本偏示範了如何將Pipeline與TransformedTargetRegressor結合,前者負責處理輸入特徵的縮放;後者針對目標輸出作縮放。若有更進一步需求,建議可以建立兩個Pipeline(代碼如下)或者詳讀TransformedTargetRegressor手冊
# (修正2)快捷:利用2*Pipeline減化過程,需要匯出2個模型
# 輸出
model41 = Pipeline([('scaler', StandardScaler())])
model41.fit(target)
# 輸入
model42 = Pipeline([('scaler', StandardScaler()),
('model', LinearRegression())])
model42.fit(feature_set, model41.fit_transform(target))
std = np.std(model41.inverse_transform(model42.predict(feature_set)))
print(std)
print(model42.steps[1][1].coef_, '\n')
#------------------------------------------------------------------------------
最近要把訓練完畢的模型供其他同事使用,早期方法是用查表法進行數據處理,但隨著方法的堆疊,查表法已經肥胖到一個不忍直視的地步了。
每次都會輸入16個訊號,根據規則表中不同的設定參數對每一個訊號作相應處理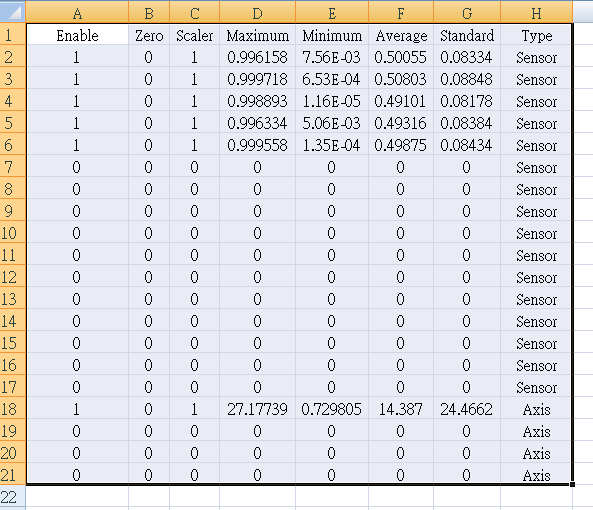
然後我想到前陣子在特徵工程不再難這本書中看到Pipeline,由於Pipeline是將重複性質高的工作轉為自動化(簡單來講就是省略了fit、fit_transform、transform、inverse_transform),因此我嘗試利用它來取代規則表大部分的功能。
但是在測試Pipeline過程中我發現目標沒有辦法被縮放,而網路上的Pipeline教學幾乎都是關於分類問題(目標不需要縮放),但終於讓我在[1]找到解法,感謝他!!!
匯入相關函式庫
# 匯入庫
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.compose import TransformedTargetRegressor
import matplotlib.pyplot as plt
np.random.seed(42)
建立測試數據
# 建立測試數據
# behchmark參考自https://xinzhe.blog.csdn.net/article/details/85036849
size = 750
feature_set = np.random.uniform(0, 1, (size, 5))
target = 10 * np.sin(np.pi*feature_set[:,0]*feature_set[:,1]) + \
20*(feature_set[:,2] - .5)**2 + \
10*feature_set[:,3] + \
5*feature_set[:,4]
feature_set = pd.DataFrame(feature_set)
target = pd.DataFrame(target.reshape(-1, 1))
# 一般方法:建立兩個scaler,一個model。需要匯出2+1個模型
# 預測輸出標準差 [ 4.24940990558225 ]
# 模型系數[ 0.39987264 0.42860665 -0.04726804 0.55697928 0.31174619 ]
scaler_x, scaler_y = StandardScaler(), StandardScaler()
model1 = LinearRegression()
X, y = scaler_x.fit_transform(feature_set), scaler_y.fit_transform(target)
model1.fit(X, y)
std = np.std(scaler_y.inverse_transform(model1.predict(X)))
print(std)
print(model1.coef_, '\n')
# ------------------------------------------------------------------------------
# 快捷:利用Pipeline減化過程,需要匯出1個模型
# 預測輸出標準差 [ 4.249409905582251 ]
# 模型系數[ 1.94451238 2.08424096 -0.22985641 2.70849516 1.51596848 ]
model2 = Pipeline([('scaler', StandardScaler()),
('model', LinearRegression())])
model2.fit(feature_set, target)
std = np.std(model2.predict(feature_set))
print(std)
print(model2.steps[1][1].coef_, '\n')
先檢查一下這兩個線性回歸模型的係數,很明顯兩者差異甚大,看來式在作數據縮放時出了問題。
model1的係數為[ 0.39987264 0.42860665 -0.04726804 0.55697928 0.31174619 ]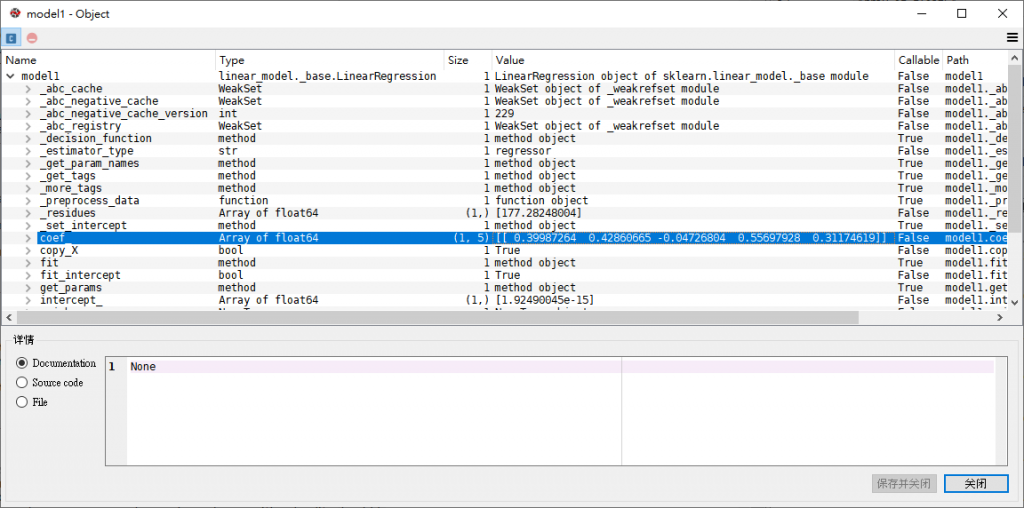
model2的係數為[ 1.94451238 2.08424096 -0.22985641 2.70849516 1.51596848 ]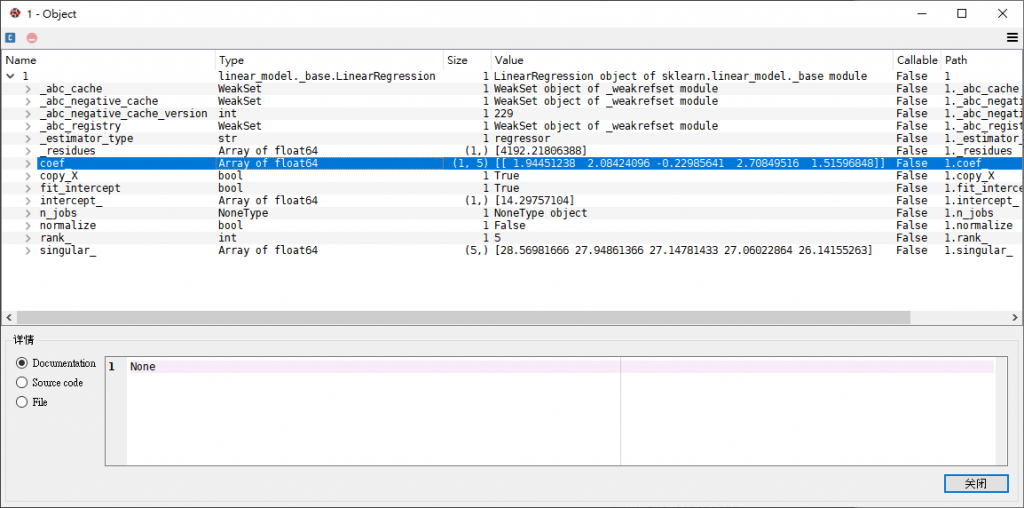
確認一下這兩個數據縮放的最大值最小值,發現case2只對輸入特徵進行縮放,所以兩者回歸模型的係數,導致預測值也有所不同,但差異不大。
model1的scaler1和scaler2參數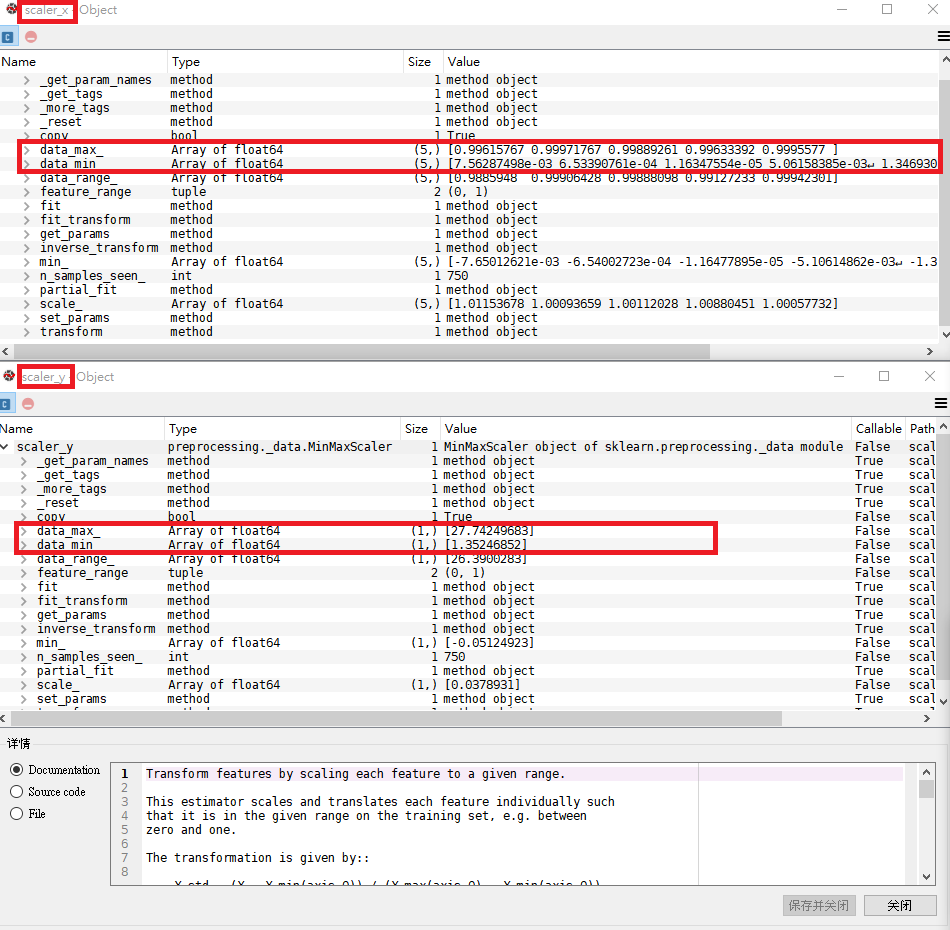
model2的Pipeline只有一個縮放器,對應model1的scaler_x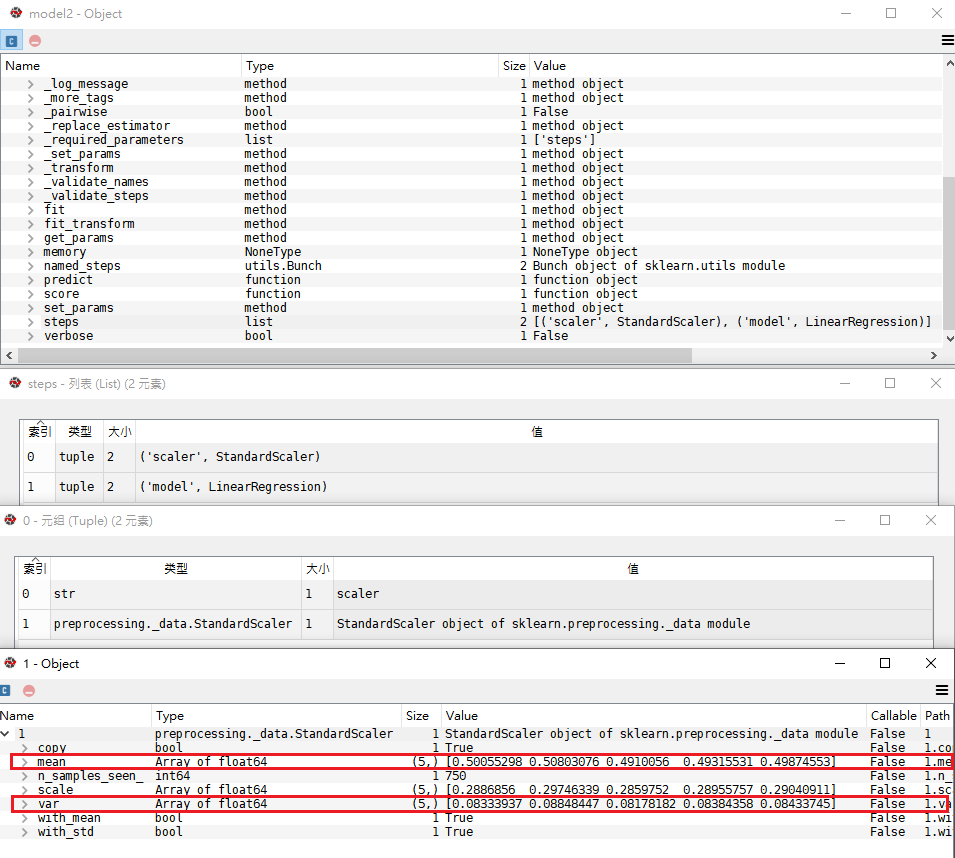
既然知道問題了,基於Pipeline為框架的限制下,如何讓目標也進行縮放呢?
# (修正)快捷:利用Pipeline將輸入處理自動化;TransformedTargetRegressor轉換目標,需要匯出1個模型
# 預測輸出標準差 [ 4.24940990558225 ]
# 模型系數 [ 0.39987264 0.42860665 -0.04726804 0.55697928 0.31174619 ]
pipeline = Pipeline(steps=[('normalize', StandardScaler()),
('model', LinearRegression())])
model3 = TransformedTargetRegressor(regressor=pipeline, transformer=StandardScaler())
model3.fit(feature_set, target)
std = np.std(model3.predict(feature_set))
print(std)
print(model3.regressor_[1].coef_, '\n')
#------------------------------------------------------------------------------
model3的係數,與model1相符合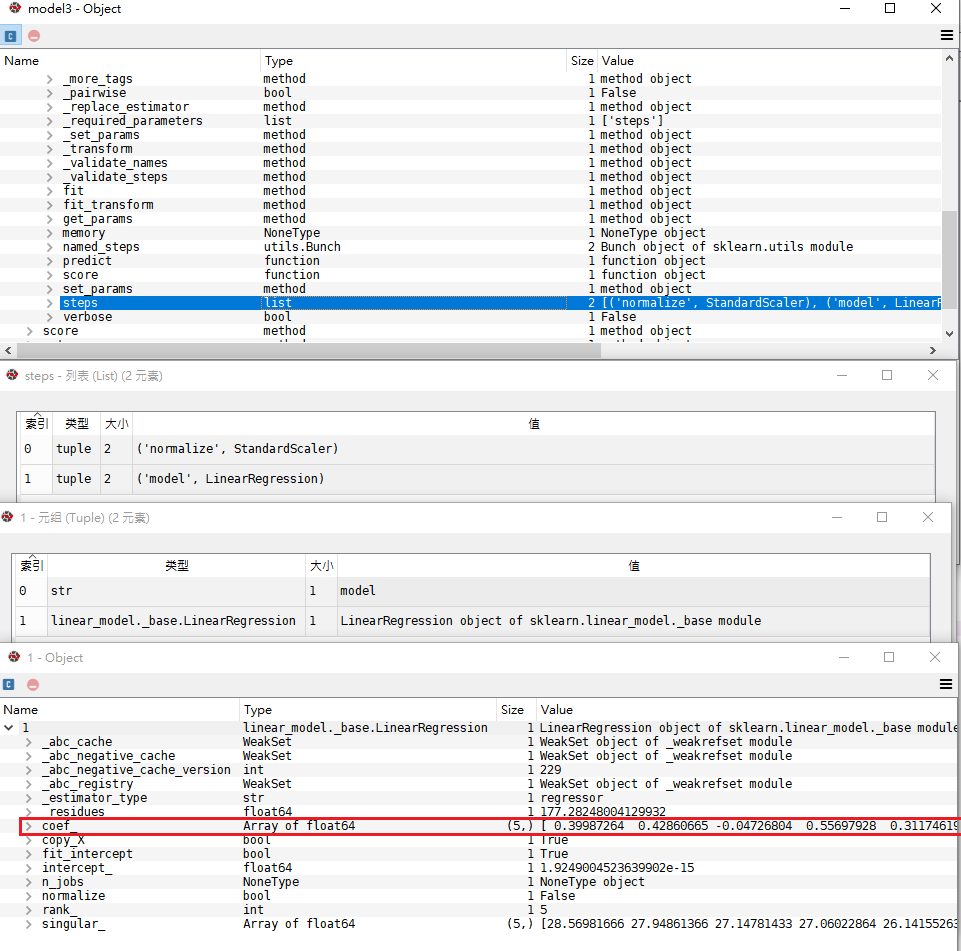
model3內部Pipeline的scaler,與scaler_x對應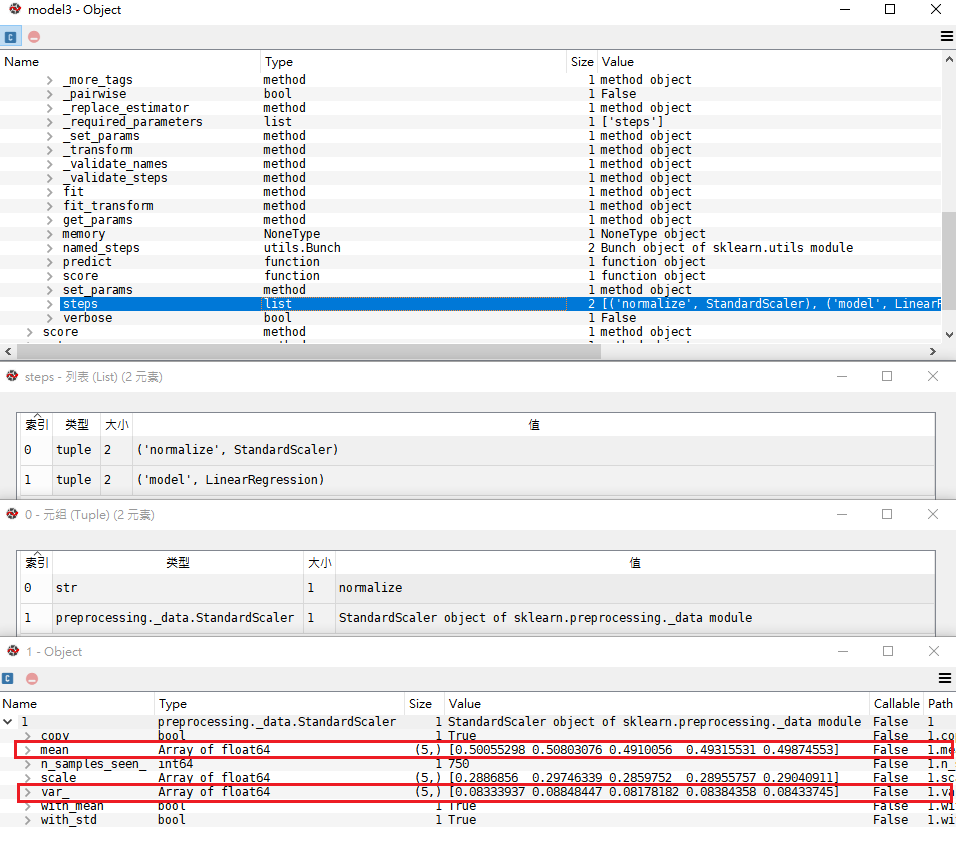
model3的scaler,與scaler_y對應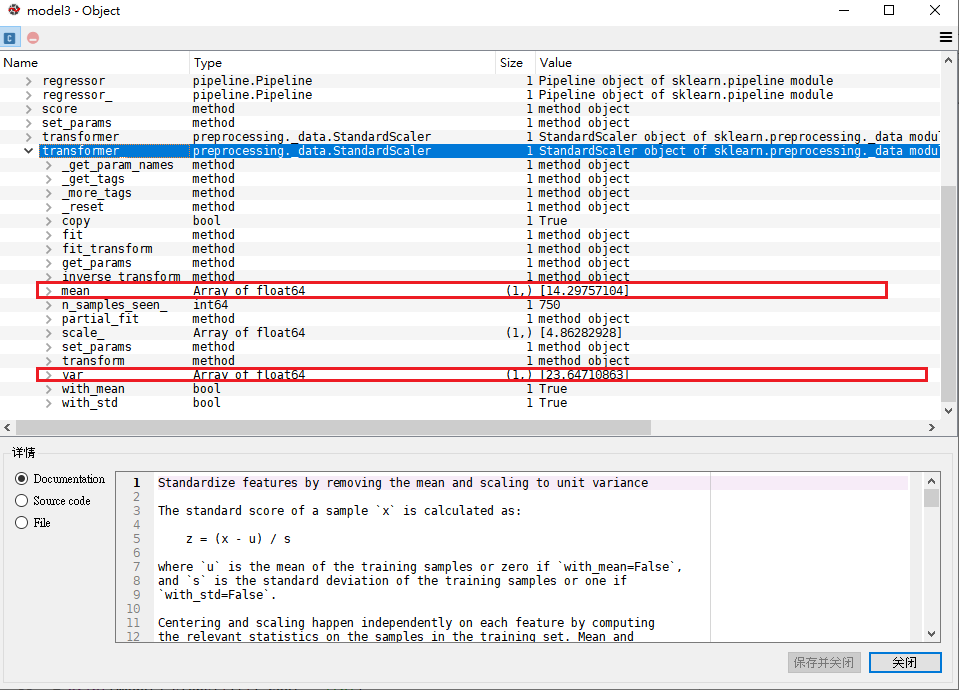
然後就可以將wrapped_model匯出嚕
import joblib
joblib.dump(wrapped_model, 'model.h5')# 匯出
external_model = joblib.load('model.h5')# 匯入
[1] How to Transform Target Variables for Regression in Python
[2] 机器学习】Selecting good features – Part IV: stability selection, RFE and everything side by side
 a26833765
a26833765
