們首先假設該藥無效(一般先否定,然後計算檢驗否定原假設(如果正確的話)),然後進行假設檢驗。
第1步:選擇分析工具(Excel老朋友了)。“資料分析” — — “分析工具” — — “t-檢驗:平均值的成對二樣本分析”,確定即可。如下圖所示:
第2步:設定相關參數。在“t-檢驗:平均值的成對二樣本分析”對話方塊中,設定“輸入”組中“變數1的區域”為“$B$2:$B$17”,“變數2的區域”為“$C$2:$C$17”,選擇“標誌”核取方塊,設置“α”值為“0.05”,在“輸出選項”下按一下“輸出區域”,設定為“$E$2”,最後確定。如下圖所示:
第3步:設定假設平均差。重複上一步驟,其他參數不變,這次設置“假設平均差”為“6.5”,“輸出區域”為“$I$2”。這一步,“假設平均差”為期望中的樣本均值的差值,如果該值設為0,即假設樣本均值相同。
第4步:顯示分析結果。做完之後,我們就可以看到t-檢驗的結果:H列左側為第2步中檢驗該藥是否有效的資料結果,H列右側為第3步中檢驗該藥是否能讓舒張壓降低6.5mmHg的檢驗結果。如下圖所示:
上面的案例中,由於沒有充分的理由判斷該藥治療後的總體均數會大於或小於治療前的舒張壓均值,所以在檢驗過程中,前面的t-檢驗我們採用的是雙側檢驗。
從分析結果看到:H列左側的檢驗結果中,tStat=4.211,P雙尾=0.00087,t雙尾臨界=2.145,當t雙尾臨界時,假設成立,而這個案例中,檢驗結果tStat>t雙尾臨界,說明該結果拒絕原假設,也就是說該藥有效,此外,我們還能看到P雙尾=0.00087<α=0.05,這一比較結果也說明該結果拒絕原假設,同樣說明該藥有效。
由於已經確定該藥有效,那麼再判斷該藥能否將舒張壓平均值降低6.5mmHg,所以,後面的t-檢驗採用的是單側檢驗,這裡我們設置了假設平均差,上圖中紅框內,檢驗結果tStat=0.205<t單尾臨界=1.761,說明該假設成立,即該藥能夠讓高血壓患者的舒張壓平均降低6.5mmhg。結果p單尾=0.42>α=0.05也說明瞭該假設成立。</t單尾臨界=1.761,說明該假設成立,即該藥能夠讓高血壓患者的舒張壓平均降低6.5mmhg。結果p單尾=0.42>
今天學習一下Excel中如何進行t-檢驗,資料分析更進一步。
到這裡統計學部分就講完了。
我是「數據分析那些事」。常年分享資料分析乾貨,不定期分享好用的職場技能工具。
別忘記追蹤我的臉書,要常和小編互動喲~
 groots
groots

 iThome鐵人賽
iThome鐵人賽
{kind=link}
{kind=link}