很多演算法在參數計算時,常會使用最小平方法(OLS)或最大概似法(MLE)求解,因此,努力K了一下,把心得記錄下來,希望能與同好分享。
其中,涉及數學證明,希望能以淺顯的角度說明,如不夠精準,還請不吝指正。
最小平方法最常被使用在線性迴歸模型上,以下圖為例: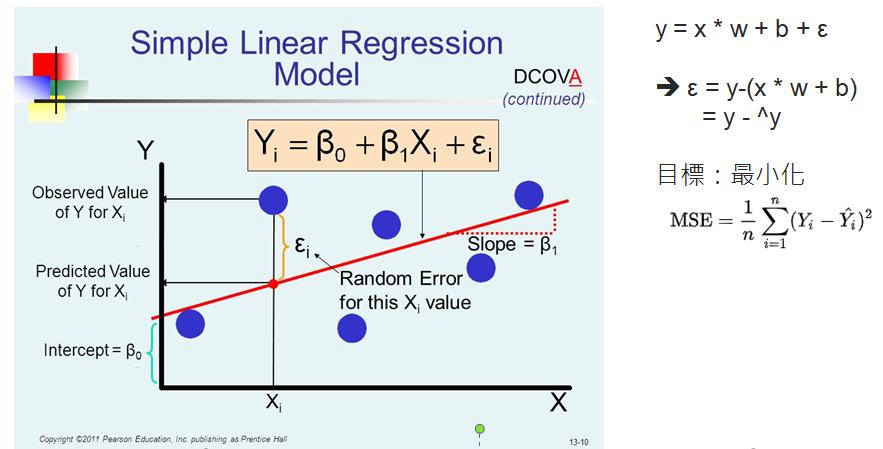
圖片來源:tirthajyoti/Machine-Learning-with-Python
藍色的圓點為實際值,紅色為迴歸線,誤差(ε) = 實際值 - 預測值(迴歸線),我們期望誤差總和越小越好,但為避免正、負誤差抵銷,所以,通常會將誤差取平方和,再除以樣本數,就得到上圖的均方誤差(MSE)公式,我們就稱之為損失函數(Loss Function)、目標函數(Object Function)或成本函數(Cost function)。
假設一個線性模型如下:
可以簡化為:
又因
可進一步簡化為:
迴歸線求解的問題,就可以定義為『在極小化損失函數時,參數 β = ?』。
損失函數 MSE,其中分母n為常數,不影響極小化,故拿掉如下:
簡化為: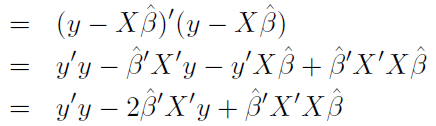
利用微分,一階導數為0時,有最小值: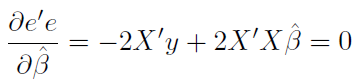
移項後,得到β: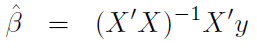
到此,我們就可以利用矩陣計算 β 值了。如要更詳細的推導過程,可參考『這裡』。
import numpy as np
import pandas as pd
from sklearn.datasets import load_boston
# 載入 scikit-learn 內建的房屋估價資料集
boston_dataset = load_boston()
X = boston_dataset.data
# 設定 b 對應的 X,固定為 1
b=np.ones((X.shape[0], 1))
# X 結合 b 對應的 X
X=np.hstack((X, b))
# y 改為二維,以利矩陣運算
y = boston_dataset.target
y = y.reshape((-1, 1))
# 計算 Beta
Beta = np.linalg.inv(X.T @ X) @ X.T @ y
# 計算RMSE, RMSE = MSE 開根號
SSE = ((X @ Beta - y ) ** 2).sum()
MSE = SSE / y.shape[0]
RMSE = MSE ** (1/2)
print(RMSE)
# 計算判定係數
y_mean = y.ravel().mean()
SST = ((y - y_mean) ** 2).sum()
R2 = 1 - (SSE / SST)
print(R2)
使用 scikit-learn 迴歸函數比較。
import numpy as np
import pandas as pd
# 載入 scikit-learn 內建的房屋估價資料集
from sklearn.datasets import load_boston
boston_dataset = load_boston()
X=boston_dataset.data
y = boston_dataset.target
# 計算 Beta
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 訓練模型
lin_model = LinearRegression()
lin_model.fit(X, y)
# 計算RMSE、判定係數
from sklearn.metrics import r2_score
y_predict = lin_model.predict(X)
rmse = (np.sqrt(mean_squared_error(y, y_predict)))
r2 = r2_score(y, y_predict)
print(rmse)
print(r2)
矩陣求解:
RMSE = 4.679191295697281
R2 = 0.7406426641094095
scikit-learn:
RMSE = 4.679191295697282
R2 = 0.7406426641094094
答案很接近,Ya !
最小平方法不只用在迴歸求解,在許多方面也有相當多的應用,尤其是神經網路的梯度下降法,也充分利用此方式求解。
下一篇我們繼續探討『最大概似法(MLE)』。
程式碼可由此下載。
 I code so I am
I code so I am
